 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignPxtr: Aligning Predicted Behavior Distributions for Bias-Free Video Recommendations
Mar 11, 2025In video recommendation systems, user behaviors such as watch time, likes, and follows are commonly used to infer user interest. However, these behaviors are influenced by various biases, including duration bias, demographic biases, and content category biases, which obscure true user preferences. In this paper, we hypothesize that biases and user interest are independent of each other. Based on this assumption, we propose a novel method that aligns predicted behavior distributions across different bias conditions using quantile mapping, theoretically guaranteeing zero mutual information between bias variables and the true user interest. By explicitly modeling the conditional distributions of user behaviors under different biases and mapping these behaviors to quantiles, we effectively decouple user interest from the confounding effects of various biases. Our approach uniquely handles both continuous signals (e.g., watch time) and discrete signals (e.g., likes, comments), while simultaneously addressing multiple bias dimensions. Additionally, we introduce a computationally efficient mean alignment alternative technique for practical real-time inference in large-scale systems. We validate our method through online A/B testing on two major video platforms: Kuaishou Lite and Kuaishou. The results demonstrate significant improvements in user engagement and retention, with \textbf{cumulative lifts of 0.267\% and 0.115\% in active days, and 1.102\% and 0.131\% in average app usage time}, respectively. The results demonstrate that our approach consistently achieves significant improvements in long-term user retention and substantial gains in average app usage time across different platforms. Our core code will be publised at https://github.com/justopit/CQE.
Disentangling the Spatial Structure and Style in Conditional VAE
Oct 29, 2019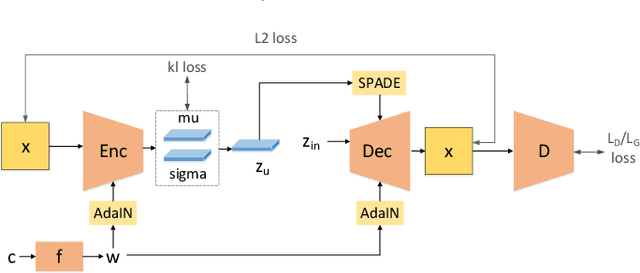


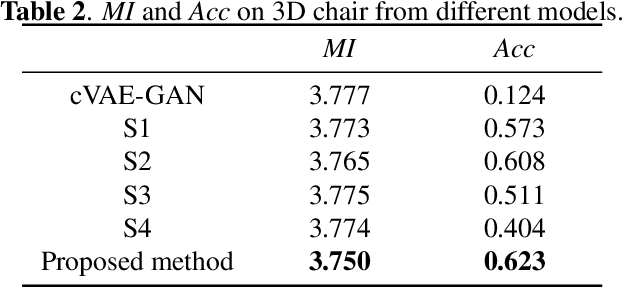
This paper aims to disentangle the latent space in cVAE into the spatial structure and the style code, which are complementary to each other, with one of them $z_s$ being label relevant and the other $z_u$ irrelevant. The generator is built by a connected encoder-decoder and a label condition mapping network. Depending on whether the label is related with the spatial structure, the output $z_s$ from the condition mapping network is used either as a style code or a spatial structure code. The encoder provides the label irrelevant posterior from which $z_u$ is sampled. The decoder employs $z_s$ and $z_u$ in each layer by adaptive normalization like SPADE or AdaIN. Extensive experiments on two datasets with different types of labels show the effectiveness of our method.