 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefineStyle: Dynamic Convolution Refinement for StyleGAN
Oct 08, 2024In StyleGAN, convolution kernels are shaped by both static parameters shared across images and dynamic modulation factors $w^+\in\mathcal{W}^+$ specific to each image. Therefore, $\mathcal{W}^+$ space is often used for image inversion and editing. However, pre-trained model struggles with synthesizing out-of-domain images due to the limited capabilities of $\mathcal{W}^+$ and its resultant kernels, necessitating full fine-tuning or adaptation through a complex hypernetwork. This paper proposes an efficient refining strategy for dynamic kernels. The key idea is to modify kernels by low-rank residuals, learned from input image or domain guidance. These residuals are generated by matrix multiplication between two sets of tokens with the same number, which controls the complexity. We validate the refining scheme in image inversion and domain adaptation. In the former task, we design grouped transformer blocks to learn these token sets by one- or two-stage training. In the latter task, token sets are directly optimized to support synthesis in the target domain while preserving original content. Extensive experiments show that our method achieves low distortions for image inversion and high quality for out-of-domain editing.
QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation
Mar 16, 2022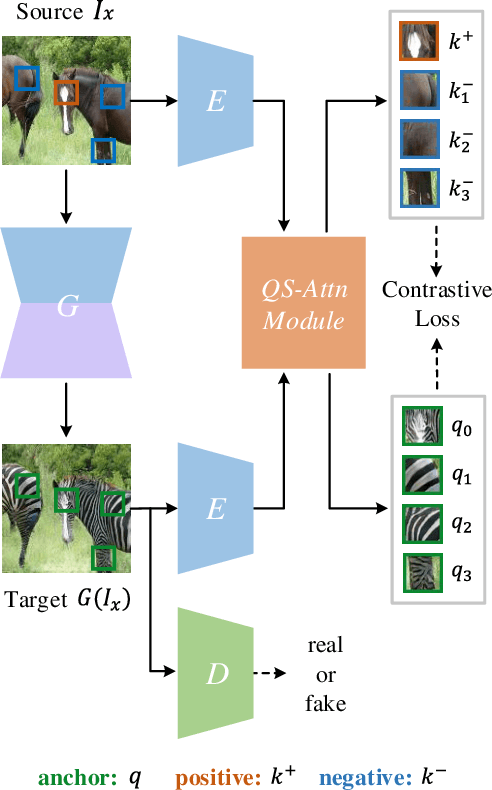
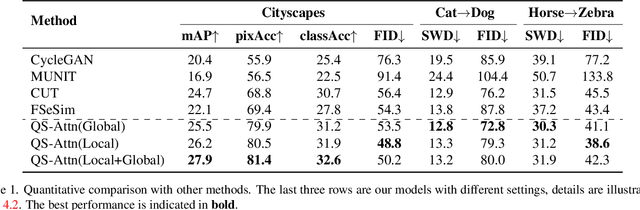

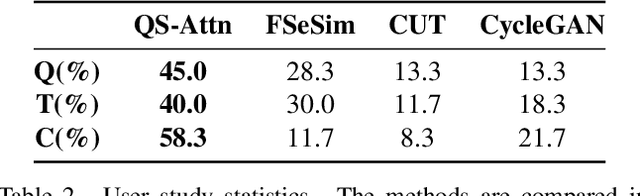
Unpaired image-to-image (I2I) translation often requires to maximize the mutual information between the source and the translated images across different domains, which is critical for the generator to keep the source content and prevent it from unnecessary modifications. The self-supervised contrastive learning has already been successfully applied in the I2I. By constraining features from the same location to be closer than those from different ones, it implicitly ensures the result to take content from the source. However, previous work uses the features from random locations to impose the constraint, which may not be appropriate since some locations contain less information of source domain. Moreover, the feature itself does not reflect the relation with others. This paper deals with these problems by intentionally selecting significant anchor points for contrastive learning. We design a query-selected attention (QS-Attn) module, which compares feature distances in the source domain, giving an attention matrix with a probability distribution in each row. Then we select queries according to their measurement of significance, computed from the distribution. The selected ones are regarded as anchors for contrastive loss. At the same time, the reduced attention matrix is employed to route features in both domains, so that source relations maintain in the synthesis. We validate our proposed method in three different I2I datasets, showing that it increases the image quality without adding learnable parameters.
Style Transformer for Image Inversion and Editing
Mar 15, 2022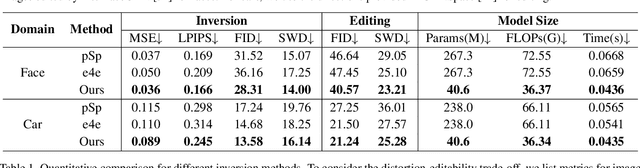
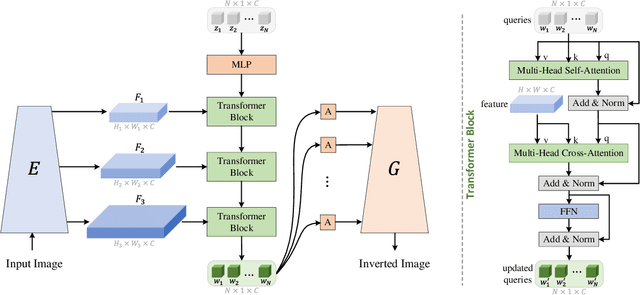
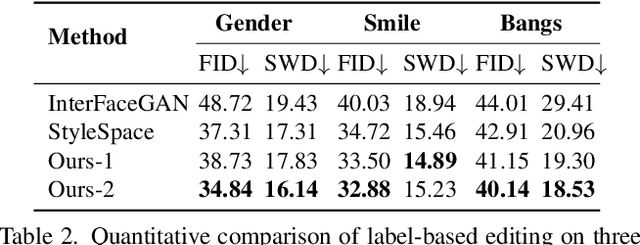
Existing GAN inversion methods fail to provide latent codes for reliable reconstruction and flexible editing simultaneously. This paper presents a transformer-based image inversion and editing model for pretrained StyleGAN which is not only with less distortions, but also of high quality and flexibility for editing. The proposed model employs a CNN encoder to provide multi-scale image features as keys and values. Meanwhile it regards the style code to be determined for different layers of the generator as queries. It first initializes query tokens as learnable parameters and maps them into W+ space. Then the multi-stage alternate self- and cross-attention are utilized, updating queries with the purpose of inverting the input by the generator. Moreover, based on the inverted code, we investigate the reference- and label-based attribute editing through a pretrained latent classifier, and achieve flexible image-to-image translation with high quality results. Extensive experiments are carried out, showing better performances on both inversion and editing tasks within StyleGAN.
Bridging the Gap between Label- and Reference-based Synthesis in Multi-attribute Image-to-Image Translation
Oct 11, 2021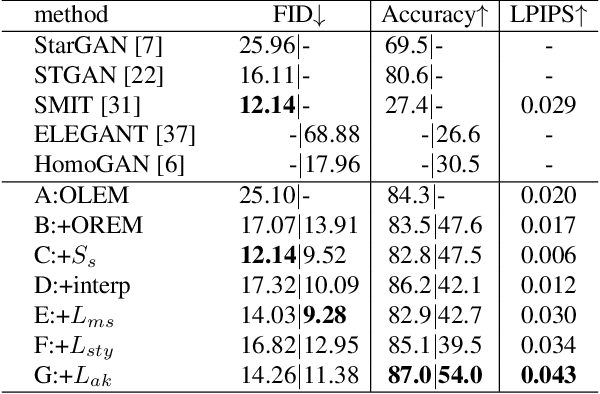
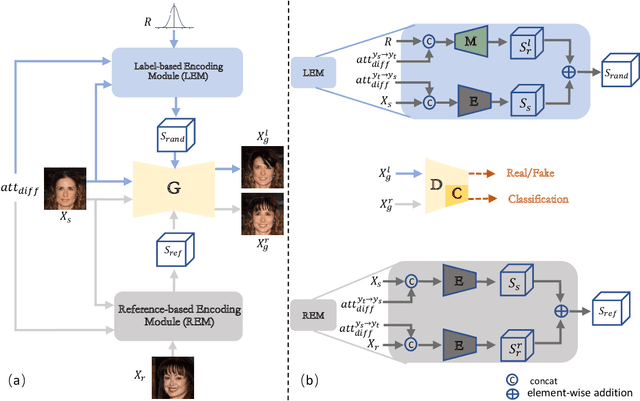


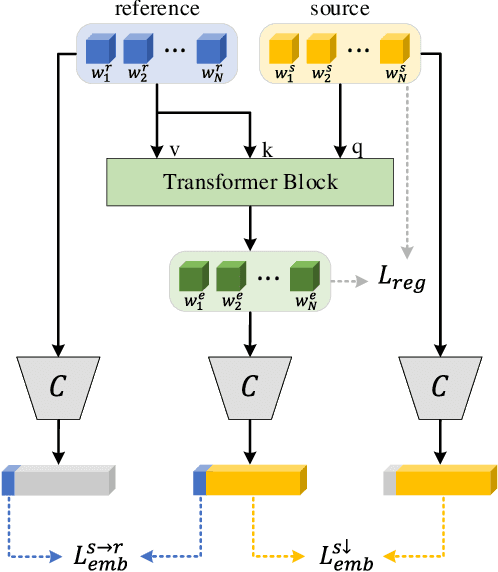
The image-to-image translation (I2IT) model takes a target label or a reference image as the input, and changes a source into the specified target domain. The two types of synthesis, either label- or reference-based, have substantial differences. Particularly, the label-based synthesis reflects the common characteristics of the target domain, and the reference-based shows the specific style similar to the reference. This paper intends to bridge the gap between them in the task of multi-attribute I2IT. We design the label- and reference-based encoding modules (LEM and REM) to compare the domain differences. They first transfer the source image and target label (or reference) into a common embedding space, by providing the opposite directions through the attribute difference vector. Then the two embeddings are simply fused together to form the latent code S_rand (or S_ref), reflecting the domain style differences, which is injected into each layer of the generator by SPADE. To link LEM and REM, so that two types of results benefit each other, we encourage the two latent codes to be close, and set up the cycle consistency between the forward and backward translations on them. Moreover, the interpolation between the S_rand and S_ref is also used to synthesize an extra image. Experiments show that label- and reference-based synthesis are indeed mutually promoted, so that we can have the diverse results from LEM, and high quality results with the similar style of the reference.
LSC-GAN: Latent Style Code Modeling for Continuous Image-to-image Translation
Oct 11, 2021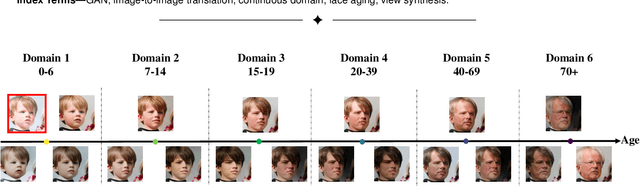

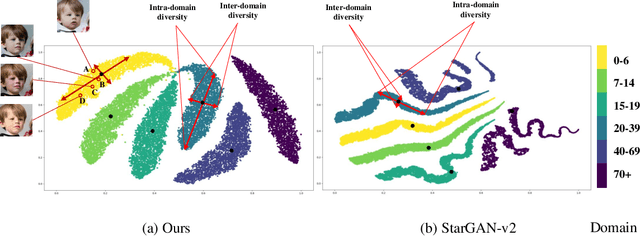
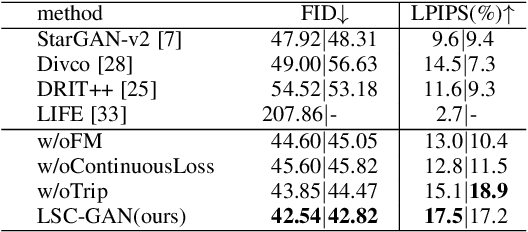
Image-to-image (I2I) translation is usually carried out among discrete domains. However, image domains, often corresponding to a physical value, are usually continuous. In other words, images gradually change with the value, and there exists no obvious gap between different domains. This paper intends to build the model for I2I translation among continuous varying domains. We first divide the whole domain coverage into discrete intervals, and explicitly model the latent style code for the center of each interval. To deal with continuous translation, we design the editing modules, changing the latent style code along two directions. These editing modules help to constrain the codes for domain centers during training, so that the model can better understand the relation among them. To have diverse results, the latent style code is further diversified with either the random noise or features from the reference image, giving the individual style code to the decoder for label-based or reference-based synthesis. Extensive experiments on age and viewing angle translation show that the proposed method can achieve high-quality results, and it is also flexible for users.