 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Image Quality Assessment: Insights, Analysis, and Future Outlook
Feb 12, 2025Image quality assessment (IQA) represents a pivotal challenge in image-focused technologies, significantly influencing the advancement trajectory of image processing and computer vision. Recently, IQA has witnessed a notable surge in innovative research efforts, driven by the emergence of novel architectural paradigms and sophisticated computational techniques. This survey delivers an extensive analysis of contemporary IQA methodologies, organized according to their application scenarios, serving as a beneficial reference for both beginners and experienced researchers. We analyze the advantages and limitations of current approaches and suggest potential future research pathways. The survey encompasses both general and specific IQA methodologies, including conventional statistical measures, machine learning techniques, and cutting-edge deep learning models such as convolutional neural networks (CNNs) and Transformer models. The analysis within this survey highlights the necessity for distortion-specific IQA methods tailored to various application scenarios, emphasizing the significance of practicality, interpretability, and ease of implementation in future developments.
QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation
Mar 16, 2022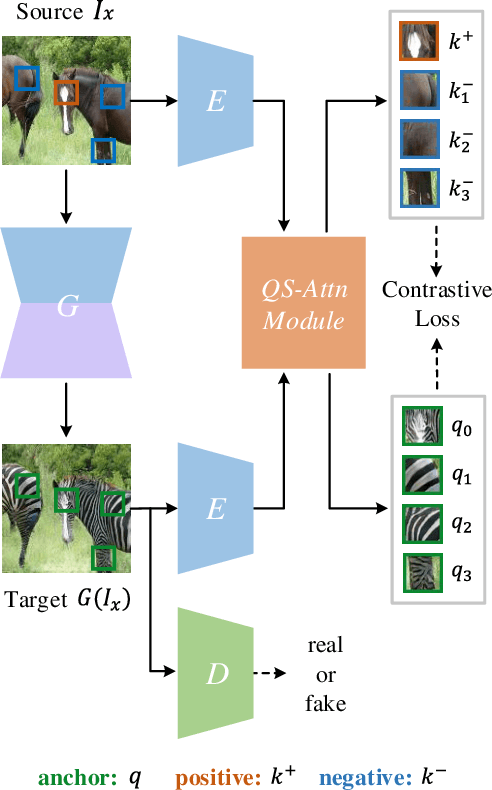
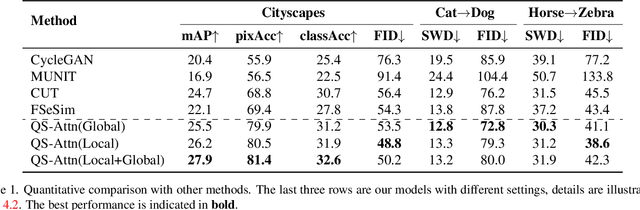

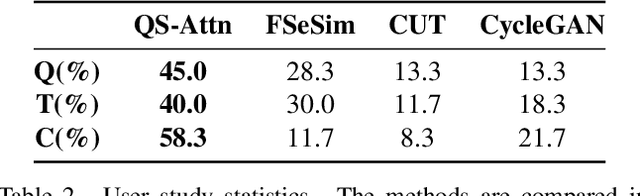
Unpaired image-to-image (I2I) translation often requires to maximize the mutual information between the source and the translated images across different domains, which is critical for the generator to keep the source content and prevent it from unnecessary modifications. The self-supervised contrastive learning has already been successfully applied in the I2I. By constraining features from the same location to be closer than those from different ones, it implicitly ensures the result to take content from the source. However, previous work uses the features from random locations to impose the constraint, which may not be appropriate since some locations contain less information of source domain. Moreover, the feature itself does not reflect the relation with others. This paper deals with these problems by intentionally selecting significant anchor points for contrastive learning. We design a query-selected attention (QS-Attn) module, which compares feature distances in the source domain, giving an attention matrix with a probability distribution in each row. Then we select queries according to their measurement of significance, computed from the distribution. The selected ones are regarded as anchors for contrastive loss. At the same time, the reduced attention matrix is employed to route features in both domains, so that source relations maintain in the synthesis. We validate our proposed method in three different I2I datasets, showing that it increases the image quality without adding learnable parameters.
Style Transformer for Image Inversion and Editing
Mar 15, 2022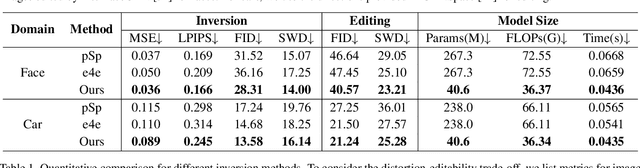
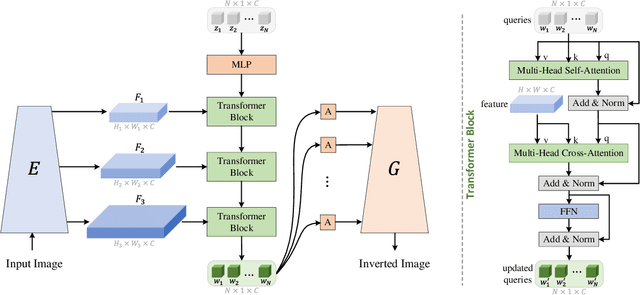
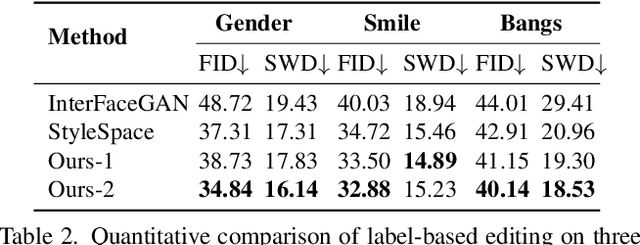
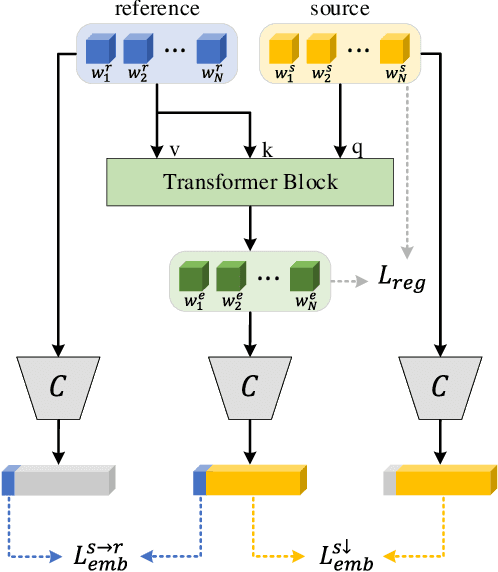
Existing GAN inversion methods fail to provide latent codes for reliable reconstruction and flexible editing simultaneously. This paper presents a transformer-based image inversion and editing model for pretrained StyleGAN which is not only with less distortions, but also of high quality and flexibility for editing. The proposed model employs a CNN encoder to provide multi-scale image features as keys and values. Meanwhile it regards the style code to be determined for different layers of the generator as queries. It first initializes query tokens as learnable parameters and maps them into W+ space. Then the multi-stage alternate self- and cross-attention are utilized, updating queries with the purpose of inverting the input by the generator. Moreover, based on the inverted code, we investigate the reference- and label-based attribute editing through a pretrained latent classifier, and achieve flexible image-to-image translation with high quality results. Extensive experiments are carried out, showing better performances on both inversion and editing tasks within StyleGAN.