 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Suitability of Reinforcement Fine-Tuning to Visual Tasks
Apr 08, 2025
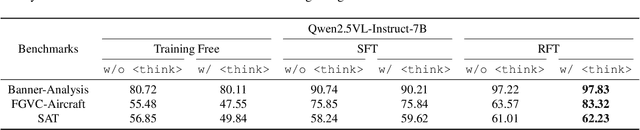
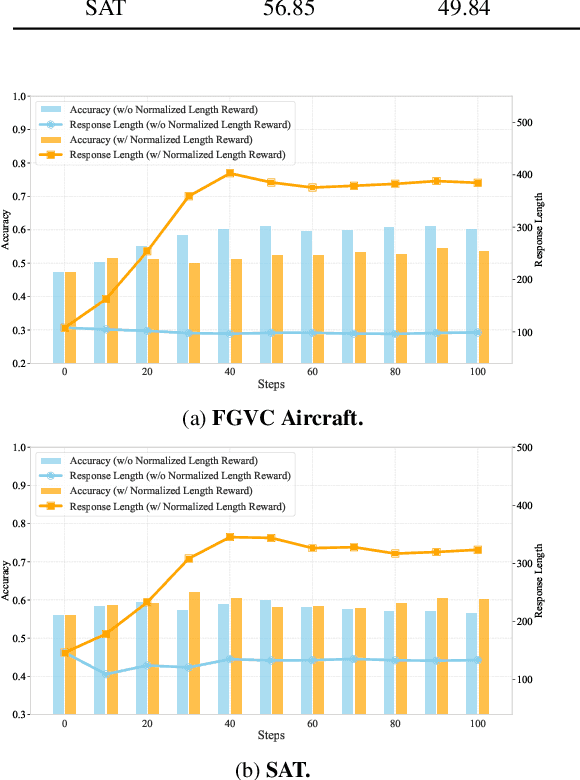
Reinforcement Fine-Tuning (RFT) is proved to be greatly valuable for enhancing the reasoning ability of LLMs. Researchers have been starting to apply RFT to MLLMs, hoping it will also enhance the capabilities of visual understanding. However, these works are at a very early stage and have not examined how suitable RFT actually is for visual tasks. In this work, we endeavor to understand the suitabilities and limitations of RFT for visual tasks, through experimental analysis and observations. We start by quantitative comparisons on various tasks, which shows RFT is generally better than SFT on visual tasks. %especially when the number of training samples are limited. To check whether such advantages are brought up by the reasoning process, we design a new reward that encourages the model to ``think'' more, whose results show more thinking can be beneficial for complicated tasks but harmful for simple tasks. We hope this study can provide more insight for the rapid advancements on this topic.
A Survey on Image Quality Assessment: Insights, Analysis, and Future Outlook
Feb 12, 2025Image quality assessment (IQA) represents a pivotal challenge in image-focused technologies, significantly influencing the advancement trajectory of image processing and computer vision. Recently, IQA has witnessed a notable surge in innovative research efforts, driven by the emergence of novel architectural paradigms and sophisticated computational techniques. This survey delivers an extensive analysis of contemporary IQA methodologies, organized according to their application scenarios, serving as a beneficial reference for both beginners and experienced researchers. We analyze the advantages and limitations of current approaches and suggest potential future research pathways. The survey encompasses both general and specific IQA methodologies, including conventional statistical measures, machine learning techniques, and cutting-edge deep learning models such as convolutional neural networks (CNNs) and Transformer models. The analysis within this survey highlights the necessity for distortion-specific IQA methods tailored to various application scenarios, emphasizing the significance of practicality, interpretability, and ease of implementation in future developments.
Prompt Recursive Search: A Living Framework with Adaptive Growth in LLM Auto-Prompting
Aug 02, 2024



Large Language Models (LLMs) exhibit remarkable proficiency in addressing a diverse array of tasks within the Natural Language Processing (NLP) domain, with various prompt design strategies significantly augmenting their capabilities. However, these prompts, while beneficial, each possess inherent limitations. The primary prompt design methodologies are twofold: The first, exemplified by the Chain of Thought (CoT), involves manually crafting prompts specific to individual datasets, hence termed Expert-Designed Prompts (EDPs). Once these prompts are established, they are unalterable, and their effectiveness is capped by the expertise of the human designers. When applied to LLMs, the static nature of EDPs results in a uniform approach to both simple and complex problems within the same dataset, leading to the inefficient use of tokens for straightforward issues. The second method involves prompts autonomously generated by the LLM, known as LLM-Derived Prompts (LDPs), which provide tailored solutions to specific problems, mitigating the limitations of EDPs. However, LDPs may encounter a decline in performance when tackling complex problems due to the potential for error accumulation during the solution planning process. To address these challenges, we have conceived a novel Prompt Recursive Search (PRS) framework that leverages the LLM to generate solutions specific to the problem, thereby conserving tokens. The framework incorporates an assessment of problem complexity and an adjustable structure, ensuring a reduction in the likelihood of errors. We have substantiated the efficacy of PRS framework through extensive experiments using LLMs with different numbers of parameters across a spectrum of datasets in various domains. Compared to the CoT method, the PRS method has increased the accuracy on the BBH dataset by 8% using Llama3-7B model, achieving a 22% improvement.
WeatherQA: Can Multimodal Language Models Reason about Severe Weather?
Jun 17, 2024



Severe convective weather events, such as hail, tornadoes, and thunderstorms, often occur quickly yet cause significant damage, costing billions of dollars every year. This highlights the importance of forecasting severe weather threats hours in advance to better prepare meteorologists and residents in at-risk areas. Can modern large foundation models perform such forecasting? Existing weather benchmarks typically focus only on predicting time-series changes in certain weather parameters (e.g., temperature, moisture) with text-only features. In this work, we introduce WeatherQA, the first multimodal dataset designed for machines to reason about complex combinations of weather parameters (a.k.a., ingredients) and predict severe weather in real-world scenarios. The dataset includes over 8,000 (multi-images, text) pairs for diverse severe weather events. Each pair contains rich information crucial for forecasting -- the images describe the ingredients capturing environmental instability, surface observations, and radar reflectivity, and the text contains forecast analyses written by human experts. With WeatherQA, we evaluate state-of-the-art vision language models , including GPT4, Claude3, Gemini-1.5, and a fine-tuned Llama3-based VLM, by designing two challenging tasks: (1) multi-choice QA for predicting affected area and (2) classification of the development potential of severe convection. These tasks require deep understanding of domain knowledge (e.g., atmospheric dynamics) and complex reasoning over multimodal data (e.g., interactions between weather parameters). We show a substantial gap between the strongest VLM, GPT4o, and human reasoning. Our comprehensive case study with meteorologists further reveals the weaknesses of the models, suggesting that better training and data integration are necessary to bridge this gap. WeatherQA link: https://github.com/chengqianma/WeatherQA.
Weather Prediction with Diffusion Guided by Realistic Forecast Processes
Feb 06, 2024Weather forecasting remains a crucial yet challenging domain, where recently developed models based on deep learning (DL) have approached the performance of traditional numerical weather prediction (NWP) models. However, these DL models, often complex and resource-intensive, face limitations in flexibility post-training and in incorporating NWP predictions, leading to reliability concerns due to potential unphysical predictions. In response, we introduce a novel method that applies diffusion models (DM) for weather forecasting. In particular, our method can achieve both direct and iterative forecasting with the same modeling framework. Our model is not only capable of generating forecasts independently but also uniquely allows for the integration of NWP predictions, even with varying lead times, during its sampling process. The flexibility and controllability of our model empowers a more trustworthy DL system for the general weather community. Additionally, incorporating persistence and climatology data further enhances our model's long-term forecasting stability. Our empirical findings demonstrate the feasibility and generalizability of this approach, suggesting a promising direction for future, more sophisticated diffusion models without the need for retraining.
From Classification to Clinical Insights: Towards Analyzing and Reasoning About Mobile and Behavioral Health Data With Large Language Models
Nov 25, 2023Passively collected behavioral health data from ubiquitous sensors holds significant promise to provide mental health professionals insights from patient's daily lives; however, developing analysis tools to use this data in clinical practice requires addressing challenges of generalization across devices and weak or ambiguous correlations between the measured signals and an individual's mental health. To address these challenges, we take a novel approach that leverages large language models (LLMs) to synthesize clinically useful insights from multi-sensor data. We develop chain of thought prompting methods that use LLMs to generate reasoning about how trends in data such as step count and sleep relate to conditions like depression and anxiety. We first demonstrate binary depression classification with LLMs achieving accuracies of 61.1% which exceed the state of the art. While it is not robust for clinical use, this leads us to our key finding: even more impactful and valued than classification is a new human-AI collaboration approach in which clinician experts interactively query these tools and combine their domain expertise and context about the patient with AI generated reasoning to support clinical decision-making. We find models like GPT-4 correctly reference numerical data 75% of the time, and clinician participants express strong interest in using this approach to interpret self-tracking data.
BigSmall: Efficient Multi-Task Learning for Disparate Spatial and Temporal Physiological Measurements
Mar 21, 2023Understanding of human visual perception has historically inspired the design of computer vision architectures. As an example, perception occurs at different scales both spatially and temporally, suggesting that the extraction of salient visual information may be made more effective by paying attention to specific features at varying scales. Visual changes in the body due to physiological processes also occur at different scales and with modality-specific characteristic properties. Inspired by this, we present BigSmall, an efficient architecture for physiological and behavioral measurement. We present the first joint camera-based facial action, cardiac, and pulmonary measurement model. We propose a multi-branch network with wrapping temporal shift modules that yields both accuracy and efficiency gains. We observe that fusing low-level features leads to suboptimal performance, but that fusing high level features enables efficiency gains with negligible loss in accuracy. Experimental results demonstrate that BigSmall significantly reduces the computational costs. Furthermore, compared to existing task-specific models, BigSmall achieves comparable or better results on multiple physiological measurement tasks simultaneously with a unified model.
Rate-Perception Optimized Preprocessing for Video Coding
Jan 25, 2023In the past decades, lots of progress have been done in the video compression field including traditional video codec and learning-based video codec. However, few studies focus on using preprocessing techniques to improve the rate-distortion performance. In this paper, we propose a rate-perception optimized preprocessing (RPP) method. We first introduce an adaptive Discrete Cosine Transform loss function which can save the bitrate and keep essential high frequency components as well. Furthermore, we also combine several state-of-the-art techniques from low-level vision fields into our approach, such as the high-order degradation model, efficient lightweight network design, and Image Quality Assessment model. By jointly using these powerful techniques, our RPP approach can achieve on average, 16.27% bitrate saving with different video encoders like AVC, HEVC, and VVC under multiple quality metrics. In the deployment stage, our RPP method is very simple and efficient which is not required any changes in the setting of video encoding, streaming, and decoding. Each input frame only needs to make a single pass through RPP before sending into video encoders. In addition, in our subjective visual quality test, 87% of users think videos with RPP are better or equal to videos by only using the codec to compress, while these videos with RPP save about 12% bitrate on average. Our RPP framework has been integrated into the production environment of our video transcoding services which serve millions of users every day.
Automated Backend-Aware Post-Training Quantization
Mar 27, 2021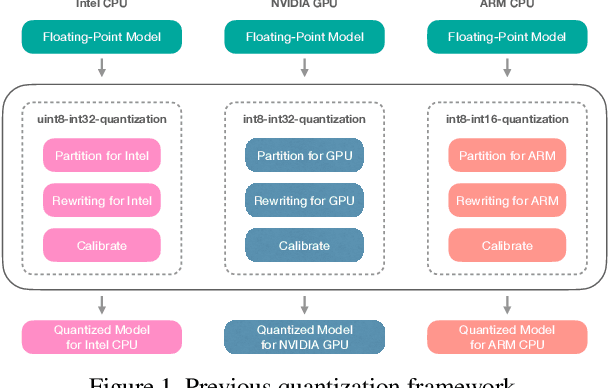
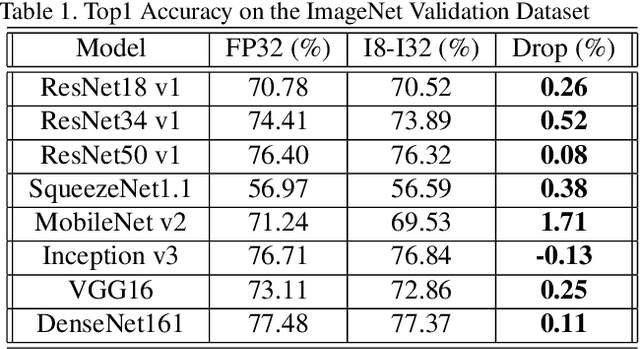
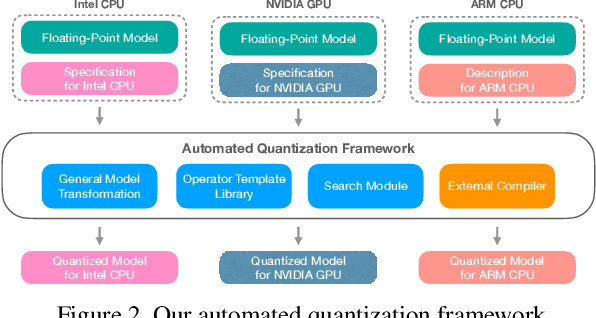
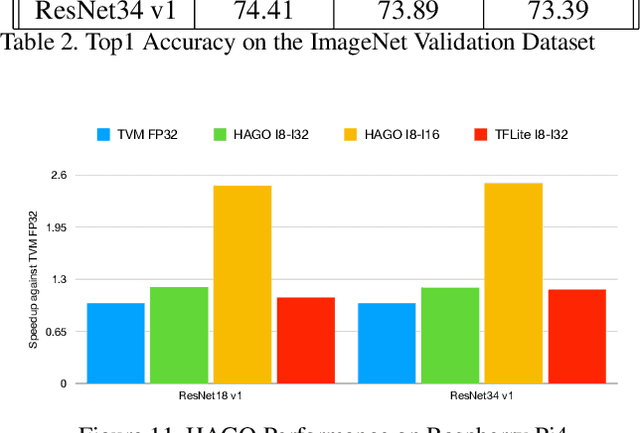
Quantization is a key technique to reduce the resource requirement and improve the performance of neural network deployment. However, different hardware backends such as x86 CPU, NVIDIA GPU, ARM CPU, and accelerators may demand different implementations for quantized networks. This diversity calls for specialized post-training quantization pipelines to built for each hardware target, an engineering effort that is often too large for developers to keep up with. We tackle this problem with an automated post-training quantization framework called HAGO. HAGO provides a set of general quantization graph transformations based on a user-defined hardware specification and implements a search mechanism to find the optimal quantization strategy while satisfying hardware constraints for any model. We observe that HAGO achieves speedups of 2.09x, 1.97x, and 2.48x on Intel Xeon Cascade Lake CPUs, NVIDIA Tesla T4 GPUs, ARM Cortex-A CPUs on Raspberry Pi4 relative to full precision respectively, while maintaining the highest reported post-training quantization accuracy in each case.
IA-MOT: Instance-Aware Multi-Object Tracking with Motion Consistency
Jun 24, 2020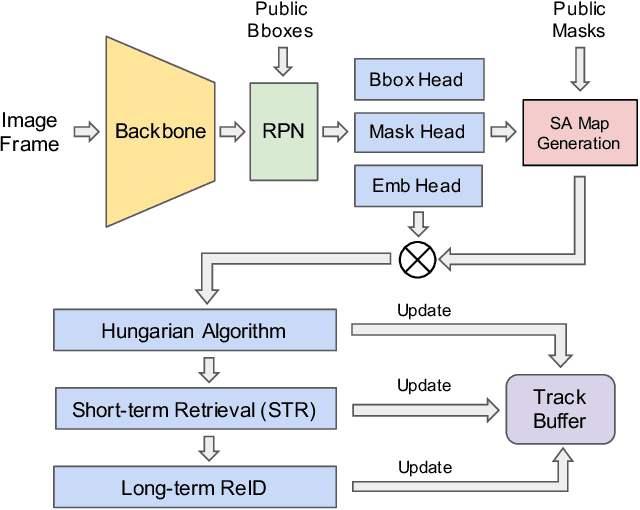
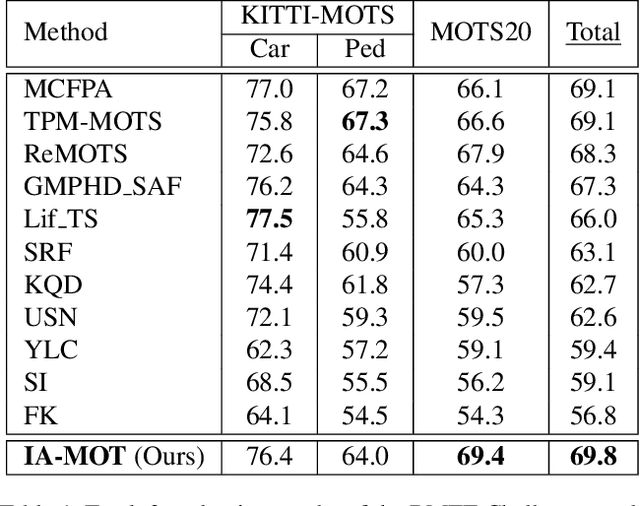

Multiple object tracking (MOT) is a crucial task in computer vision society. However, most tracking-by-detection MOT methods, with available detected bounding boxes, cannot effectively handle static, slow-moving and fast-moving camera scenarios simultaneously due to ego-motion and frequent occlusion. In this work, we propose a novel tracking framework, called "instance-aware MOT" (IA-MOT), that can track multiple objects in either static or moving cameras by jointly considering the instance-level features and object motions. First, robust appearance features are extracted from a variant of Mask R-CNN detector with an additional embedding head, by sending the given detections as the region proposals. Meanwhile, the spatial attention, which focuses on the foreground within the bounding boxes, is generated from the given instance masks and applied to the extracted embedding features. In the tracking stage, object instance masks are aligned by feature similarity and motion consistency using the Hungarian association algorithm. Moreover, object re-identification (ReID) is incorporated to recover ID switches caused by long-term occlusion or missing detection. Overall, when evaluated on the MOTS20 and KITTI-MOTS dataset, our proposed method won the first place in Track 3 of the BMTT Challenge in CVPR2020 workshops.