 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSORCE: Small Object Retrieval in Complex Environments
May 30, 2025Text-to-Image Retrieval (T2IR) is a highly valuable task that aims to match a given textual query to images in a gallery. Existing benchmarks primarily focus on textual queries describing overall image semantics or foreground salient objects, possibly overlooking inconspicuous small objects, especially in complex environments. Such small object retrieval is crucial, as in real-world applications, the targets of interest are not always prominent in the image. Thus, we introduce SORCE (Small Object Retrieval in Complex Environments), a new subfield of T2IR, focusing on retrieving small objects in complex images with textual queries. We propose a new benchmark, SORCE-1K, consisting of images with complex environments and textual queries describing less conspicuous small objects with minimal contextual cues from other salient objects. Preliminary analysis on SORCE-1K finds that existing T2IR methods struggle to capture small objects and encode all the semantics into a single embedding, leading to poor retrieval performance on SORCE-1K. Therefore, we propose to represent each image with multiple distinctive embeddings. We leverage Multimodal Large Language Models (MLLMs) to extract multiple embeddings for each image instructed by a set of Regional Prompts (ReP). Experimental results show that our multi-embedding approach through MLLM and ReP significantly outperforms existing T2IR methods on SORCE-1K. Our experiments validate the effectiveness of SORCE-1K for benchmarking SORCE performances, highlighting the potential of multi-embedding representation and text-customized MLLM features for addressing this task.
On the Suitability of Reinforcement Fine-Tuning to Visual Tasks
Apr 08, 2025
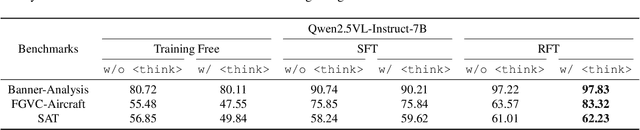
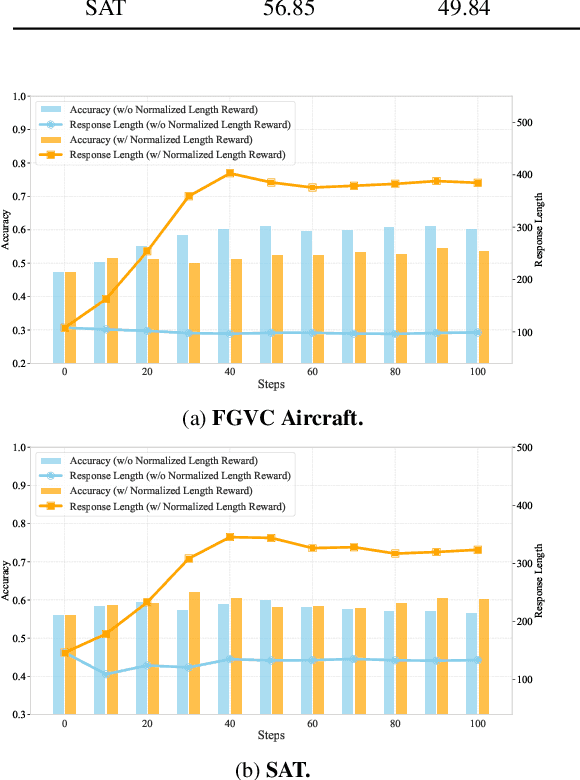
Reinforcement Fine-Tuning (RFT) is proved to be greatly valuable for enhancing the reasoning ability of LLMs. Researchers have been starting to apply RFT to MLLMs, hoping it will also enhance the capabilities of visual understanding. However, these works are at a very early stage and have not examined how suitable RFT actually is for visual tasks. In this work, we endeavor to understand the suitabilities and limitations of RFT for visual tasks, through experimental analysis and observations. We start by quantitative comparisons on various tasks, which shows RFT is generally better than SFT on visual tasks. %especially when the number of training samples are limited. To check whether such advantages are brought up by the reasoning process, we design a new reward that encourages the model to ``think'' more, whose results show more thinking can be beneficial for complicated tasks but harmful for simple tasks. We hope this study can provide more insight for the rapid advancements on this topic.
History-Aware Transformation of ReID Features for Multiple Object Tracking
Mar 16, 2025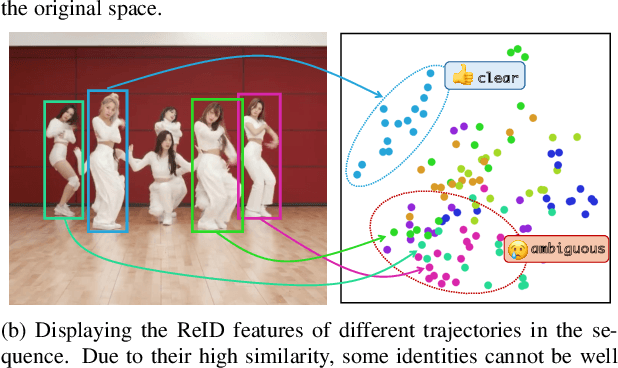
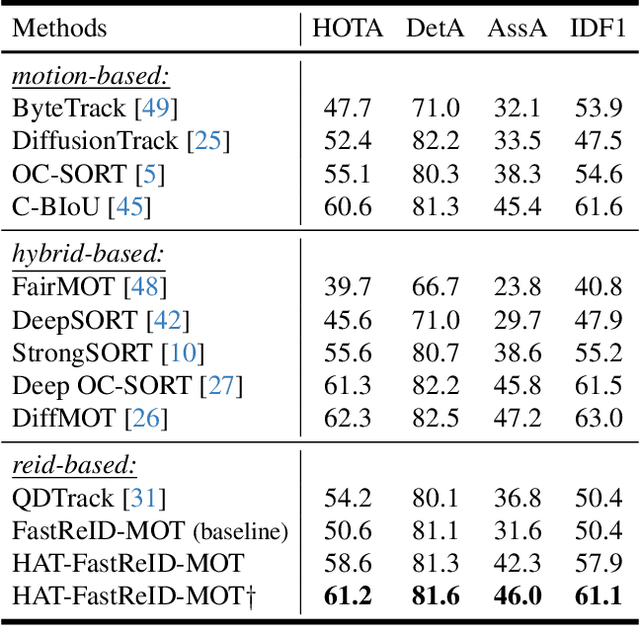
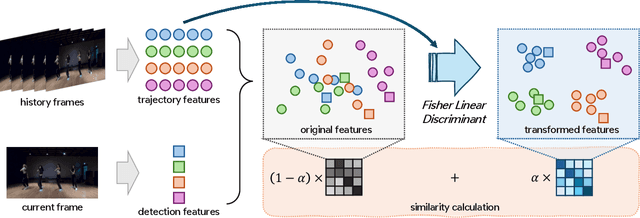
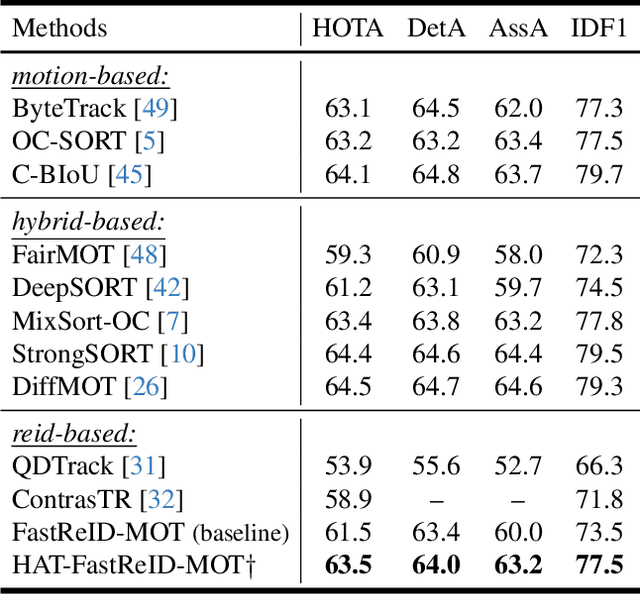
The aim of multiple object tracking (MOT) is to detect all objects in a video and bind them into multiple trajectories. Generally, this process is carried out in two steps: detecting objects and associating them across frames based on various cues and metrics. Many studies and applications adopt object appearance, also known as re-identification (ReID) features, for target matching through straightforward similarity calculation. However, we argue that this practice is overly naive and thus overlooks the unique characteristics of MOT tasks. Unlike regular re-identification tasks that strive to distinguish all potential targets in a general representation, multi-object tracking typically immerses itself in differentiating similar targets within the same video sequence. Therefore, we believe that seeking a more suitable feature representation space based on the different sample distributions of each sequence will enhance tracking performance. In this paper, we propose using history-aware transformations on ReID features to achieve more discriminative appearance representations. Specifically, we treat historical trajectory features as conditions and employ a tailored Fisher Linear Discriminant (FLD) to find a spatial projection matrix that maximizes the differentiation between different trajectories. Our extensive experiments reveal that this training-free projection can significantly boost feature-only trackers to achieve competitive, even superior tracking performance compared to state-of-the-art methods while also demonstrating impressive zero-shot transfer capabilities. This demonstrates the effectiveness of our proposal and further encourages future investigation into the importance and customization of ReID models in multiple object tracking. The code will be released at https://github.com/HELLORPG/HATReID-MOT.
VFIMamba: Video Frame Interpolation with State Space Models
Jul 02, 2024Inter-frame modeling is pivotal in generating intermediate frames for video frame interpolation (VFI). Current approaches predominantly rely on convolution or attention-based models, which often either lack sufficient receptive fields or entail significant computational overheads. Recently, Selective State Space Models (S6) have emerged, tailored specifically for long sequence modeling, offering both linear complexity and data-dependent modeling capabilities. In this paper, we propose VFIMamba, a novel frame interpolation method for efficient and dynamic inter-frame modeling by harnessing the S6 model. Our approach introduces the Mixed-SSM Block (MSB), which initially rearranges tokens from adjacent frames in an interleaved fashion and subsequently applies multi-directional S6 modeling. This design facilitates the efficient transmission of information across frames while upholding linear complexity. Furthermore, we introduce a novel curriculum learning strategy that progressively cultivates proficiency in modeling inter-frame dynamics across varying motion magnitudes, fully unleashing the potential of the S6 model. Experimental findings showcase that our method attains state-of-the-art performance across diverse benchmarks, particularly excelling in high-resolution scenarios. In particular, on the X-TEST dataset, VFIMamba demonstrates a noteworthy improvement of 0.80 dB for 4K frames and 0.96 dB for 2K frames.
Sparse Global Matching for Video Frame Interpolation with Large Motion
Apr 15, 2024



Large motion poses a critical challenge in Video Frame Interpolation (VFI) task. Existing methods are often constrained by limited receptive fields, resulting in sub-optimal performance when handling scenarios with large motion. In this paper, we introduce a new pipeline for VFI, which can effectively integrate global-level information to alleviate issues associated with large motion. Specifically, we first estimate a pair of initial intermediate flows using a high-resolution feature map for extracting local details. Then, we incorporate a sparse global matching branch to compensate for flow estimation, which consists of identifying flaws in initial flows and generating sparse flow compensation with a global receptive field. Finally, we adaptively merge the initial flow estimation with global flow compensation, yielding a more accurate intermediate flow. To evaluate the effectiveness of our method in handling large motion, we carefully curate a more challenging subset from commonly used benchmarks. Our method demonstrates the state-of-the-art performance on these VFI subsets with large motion.
APP-Net: Auxiliary-point-based Push and Pull Operations for Efficient Point Cloud Classification
May 02, 2022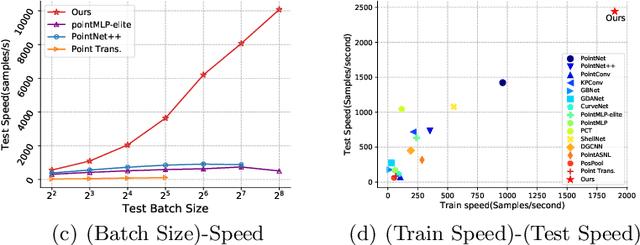
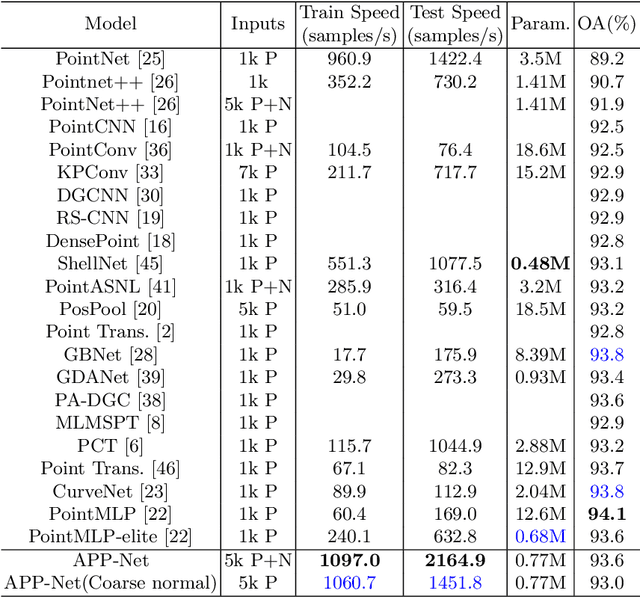
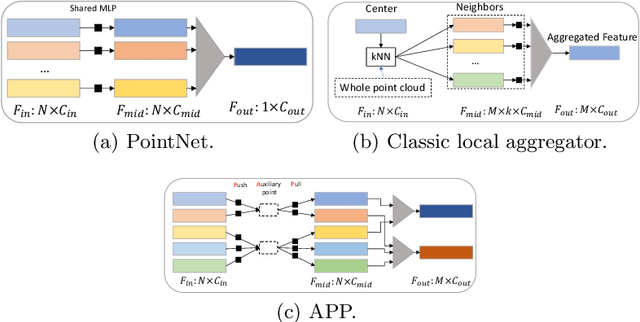
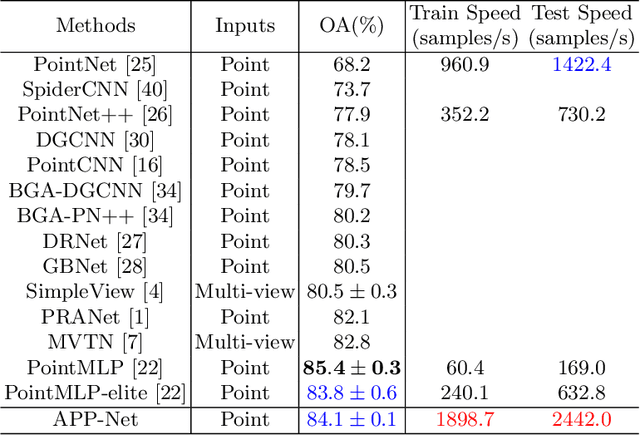
Point-cloud-based 3D classification task involves aggregating features from neighbor points. In previous works, each source point is often selected as a neighbor by multiple center points. Thus each source point has to participate in calculation multiple times with high memory consumption. Meanwhile, to pursue higher accuracy, these methods rely on a complex local aggregator to extract fine geometric representation, which slows down the network. To address these issues, we propose a new local aggregator of linear complexity, coined as APP. Specifically, we introduce an auxiliary container as an anchor to exchange features between the source point and the aggregating center. Each source point pushes its feature to only one auxiliary container, and each center point pulls features from only one auxiliary container. This avoids the re-computation of each source point. To facilitate the learning of the local structure, we use an online normal estimation module to provide the explainable geometric information to enhance our APP modeling capability. The constructed network is more efficient than all the previous baselines with a clear margin while only occupying a low memory. Experiments on both synthetic and real datasets verify that APP-Net reaches comparable accuracies with other networks. We will release the complete code to help others reproduce the APP-Net.