 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAT: Pruning-Aware Tuning for Large Language Models
Aug 27, 2024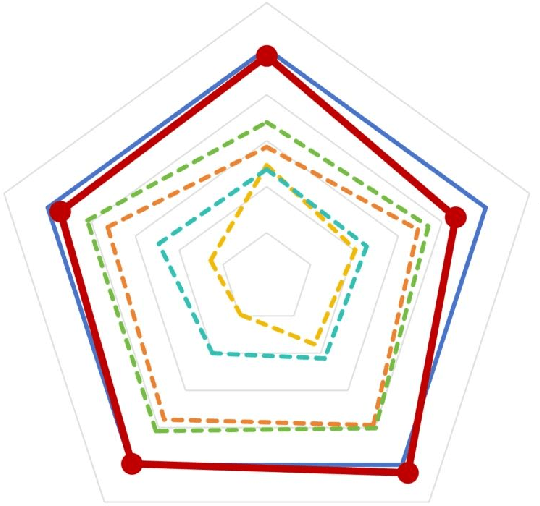
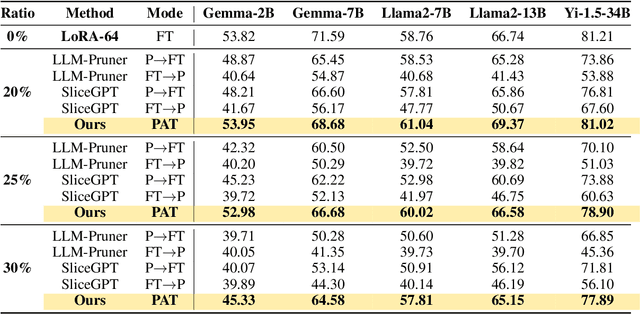
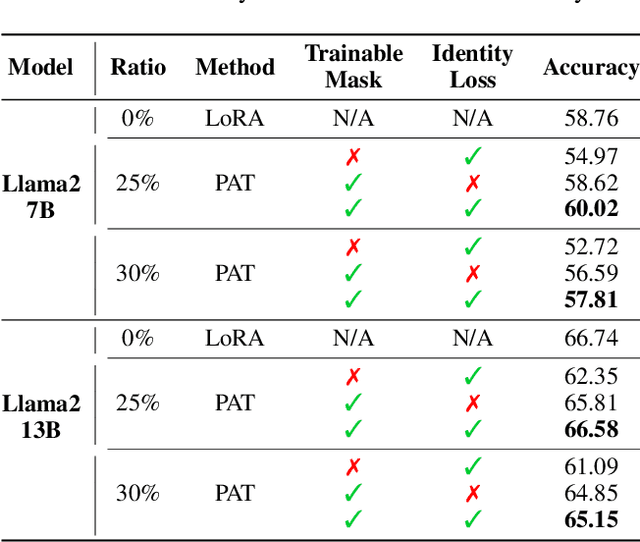
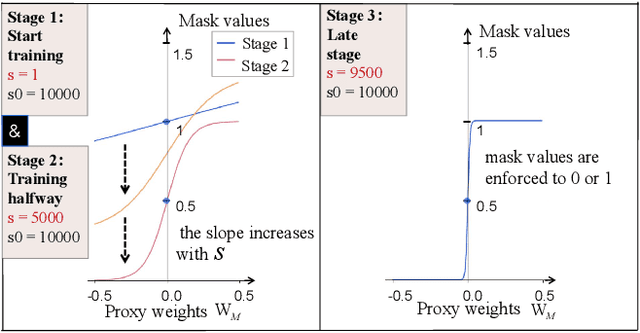
Large language models (LLMs) excel in language tasks, especially with supervised fine-tuning after pre-training. However, their substantial memory and computational requirements hinder practical applications. Structural pruning, which reduces less significant weight dimensions, is one solution. Yet, traditional post-hoc pruning often leads to significant performance loss, with limited recovery from further fine-tuning due to reduced capacity. Since the model fine-tuning refines the general and chaotic knowledge in pre-trained models, we aim to incorporate structural pruning with the fine-tuning, and propose the Pruning-Aware Tuning (PAT) paradigm to eliminate model redundancy while preserving the model performance to the maximum extend. Specifically, we insert the innovative Hybrid Sparsification Modules (HSMs) between the Attention and FFN components to accordingly sparsify the upstream and downstream linear modules. The HSM comprises a lightweight operator and a globally shared trainable mask. The lightweight operator maintains a training overhead comparable to that of LoRA, while the trainable mask unifies the channels to be sparsified, ensuring structural pruning. Additionally, we propose the Identity Loss which decouples the transformation and scaling properties of the HSMs to enhance training robustness. Extensive experiments demonstrate that PAT excels in both performance and efficiency. For example, our Llama2-7b model with a 25\% pruning ratio achieves 1.33$\times$ speedup while outperforming the LoRA-finetuned model by up to 1.26\% in accuracy with a similar training cost. Code: https://github.com/kriskrisliu/PAT_Pruning-Aware-Tuning
O-PRESS: Boosting OCT axial resolution with Prior guidance, Recurrence, and Equivariant Self-Supervision
Jan 06, 2024



Optical coherence tomography (OCT) is a noninvasive technology that enables real-time imaging of tissue microanatomies. The axial resolution of OCT is intrinsically constrained by the spectral bandwidth of the employed light source while maintaining a fixed center wavelength for a specific application. Physically extending this bandwidth faces strong limitations and requires a substantial cost. We present a novel computational approach, called as O-PRESS, for boosting the axial resolution of OCT with Prior Guidance, a Recurrent mechanism, and Equivariant Self-Supervision. Diverging from conventional superresolution methods that rely on physical models or data-driven techniques, our method seamlessly integrates OCT modeling and deep learning, enabling us to achieve real-time axial-resolution enhancement exclusively from measurements without a need for paired images. Our approach solves two primary tasks of resolution enhancement and noise reduction with one treatment. Both tasks are executed in a self-supervised manner, with equivariance imaging and free space priors guiding their respective processes. Experimental evaluations, encompassing both quantitative metrics and visual assessments, consistently verify the efficacy and superiority of our approach, which exhibits performance on par with fully supervised methods. Importantly, the robustness of our model is affirmed, showcasing its dual capability to enhance axial resolution while concurrently improving the signal-to-noise ratio.
Cross-domain Collaborative Learning for Recognizing Multiple Retinal Diseases from Wide-Field Fundus Images
May 14, 2023This paper addresses the emerging task of recognizing multiple retinal diseases from wide-field (WF) and ultra-wide-field (UWF) fundus images. For an effective reuse of existing labeled color fundus photo (CFP) data, we propose Cross-domain Collaborative Learning (CdCL). Inspired by the success of fixed-ratio based mixup in unsupervised domain adaptation, we re-purpose this strategy for the current task. Due to the intrinsic disparity between the field-of-view of CFP and WF/UWF images, a scale bias naturally exists in a mixup sample that the anatomic structure from a CFP image will be considerably larger than its WF/UWF counterpart. The CdCL method resolves the issue by Scale-bias Correction, which employs Transformers for producing scale-invariant features. As demonstrated by extensive experiments on multiple datasets covering both WF and UWF images, the proposed method compares favorably against a number of competitive baselines.
Dynamic Video Frame Interpolation with integrated Difficulty Pre-Assessment
Apr 25, 2023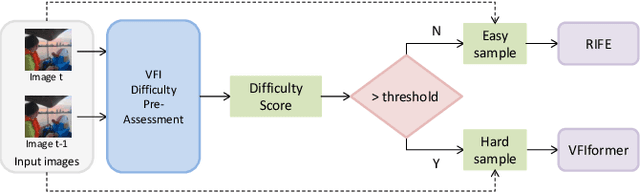
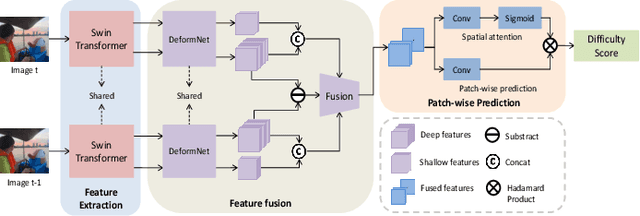
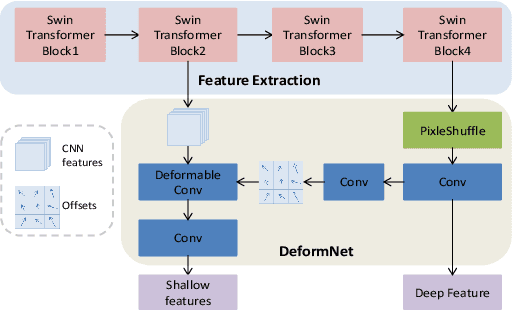
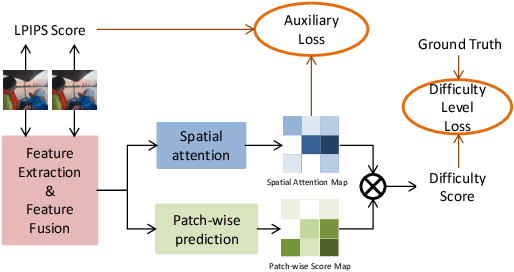
Video frame interpolation(VFI) has witnessed great progress in recent years. While existing VFI models still struggle to achieve a good trade-off between accuracy and efficiency: fast models often have inferior accuracy; accurate models typically run slowly. However, easy samples with small motion or clear texture can achieve competitive results with simple models and do not require heavy computation. In this paper, we present an integrated pipeline which combines difficulty assessment with video frame interpolation. Specifically, it firstly leverages a pre-assessment model to measure the interpolation difficulty level of input frames, and then dynamically selects an appropriate VFI model to generate interpolation results. Furthermore, a large-scale VFI difficulty assessment dataset is collected and annotated to train our pre-assessment model. Extensive experiments show that easy samples pass through fast models while difficult samples inference with heavy models, and our proposed pipeline can improve the accuracy-efficiency trade-off for VFI.
Extracting Motion and Appearance via Inter-Frame Attention for Efficient Video Frame Interpolation
Mar 05, 2023Effectively extracting inter-frame motion and appearance information is important for video frame interpolation (VFI). Previous works either extract both types of information in a mixed way or elaborate separate modules for each type of information, which lead to representation ambiguity and low efficiency. In this paper, we propose a novel module to explicitly extract motion and appearance information via a unifying operation. Specifically, we rethink the information process in inter-frame attention and reuse its attention map for both appearance feature enhancement and motion information extraction. Furthermore, for efficient VFI, our proposed module could be seamlessly integrated into a hybrid CNN and Transformer architecture. This hybrid pipeline can alleviate the computational complexity of inter-frame attention as well as preserve detailed low-level structure information. Experimental results demonstrate that, for both fixed- and arbitrary-timestep interpolation, our method achieves state-of-the-art performance on various datasets. Meanwhile, our approach enjoys a lighter computation overhead over models with close performance. The source code and models are available at https://github.com/MCG-NJU/EMA-VFI.
A Unified Pyramid Recurrent Network for Video Frame Interpolation
Nov 07, 2022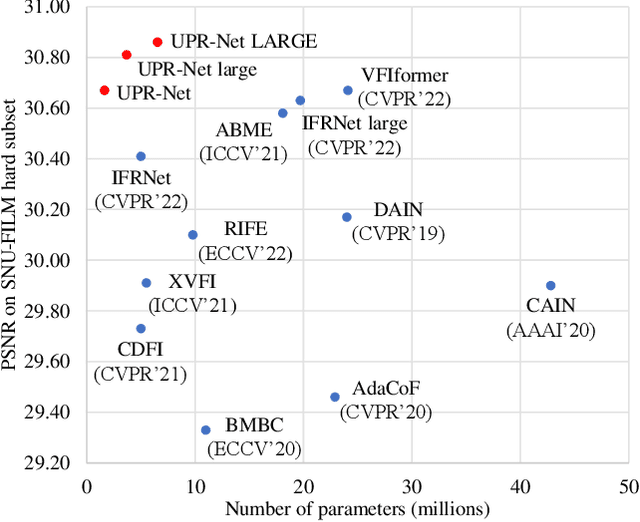
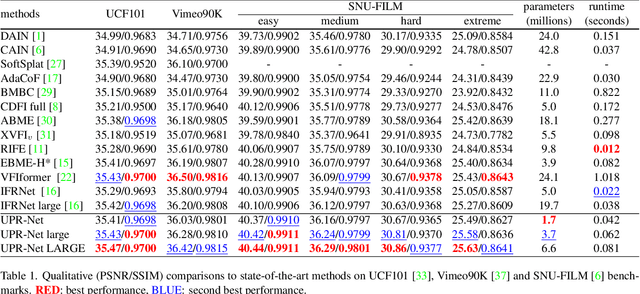
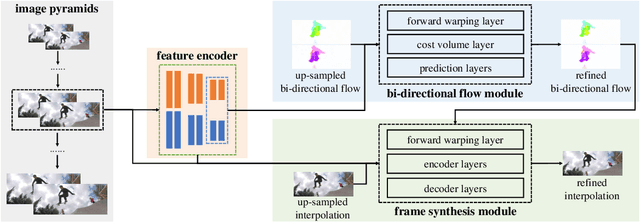
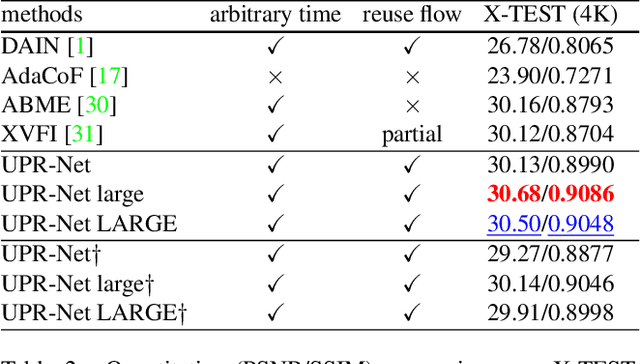
Flow-guide synthesis provides a common framework for frame interpolation, where optical flow is typically estimated by a pyramid network, and then leveraged to guide a synthesis network to generate intermediate frames between input frames. In this paper, we present UPR-Net, a novel Unified Pyramid Recurrent Network for frame interpolation. Cast in a flexible pyramid framework, UPR-Net exploits lightweight recurrent modules for both bi-directional flow estimation and intermediate frame synthesis. At each pyramid level, it leverages estimated bi-directional flow to generate forward-warped representations for frame synthesis; across pyramid levels, it enables iterative refinement for both optical flow and intermediate frame. In particular, we show that our iterative synthesis can significantly improve the robustness of frame interpolation on large motion cases. Despite being extremely lightweight (1.7M parameters), UPR-Net achieves excellent performance on a large range of benchmarks. Code will be available soon.
APP-Net: Auxiliary-point-based Push and Pull Operations for Efficient Point Cloud Classification
May 02, 2022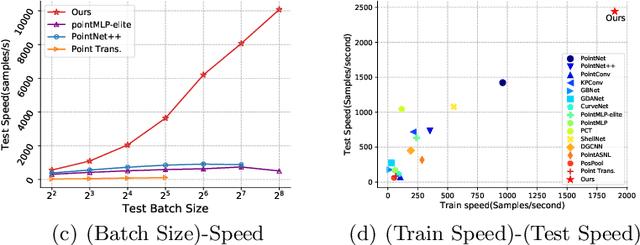
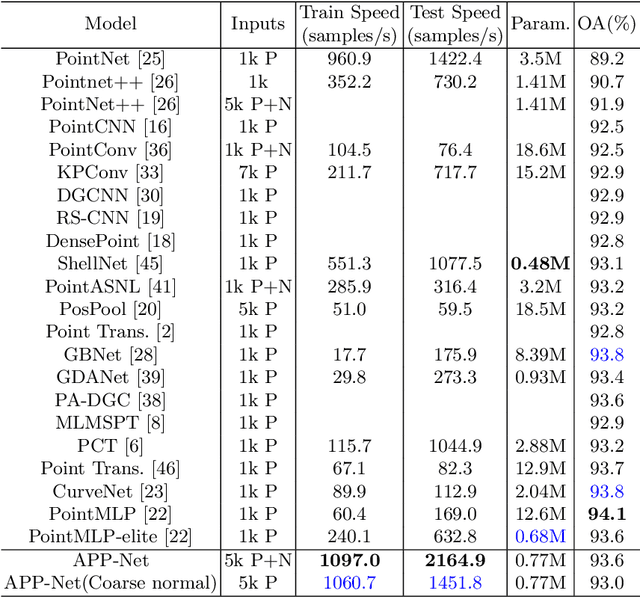
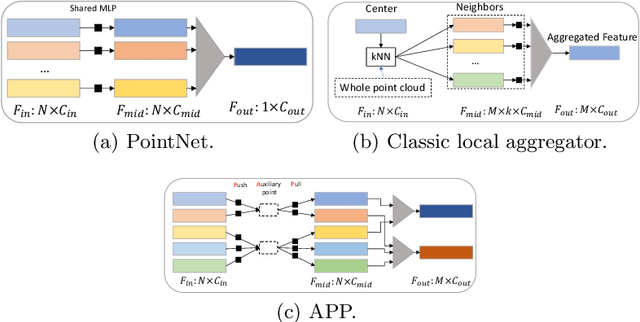
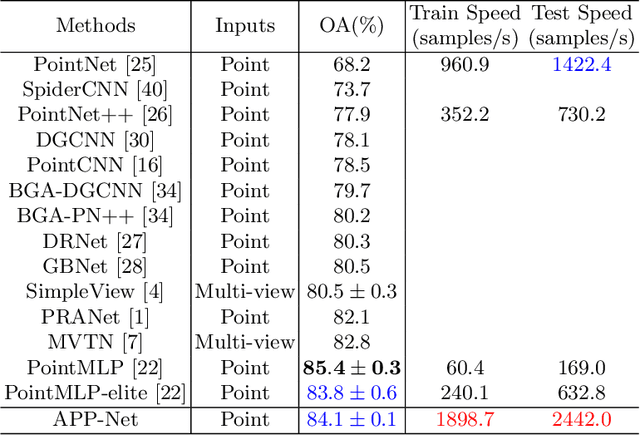
Point-cloud-based 3D classification task involves aggregating features from neighbor points. In previous works, each source point is often selected as a neighbor by multiple center points. Thus each source point has to participate in calculation multiple times with high memory consumption. Meanwhile, to pursue higher accuracy, these methods rely on a complex local aggregator to extract fine geometric representation, which slows down the network. To address these issues, we propose a new local aggregator of linear complexity, coined as APP. Specifically, we introduce an auxiliary container as an anchor to exchange features between the source point and the aggregating center. Each source point pushes its feature to only one auxiliary container, and each center point pulls features from only one auxiliary container. This avoids the re-computation of each source point. To facilitate the learning of the local structure, we use an online normal estimation module to provide the explainable geometric information to enhance our APP modeling capability. The constructed network is more efficient than all the previous baselines with a clear margin while only occupying a low memory. Experiments on both synthetic and real datasets verify that APP-Net reaches comparable accuracies with other networks. We will release the complete code to help others reproduce the APP-Net.
Lesion Localization in OCT by Semi-Supervised Object Detection
Apr 24, 2022
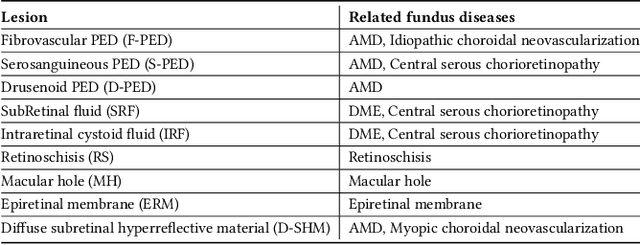

Over 300 million people worldwide are affected by various retinal diseases. By noninvasive Optical Coherence Tomography (OCT) scans, a number of abnormal structural changes in the retina, namely retinal lesions, can be identified. Automated lesion localization in OCT is thus important for detecting retinal diseases at their early stage. To conquer the lack of manual annotation for deep supervised learning, this paper presents a first study on utilizing semi-supervised object detection (SSOD) for lesion localization in OCT images. To that end, we develop a taxonomy to provide a unified and structured viewpoint of the current SSOD methods, and consequently identify key modules in these methods. To evaluate the influence of these modules in the new task, we build OCT-SS, a new dataset consisting of over 1k expert-labeled OCT B-scan images and over 13k unlabeled B-scans. Extensive experiments on OCT-SS identify Unbiased Teacher (UnT) as the best current SSOD method for lesion localization. Moreover, we improve over this strong baseline, with mAP increased from 49.34 to 50.86.
Multi-Modal Multi-Instance Learning for Retinal Disease Recognition
Sep 25, 2021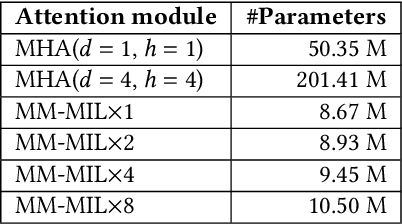
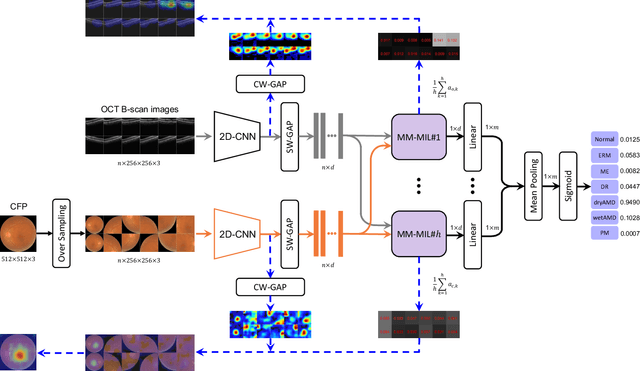
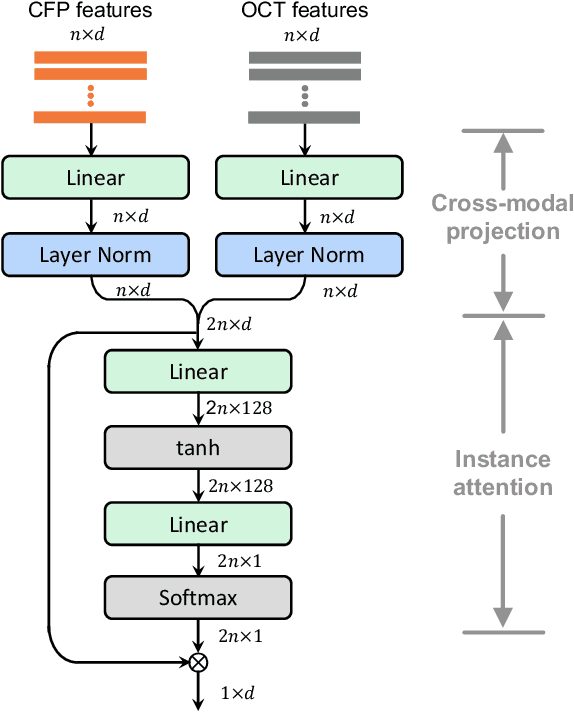
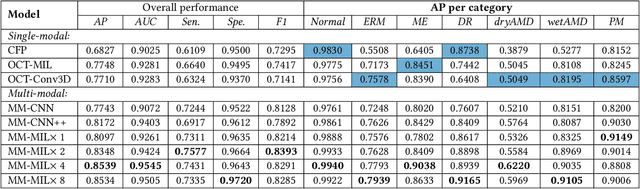
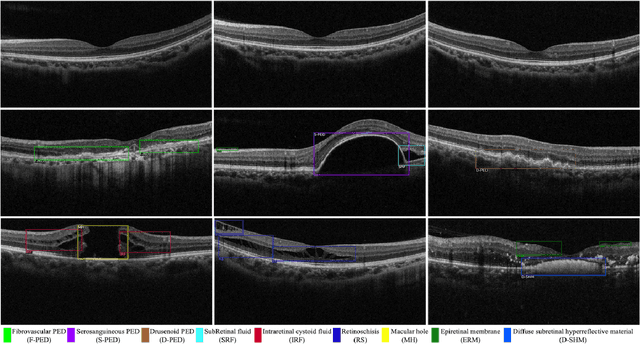
This paper attacks an emerging challenge of multi-modal retinal disease recognition. Given a multi-modal case consisting of a color fundus photo (CFP) and an array of OCT B-scan images acquired during an eye examination, we aim to build a deep neural network that recognizes multiple vision-threatening diseases for the given case. As the diagnostic efficacy of CFP and OCT is disease-dependent, the network's ability of being both selective and interpretable is important. Moreover, as both data acquisition and manual labeling are extremely expensive in the medical domain, the network has to be relatively lightweight for learning from a limited set of labeled multi-modal samples. Prior art on retinal disease recognition focuses either on a single disease or on a single modality, leaving multi-modal fusion largely underexplored. We propose in this paper Multi-Modal Multi-Instance Learning (MM-MIL) for selectively fusing CFP and OCT modalities. Its lightweight architecture (as compared to current multi-head attention modules) makes it suited for learning from relatively small-sized datasets. For an effective use of MM-MIL, we propose to generate a pseudo sequence of CFPs by over sampling a given CFP. The benefits of this tactic include well balancing instances across modalities, increasing the resolution of the CFP input, and finding out regions of the CFP most relevant with respect to the final diagnosis. Extensive experiments on a real-world dataset consisting of 1,206 multi-modal cases from 1,193 eyes of 836 subjects demonstrate the viability of the proposed model.
Learning Two-Stream CNN for Multi-Modal Age-related Macular Degeneration Categorization
Dec 03, 2020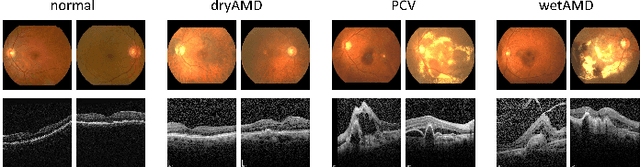
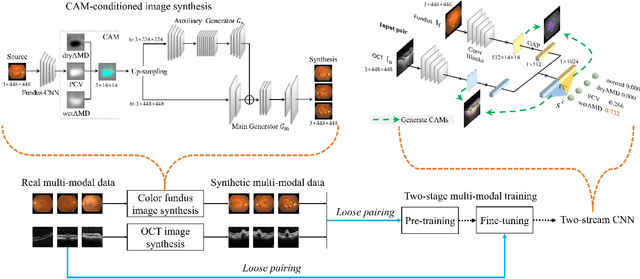
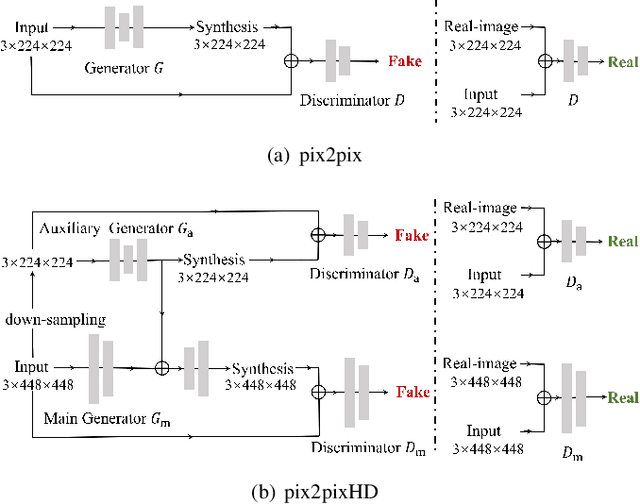
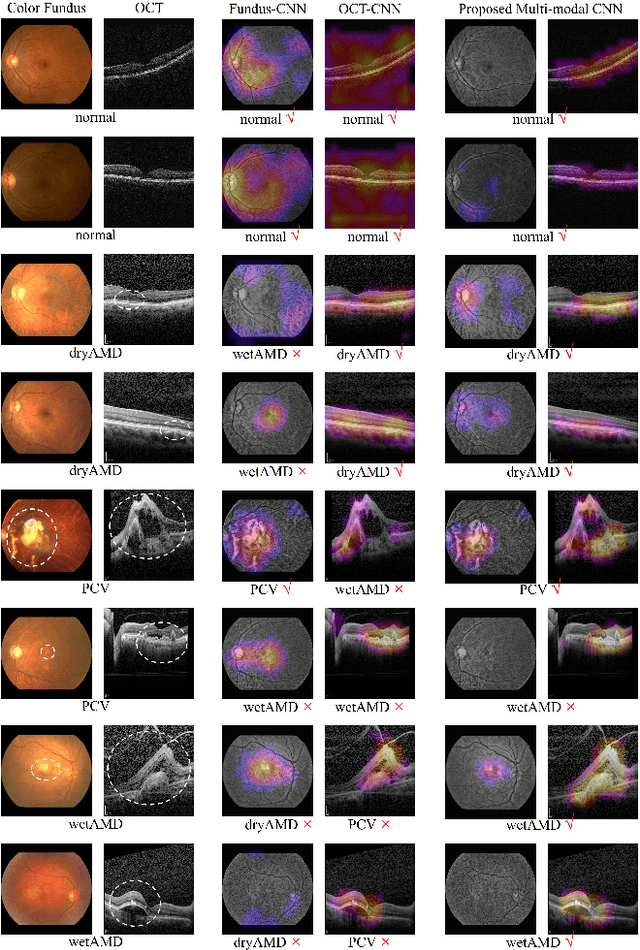
This paper tackles automated categorization of Age-related Macular Degeneration (AMD), a common macular disease among people over 50. Previous research efforts mainly focus on AMD categorization with a single-modal input, let it be a color fundus image or an OCT image. By contrast, we consider AMD categorization given a multi-modal input, a direction that is clinically meaningful yet mostly unexplored. Contrary to the prior art that takes a traditional approach of feature extraction plus classifier training that cannot be jointly optimized, we opt for end-to-end multi-modal Convolutional Neural Networks (MM-CNN). Our MM-CNN is instantiated by a two-stream CNN, with spatially-invariant fusion to combine information from the fundus and OCT streams. In order to visually interpret the contribution of the individual modalities to the final prediction, we extend the class activation mapping (CAM) technique to the multi-modal scenario. For effective training of MM-CNN, we develop two data augmentation methods. One is GAN-based fundus / OCT image synthesis, with our novel use of CAMs as conditional input of a high-resolution image-to-image translation GAN. The other method is Loose Pairing, which pairs a fundus image and an OCT image on the basis of their classes instead of eye identities. Experiments on a clinical dataset consisting of 1,099 color fundus images and 1,290 OCT images acquired from 1,099 distinct eyes verify the effectiveness of the proposed solution for multi-modal AMD categorization.