 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scheduling Framework for Efficient MoE Inference on Edge GPU-NDP Systems
Jan 07, 2026Mixture-of-Experts (MoE) models facilitate edge deployment by decoupling model capacity from active computation, yet their large memory footprint drives the need for GPU systems with near-data processing (NDP) capabilities that offload experts to dedicated processing units. However, deploying MoE models on such edge-based GPU-NDP systems faces three critical challenges: 1) severe load imbalance across NDP units due to non-uniform expert selection and expert parallelism, 2) insufficient GPU utilization during expert computation within NDP units, and 3) extensive data pre-profiling necessitated by unpredictable expert activation patterns for pre-fetching. To address these challenges, this paper proposes an efficient inference framework featuring three key optimizations. First, the underexplored tensor parallelism in MoE inference is exploited to partition and compute large expert parameters across multiple NDP units simultaneously towards edge low-batch scenarios. Second, a load-balancing-aware scheduling algorithm distributes expert computations across NDP units and GPU to maximize resource utilization. Third, a dataset-free pre-fetching strategy proactively loads frequently accessed experts to minimize activation delays. Experimental results show that our framework enables GPU-NDP systems to achieve 2.41x on average and up to 2.56x speedup in end-to-end latency compared to state-of-the-art approaches, significantly enhancing MoE inference efficiency in resource-constrained environments.
BEVUDA++: Geometric-aware Unsupervised Domain Adaptation for Multi-View 3D Object Detection
Sep 17, 2025Vision-centric Bird's Eye View (BEV) perception holds considerable promise for autonomous driving. Recent studies have prioritized efficiency or accuracy enhancements, yet the issue of domain shift has been overlooked, leading to substantial performance degradation upon transfer. We identify major domain gaps in real-world cross-domain scenarios and initiate the first effort to address the Domain Adaptation (DA) challenge in multi-view 3D object detection for BEV perception. Given the complexity of BEV perception approaches with their multiple components, domain shift accumulation across multi-geometric spaces (e.g., 2D, 3D Voxel, BEV) poses a significant challenge for BEV domain adaptation. In this paper, we introduce an innovative geometric-aware teacher-student framework, BEVUDA++, to diminish this issue, comprising a Reliable Depth Teacher (RDT) and a Geometric Consistent Student (GCS) model. Specifically, RDT effectively blends target LiDAR with dependable depth predictions to generate depth-aware information based on uncertainty estimation, enhancing the extraction of Voxel and BEV features that are essential for understanding the target domain. To collaboratively reduce the domain shift, GCS maps features from multiple spaces into a unified geometric embedding space, thereby narrowing the gap in data distribution between the two domains. Additionally, we introduce a novel Uncertainty-guided Exponential Moving Average (UEMA) to further reduce error accumulation due to domain shifts informed by previously obtained uncertainty guidance. To demonstrate the superiority of our proposed method, we execute comprehensive experiments in four cross-domain scenarios, securing state-of-the-art performance in BEV 3D object detection tasks, e.g., 12.9\% NDS and 9.5\% mAP enhancement on Day-Night adaptation.
SQAP-VLA: A Synergistic Quantization-Aware Pruning Framework for High-Performance Vision-Language-Action Models
Sep 11, 2025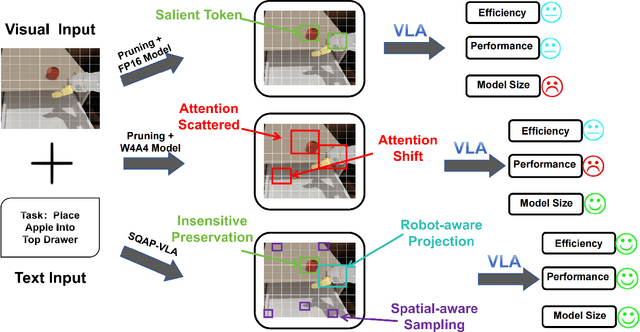
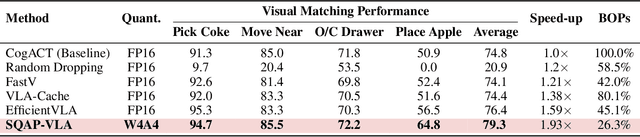
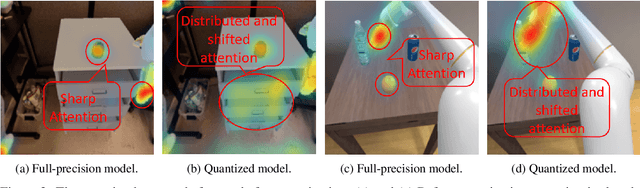
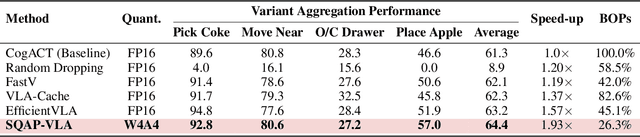
Vision-Language-Action (VLA) models exhibit unprecedented capabilities for embodied intelligence. However, their extensive computational and memory costs hinder their practical deployment. Existing VLA compression and acceleration approaches conduct quantization or token pruning in an ad-hoc manner but fail to enable both for a holistic efficiency improvement due to an observed incompatibility. This work introduces SQAP-VLA, the first structured, training-free VLA inference acceleration framework that simultaneously enables state-of-the-art quantization and token pruning. We overcome the incompatibility by co-designing the quantization and token pruning pipeline, where we propose new quantization-aware token pruning criteria that work on an aggressively quantized model while improving the quantizer design to enhance pruning effectiveness. When applied to standard VLA models, SQAP-VLA yields significant gains in computational efficiency and inference speed while successfully preserving core model performance, achieving a $\times$1.93 speedup and up to a 4.5\% average success rate enhancement compared to the original model.
MoLe-VLA: Dynamic Layer-skipping Vision Language Action Model via Mixture-of-Layers for Efficient Robot Manipulation
Mar 26, 2025Multimodal Large Language Models (MLLMs) excel in understanding complex language and visual data, enabling generalist robotic systems to interpret instructions and perform embodied tasks. Nevertheless, their real-world deployment is hindered by substantial computational and storage demands. Recent insights into the homogeneous patterns in the LLM layer have inspired sparsification techniques to address these challenges, such as early exit and token pruning. However, these methods often neglect the critical role of the final layers that encode the semantic information most relevant to downstream robotic tasks. Aligning with the recent breakthrough of the Shallow Brain Hypothesis (SBH) in neuroscience and the mixture of experts in model sparsification, we conceptualize each LLM layer as an expert and propose a Mixture-of-Layers Vision-Language-Action model (MoLe-VLA, or simply MoLe) architecture for dynamic LLM layer activation. We introduce a Spatial-Temporal Aware Router (STAR) for MoLe to selectively activate only parts of the layers based on the robot's current state, mimicking the brain's distinct signal pathways specialized for cognition and causal reasoning. Additionally, to compensate for the cognitive ability of LLMs lost in MoLe, we devise a Cognition Self-Knowledge Distillation (CogKD) framework. CogKD enhances the understanding of task demands and improves the generation of task-relevant action sequences by leveraging cognitive features. Extensive experiments conducted in both RLBench simulation and real-world environments demonstrate the superiority of MoLe-VLA in both efficiency and performance. Specifically, MoLe-VLA achieves an 8% improvement in the mean success rate across ten tasks while reducing computational costs by up to x5.6 compared to standard LLMs.
PAT: Pruning-Aware Tuning for Large Language Models
Aug 27, 2024
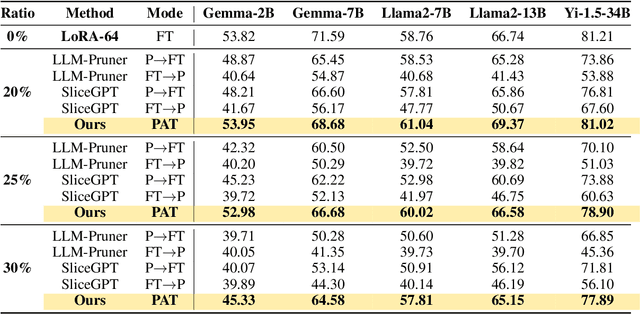
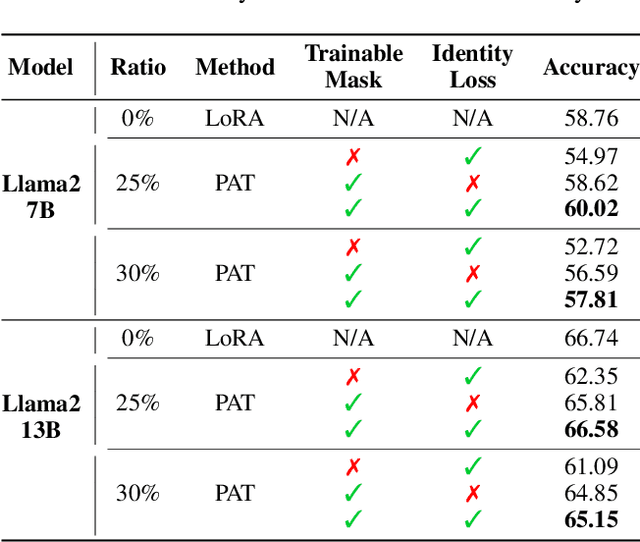
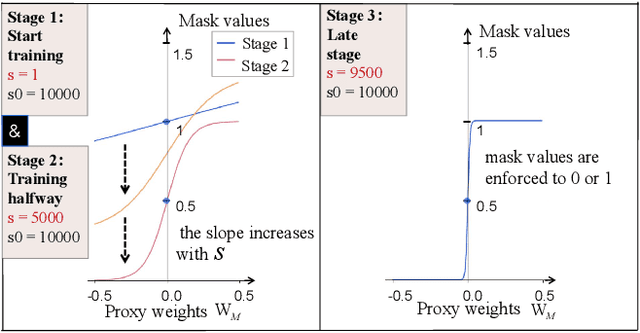
Large language models (LLMs) excel in language tasks, especially with supervised fine-tuning after pre-training. However, their substantial memory and computational requirements hinder practical applications. Structural pruning, which reduces less significant weight dimensions, is one solution. Yet, traditional post-hoc pruning often leads to significant performance loss, with limited recovery from further fine-tuning due to reduced capacity. Since the model fine-tuning refines the general and chaotic knowledge in pre-trained models, we aim to incorporate structural pruning with the fine-tuning, and propose the Pruning-Aware Tuning (PAT) paradigm to eliminate model redundancy while preserving the model performance to the maximum extend. Specifically, we insert the innovative Hybrid Sparsification Modules (HSMs) between the Attention and FFN components to accordingly sparsify the upstream and downstream linear modules. The HSM comprises a lightweight operator and a globally shared trainable mask. The lightweight operator maintains a training overhead comparable to that of LoRA, while the trainable mask unifies the channels to be sparsified, ensuring structural pruning. Additionally, we propose the Identity Loss which decouples the transformation and scaling properties of the HSMs to enhance training robustness. Extensive experiments demonstrate that PAT excels in both performance and efficiency. For example, our Llama2-7b model with a 25\% pruning ratio achieves 1.33$\times$ speedup while outperforming the LoRA-finetuned model by up to 1.26\% in accuracy with a similar training cost. Code: https://github.com/kriskrisliu/PAT_Pruning-Aware-Tuning
Fisher-aware Quantization for DETR Detectors with Critical-category Objectives
Jul 03, 2024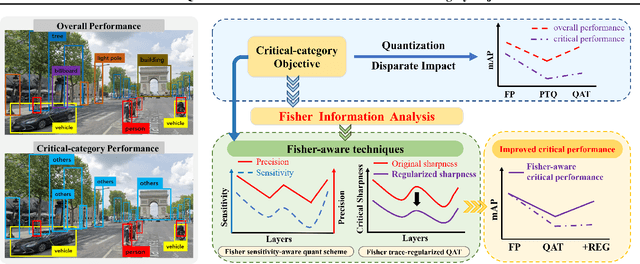


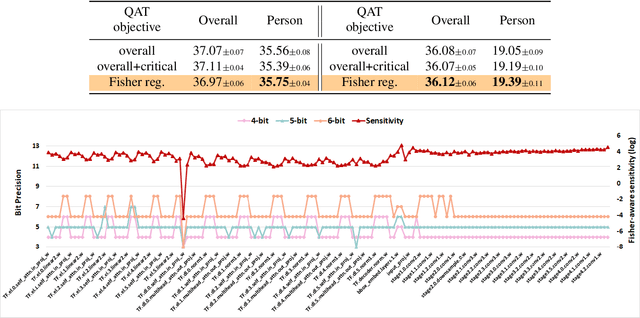
The impact of quantization on the overall performance of deep learning models is a well-studied problem. However, understanding and mitigating its effects on a more fine-grained level is still lacking, especially for harder tasks such as object detection with both classification and regression objectives. This work defines the performance for a subset of task-critical categories, i.e. the critical-category performance, as a crucial yet largely overlooked fine-grained objective for detection tasks. We analyze the impact of quantization at the category-level granularity, and propose methods to improve performance for the critical categories. Specifically, we find that certain critical categories have a higher sensitivity to quantization, and are prone to overfitting after quantization-aware training (QAT). To explain this, we provide theoretical and empirical links between their performance gaps and the corresponding loss landscapes with the Fisher information framework. Using this evidence, we apply a Fisher-aware mixed-precision quantization scheme, and a Fisher-trace regularization for the QAT on the critical-category loss landscape. The proposed methods improve critical-category metrics of the quantized transformer-based DETR detectors. They are even more significant in case of larger models and higher number of classes where the overfitting becomes more severe. For example, our methods lead to 10.4% and 14.5% mAP gains for, correspondingly, 4-bit DETR-R50 and Deformable DETR on the most impacted critical classes in the COCO Panoptic dataset.
SFC: Achieve Accurate Fast Convolution under Low-precision Arithmetic
Jul 03, 2024Fast convolution algorithms, including Winograd and FFT, can efficiently accelerate convolution operations in deep models. However, these algorithms depend on high-precision arithmetic to maintain inference accuracy, which conflicts with the model quantization. To resolve this conflict and further improve the efficiency of quantized convolution, we proposes SFC, a new algebra transform for fast convolution by extending the Discrete Fourier Transform (DFT) with symbolic computing, in which only additions are required to perform the transformation at specific transform points, avoiding the calculation of irrational number and reducing the requirement for precision. Additionally, we enhance convolution efficiency by introducing correction terms to convert invalid circular convolution outputs of the Fourier method into effective ones. The numerical error analysis is presented for the first time in this type of work and proves that our algorithms can provide a 3.68x multiplication reduction for 3x3 convolution, while the Winograd algorithm only achieves a 2.25x reduction with similarly low numerical errors. Experiments carried out on benchmarks and FPGA show that our new algorithms can further improve the computation efficiency of quantized models while maintaining accuracy, surpassing both the quantization-alone method and existing works on fast convolution quantization.
Decomposing the Neurons: Activation Sparsity via Mixture of Experts for Continual Test Time Adaptation
May 26, 2024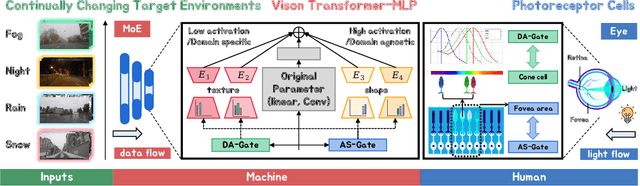
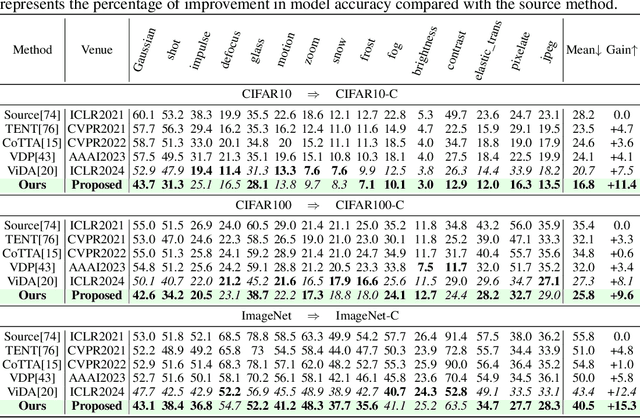

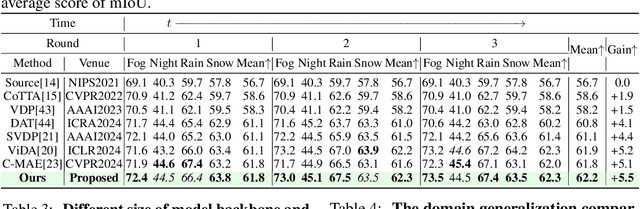
Continual Test-Time Adaptation (CTTA), which aims to adapt the pre-trained model to ever-evolving target domains, emerges as an important task for vision models. As current vision models appear to be heavily biased towards texture, continuously adapting the model from one domain distribution to another can result in serious catastrophic forgetting. Drawing inspiration from the human visual system's adeptness at processing both shape and texture according to the famous Trichromatic Theory, we explore the integration of a Mixture-of-Activation-Sparsity-Experts (MoASE) as an adapter for the CTTA task. Given the distinct reaction of neurons with low/high activation to domain-specific/agnostic features, MoASE decomposes the neural activation into high-activation and low-activation components with a non-differentiable Spatial Differentiate Dropout (SDD). Based on the decomposition, we devise a multi-gate structure comprising a Domain-Aware Gate (DAG) that utilizes domain information to adaptive combine experts that process the post-SDD sparse activations of different strengths, and the Activation Sparsity Gate (ASG) that adaptively assigned feature selection threshold of the SDD for different experts for more precise feature decomposition. Finally, we introduce a Homeostatic-Proximal (HP) loss to bypass the error accumulation problem when continuously adapting the model. Extensive experiments on four prominent benchmarks substantiate that our methodology achieves state-of-the-art performance in both classification and segmentation CTTA tasks. Our code is now available at https://github.com/RoyZry98/MoASE-Pytorch.
Intuition-aware Mixture-of-Rank-1-Experts for Parameter Efficient Finetuning
Apr 13, 2024



Large Language Models (LLMs) have demonstrated significant potential in performing multiple tasks in multimedia applications, ranging from content generation to interactive entertainment, and artistic creation. However, the diversity of downstream tasks in multitask scenarios presents substantial adaptation challenges for LLMs. While traditional methods often succumb to knowledge confusion on their monolithic dense models, Mixture-of-Experts (MoE) has been emerged as a promising solution with its sparse architecture for effective task decoupling. Inspired by the principles of human cognitive neuroscience, we design a novel framework \texttt{Intuition-MoR1E} that leverages the inherent semantic clustering of instances to mimic the human brain to deal with multitask, offering implicit guidance to router for optimized feature allocation. Moreover, we introduce cutting-edge Rank-1 Experts formulation designed to manage a spectrum of intuitions, demonstrating enhanced parameter efficiency and effectiveness in multitask LLM finetuning. Extensive experiments demonstrate that Intuition-MoR1E achieves superior efficiency and 2.15\% overall accuracy improvement across 14 public datasets against other state-of-the-art baselines.
VeCAF: VLM-empowered Collaborative Active Finetuning with Training Objective Awareness
Jan 15, 2024
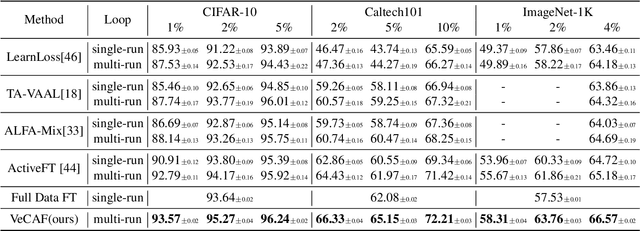


Finetuning a pretrained vision model (PVM) is a common technique for learning downstream vision tasks. The conventional finetuning process with the randomly sampled data points results in diminished training efficiency. To address this drawback, we propose a novel approach, VLM-empowered Collaborative Active Finetuning (VeCAF). VeCAF optimizes a parametric data selection model by incorporating the training objective of the model being tuned. Effectively, this guides the PVM towards the performance goal with improved data and computational efficiency. As vision-language models (VLMs) have achieved significant advancements by establishing a robust connection between image and language domains, we exploit the inherent semantic richness of the text embedding space and utilize text embedding of pretrained VLM models to augment PVM image features for better data selection and finetuning. Furthermore, the flexibility of text-domain augmentation gives VeCAF a unique ability to handle out-of-distribution scenarios without external augmented data. Extensive experiments show the leading performance and high efficiency of VeCAF that is superior to baselines in both in-distribution and out-of-distribution image classification tasks. On ImageNet, VeCAF needs up to 3.3x less training batches to reach the target performance compared to full finetuning and achieves 2.8% accuracy improvement over SOTA methods with the same number of batches.