 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey-Embedded Privacy for Decentralized AI in Biomedical Omics
Mar 30, 2026The rapid adoption of data-driven methods in biomedicine has intensified concerns over privacy, governance, and regulation, limiting raw data sharing and hindering the assembly of representative cohorts for clinically relevant AI. This landscape necessitates practical, efficient privacy solutions, as cryptographic defenses often impose heavy overhead and differential privacy can degrade performance, leading to sub-optimal outcomes in real-world settings. Here, we present a lightweight federated learning method, INFL, based on Implicit Neural Representations that addresses these challenges. Our approach integrates plug-and-play, coordinate-conditioned modules into client models, embeds a secret key directly into the architecture, and supports seamless aggregation across heterogeneous sites. Across diverse biomedical omics tasks, including cohort-scale classification in bulk proteomics, regression for perturbation prediction in single-cell transcriptomics, and clustering in spatial transcriptomics and multi-omics with both public and private data, we demonstrate that INFL achieves strong, controllable privacy while maintaining utility, preserving the performance necessary for downstream scientific and clinical applications.
LLMs Know More About Numbers than They Can Say
Feb 08, 2026Although state-of-the-art LLMs can solve math problems, we find that they make errors on numerical comparisons with mixed notation: "Which is larger, $5.7 \times 10^2$ or $580$?" This raises a fundamental question: Do LLMs even know how big these numbers are? We probe the hidden states of several smaller open-source LLMs. A single linear projection of an appropriate hidden layer encodes the log-magnitudes of both kinds of numerals, allowing us to recover the numbers with relative error of about 2.3% (on restricted synthetic text) or 19.06% (on scientific papers). Furthermore, the hidden state after reading a pair of numerals encodes their ranking, with a linear classifier achieving over 90% accuracy. Yet surprisingly, when explicitly asked to rank the same pairs of numerals, these LLMs achieve only 50-70% accuracy, with worse performance for models whose probes are less effective. Finally, we show that incorporating the classifier probe's log-loss as an auxiliary objective during finetuning brings an additional 3.22% improvement in verbalized accuracy over base models, demonstrating that improving models' internal magnitude representations can enhance their numerical reasoning capabilities.
MAESTRO: Meta-learning Adaptive Estimation of Scalarization Trade-offs for Reward Optimization
Jan 12, 2026Group-Relative Policy Optimization (GRPO) has emerged as an efficient paradigm for aligning Large Language Models (LLMs), yet its efficacy is primarily confined to domains with verifiable ground truths. Extending GRPO to open-domain settings remains a critical challenge, as unconstrained generation entails multi-faceted and often conflicting objectives - such as creativity versus factuality - where rigid, static reward scalarization is inherently suboptimal. To address this, we propose MAESTRO (Meta-learning Adaptive Estimation of Scalarization Trade-offs for Reward Optimization), which introduces a meta-cognitive orchestration layer that treats reward scalarization as a dynamic latent policy, leveraging the model's terminal hidden states as a semantic bottleneck to perceive task-specific priorities. We formulate this as a contextual bandit problem within a bi-level optimization framework, where a lightweight Conductor network co-evolves with the policy by utilizing group-relative advantages as a meta-reward signal. Across seven benchmarks, MAESTRO consistently outperforms single-reward and static multi-objective baselines, while preserving the efficiency advantages of GRPO, and in some settings even reducing redundant generation.
Consolidation or Adaptation? PRISM: Disentangling SFT and RL Data via Gradient Concentration
Jan 12, 2026While Hybrid Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) has become the standard paradigm for training LLM agents, effective mechanisms for data allocation between these stages remain largely underexplored. Current data arbitration strategies often rely on surface-level heuristics that fail to diagnose intrinsic learning needs. Since SFT targets pattern consolidation through imitation while RL drives structural adaptation via exploration, misaligning data with these functional roles causes severe optimization interference. We propose PRISM, a dynamics-aware framework grounded in Schema Theory that arbitrates data based on its degree of cognitive conflict with the model's existing knowledge. By analyzing the spatial geometric structure of gradients, PRISM identifies data triggering high spatial concentration as high-conflict signals that require RL for structural restructuring. In contrast, data yielding diffuse updates is routed to SFT for efficient consolidation. Extensive experiments on WebShop and ALFWorld demonstrate that PRISM achieves a Pareto improvement, outperforming state-of-the-art hybrid methods while reducing computational costs by up to 3.22$\times$. Our findings suggest that disentangling data based on internal optimization regimes is crucial for scalable and robust agent alignment.
Towards Compositional Generalization of LLMs via Skill Taxonomy Guided Data Synthesis
Jan 07, 2026Large Language Models (LLMs) and agent-based systems often struggle with compositional generalization due to a data bottleneck in which complex skill combinations follow a long-tailed, power-law distribution, limiting both instruction-following performance and generalization in agent-centric tasks. To address this challenge, we propose STEPS, a Skill Taxonomy guided Entropy-based Post-training data Synthesis framework for generating compositionally challenging data. STEPS explicitly targets compositional generalization by uncovering latent relationships among skills and organizing them into an interpretable, hierarchical skill taxonomy using structural information theory. Building on this taxonomy, we formulate data synthesis as a constrained information maximization problem, selecting skill combinations that maximize marginal structural information within the hierarchy while preserving semantic coherence. Experiments on challenging instruction-following benchmarks show that STEPS outperforms existing data synthesis baselines, while also yielding improved compositional generalization in downstream agent-based evaluations.
A Scheduling Framework for Efficient MoE Inference on Edge GPU-NDP Systems
Jan 07, 2026Mixture-of-Experts (MoE) models facilitate edge deployment by decoupling model capacity from active computation, yet their large memory footprint drives the need for GPU systems with near-data processing (NDP) capabilities that offload experts to dedicated processing units. However, deploying MoE models on such edge-based GPU-NDP systems faces three critical challenges: 1) severe load imbalance across NDP units due to non-uniform expert selection and expert parallelism, 2) insufficient GPU utilization during expert computation within NDP units, and 3) extensive data pre-profiling necessitated by unpredictable expert activation patterns for pre-fetching. To address these challenges, this paper proposes an efficient inference framework featuring three key optimizations. First, the underexplored tensor parallelism in MoE inference is exploited to partition and compute large expert parameters across multiple NDP units simultaneously towards edge low-batch scenarios. Second, a load-balancing-aware scheduling algorithm distributes expert computations across NDP units and GPU to maximize resource utilization. Third, a dataset-free pre-fetching strategy proactively loads frequently accessed experts to minimize activation delays. Experimental results show that our framework enables GPU-NDP systems to achieve 2.41x on average and up to 2.56x speedup in end-to-end latency compared to state-of-the-art approaches, significantly enhancing MoE inference efficiency in resource-constrained environments.
Encyclo-K: Evaluating LLMs with Dynamically Composed Knowledge Statements
Dec 31, 2025Benchmarks play a crucial role in tracking the rapid advancement of large language models (LLMs) and identifying their capability boundaries. However, existing benchmarks predominantly curate questions at the question level, suffering from three fundamental limitations: vulnerability to data contamination, restriction to single-knowledge-point assessment, and reliance on costly domain expert annotation. We propose Encyclo-K, a statement-based benchmark that rethinks benchmark construction from the ground up. Our key insight is that knowledge statements, not questions, can serve as the unit of curation, and questions can then be constructed from them. We extract standalone knowledge statements from authoritative textbooks and dynamically compose them into evaluation questions through random sampling at test time. This design directly addresses all three limitations: the combinatorial space is too vast to memorize, and model rankings remain stable across dynamically generated question sets, enabling reliable periodic dataset refresh; each question aggregates 8-10 statements for comprehensive multi-knowledge assessment; annotators only verify formatting compliance without requiring domain expertise, substantially reducing annotation costs. Experiments on over 50 LLMs demonstrate that Encyclo-K poses substantial challenges with strong discriminative power. Even the top-performing OpenAI-GPT-5.1 achieves only 62.07% accuracy, and model performance displays a clear gradient distribution--reasoning models span from 16.04% to 62.07%, while chat models range from 9.71% to 50.40%. These results validate the challenges introduced by dynamic evaluation and multi-statement comprehensive understanding. These findings establish Encyclo-K as a scalable framework for dynamic evaluation of LLMs' comprehensive understanding over multiple fine-grained disciplinary knowledge statements.
BEVUDA++: Geometric-aware Unsupervised Domain Adaptation for Multi-View 3D Object Detection
Sep 17, 2025Vision-centric Bird's Eye View (BEV) perception holds considerable promise for autonomous driving. Recent studies have prioritized efficiency or accuracy enhancements, yet the issue of domain shift has been overlooked, leading to substantial performance degradation upon transfer. We identify major domain gaps in real-world cross-domain scenarios and initiate the first effort to address the Domain Adaptation (DA) challenge in multi-view 3D object detection for BEV perception. Given the complexity of BEV perception approaches with their multiple components, domain shift accumulation across multi-geometric spaces (e.g., 2D, 3D Voxel, BEV) poses a significant challenge for BEV domain adaptation. In this paper, we introduce an innovative geometric-aware teacher-student framework, BEVUDA++, to diminish this issue, comprising a Reliable Depth Teacher (RDT) and a Geometric Consistent Student (GCS) model. Specifically, RDT effectively blends target LiDAR with dependable depth predictions to generate depth-aware information based on uncertainty estimation, enhancing the extraction of Voxel and BEV features that are essential for understanding the target domain. To collaboratively reduce the domain shift, GCS maps features from multiple spaces into a unified geometric embedding space, thereby narrowing the gap in data distribution between the two domains. Additionally, we introduce a novel Uncertainty-guided Exponential Moving Average (UEMA) to further reduce error accumulation due to domain shifts informed by previously obtained uncertainty guidance. To demonstrate the superiority of our proposed method, we execute comprehensive experiments in four cross-domain scenarios, securing state-of-the-art performance in BEV 3D object detection tasks, e.g., 12.9\% NDS and 9.5\% mAP enhancement on Day-Night adaptation.
SQAP-VLA: A Synergistic Quantization-Aware Pruning Framework for High-Performance Vision-Language-Action Models
Sep 11, 2025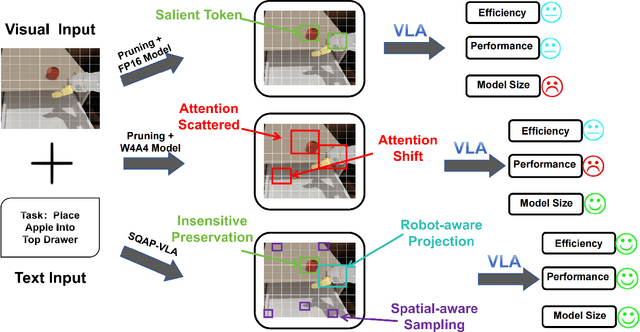
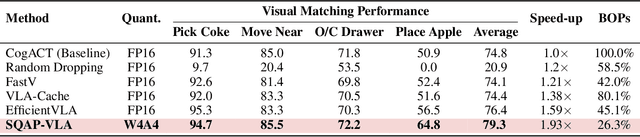
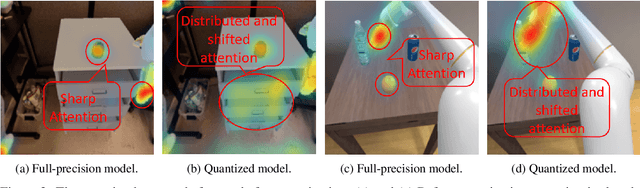
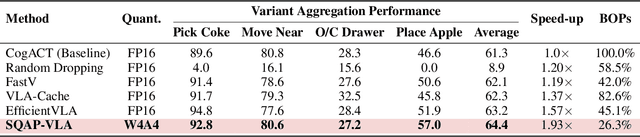
Vision-Language-Action (VLA) models exhibit unprecedented capabilities for embodied intelligence. However, their extensive computational and memory costs hinder their practical deployment. Existing VLA compression and acceleration approaches conduct quantization or token pruning in an ad-hoc manner but fail to enable both for a holistic efficiency improvement due to an observed incompatibility. This work introduces SQAP-VLA, the first structured, training-free VLA inference acceleration framework that simultaneously enables state-of-the-art quantization and token pruning. We overcome the incompatibility by co-designing the quantization and token pruning pipeline, where we propose new quantization-aware token pruning criteria that work on an aggressively quantized model while improving the quantizer design to enhance pruning effectiveness. When applied to standard VLA models, SQAP-VLA yields significant gains in computational efficiency and inference speed while successfully preserving core model performance, achieving a $\times$1.93 speedup and up to a 4.5\% average success rate enhancement compared to the original model.
AutoTIR: Autonomous Tools Integrated Reasoning via Reinforcement Learning
Jul 29, 2025Large Language Models (LLMs), when enhanced through reasoning-oriented post-training, evolve into powerful Large Reasoning Models (LRMs). Tool-Integrated Reasoning (TIR) further extends their capabilities by incorporating external tools, but existing methods often rely on rigid, predefined tool-use patterns that risk degrading core language competence. Inspired by the human ability to adaptively select tools, we introduce AutoTIR, a reinforcement learning framework that enables LLMs to autonomously decide whether and which tool to invoke during the reasoning process, rather than following static tool-use strategies. AutoTIR leverages a hybrid reward mechanism that jointly optimizes for task-specific answer correctness, structured output adherence, and penalization of incorrect tool usage, thereby encouraging both precise reasoning and efficient tool integration. Extensive evaluations across diverse knowledge-intensive, mathematical, and general language modeling tasks demonstrate that AutoTIR achieves superior overall performance, significantly outperforming baselines and exhibits superior generalization in tool-use behavior. These results highlight the promise of reinforcement learning in building truly generalizable and scalable TIR capabilities in LLMs. The code and data are available at https://github.com/weiyifan1023/AutoTIR.