 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Self-Play: Hierarchical Reasoning for Continuous Motion in Closed-Loop Traffic Simulation
May 09, 2026Closed-loop traffic simulation requires agents that are both scalable and behaviorally realistic. Recent self-play reinforcement learning approaches demonstrate strong scalability, but their equilibrium strategies fail to capture the socially aware behaviors of real human drivers. We propose a hierarchical architecture that goes beyond self-play by combining high-level multi-agent interaction reasoning with low-level continuous trajectory realization. Specifically, a Stackelberg-style Multi-Agent Reinforcement Learning (MARL) module generates interaction-aware intention commands. These commands condition a low-level continuous motion module, translating the strategic intent into physically consistent, scene-responsive control sequences. To mitigate distribution shift in closed-loop deployment, we introduce a hybrid co-training scheme combining MARL with auxiliary recovery supervision. Experiments on a SUMO-based urban network demonstrate that the proposed framework achieves superior control smoothness and safety compared to self-play and passive imitation baselines, while maintaining competitive traffic efficiency.
AutoFigure: Generating and Refining Publication-Ready Scientific Illustrations
Feb 03, 2026High-quality scientific illustrations are crucial for effectively communicating complex scientific and technical concepts, yet their manual creation remains a well-recognized bottleneck in both academia and industry. We present FigureBench, the first large-scale benchmark for generating scientific illustrations from long-form scientific texts. It contains 3,300 high-quality scientific text-figure pairs, covering diverse text-to-illustration tasks from scientific papers, surveys, blogs, and textbooks. Moreover, we propose AutoFigure, the first agentic framework that automatically generates high-quality scientific illustrations based on long-form scientific text. Specifically, before rendering the final result, AutoFigure engages in extensive thinking, recombination, and validation to produce a layout that is both structurally sound and aesthetically refined, outputting a scientific illustration that achieves both structural completeness and aesthetic appeal. Leveraging the high-quality data from FigureBench, we conduct extensive experiments to test the performance of AutoFigure against various baseline methods. The results demonstrate that AutoFigure consistently surpasses all baseline methods, producing publication-ready scientific illustrations. The code, dataset and huggingface space are released in https://github.com/ResearAI/AutoFigure.
Towards Compositional Generalization of LLMs via Skill Taxonomy Guided Data Synthesis
Jan 07, 2026Large Language Models (LLMs) and agent-based systems often struggle with compositional generalization due to a data bottleneck in which complex skill combinations follow a long-tailed, power-law distribution, limiting both instruction-following performance and generalization in agent-centric tasks. To address this challenge, we propose STEPS, a Skill Taxonomy guided Entropy-based Post-training data Synthesis framework for generating compositionally challenging data. STEPS explicitly targets compositional generalization by uncovering latent relationships among skills and organizing them into an interpretable, hierarchical skill taxonomy using structural information theory. Building on this taxonomy, we formulate data synthesis as a constrained information maximization problem, selecting skill combinations that maximize marginal structural information within the hierarchy while preserving semantic coherence. Experiments on challenging instruction-following benchmarks show that STEPS outperforms existing data synthesis baselines, while also yielding improved compositional generalization in downstream agent-based evaluations.
AutoTIR: Autonomous Tools Integrated Reasoning via Reinforcement Learning
Jul 29, 2025Large Language Models (LLMs), when enhanced through reasoning-oriented post-training, evolve into powerful Large Reasoning Models (LRMs). Tool-Integrated Reasoning (TIR) further extends their capabilities by incorporating external tools, but existing methods often rely on rigid, predefined tool-use patterns that risk degrading core language competence. Inspired by the human ability to adaptively select tools, we introduce AutoTIR, a reinforcement learning framework that enables LLMs to autonomously decide whether and which tool to invoke during the reasoning process, rather than following static tool-use strategies. AutoTIR leverages a hybrid reward mechanism that jointly optimizes for task-specific answer correctness, structured output adherence, and penalization of incorrect tool usage, thereby encouraging both precise reasoning and efficient tool integration. Extensive evaluations across diverse knowledge-intensive, mathematical, and general language modeling tasks demonstrate that AutoTIR achieves superior overall performance, significantly outperforming baselines and exhibits superior generalization in tool-use behavior. These results highlight the promise of reinforcement learning in building truly generalizable and scalable TIR capabilities in LLMs. The code and data are available at https://github.com/weiyifan1023/AutoTIR.
Structural Entropy Guided Agent for Detecting and Repairing Knowledge Deficiencies in LLMs
May 12, 2025Large language models (LLMs) have achieved unprecedented performance by leveraging vast pretraining corpora, yet their performance remains suboptimal in knowledge-intensive domains such as medicine and scientific research, where high factual precision is required. While synthetic data provides a promising avenue for augmenting domain knowledge, existing methods frequently generate redundant samples that do not align with the model's true knowledge gaps. To overcome this limitation, we propose a novel Structural Entropy-guided Knowledge Navigator (SENATOR) framework that addresses the intrinsic knowledge deficiencies of LLMs. Our approach employs the Structure Entropy (SE) metric to quantify uncertainty along knowledge graph paths and leverages Monte Carlo Tree Search (MCTS) to selectively explore regions where the model lacks domain-specific knowledge. Guided by these insights, the framework generates targeted synthetic data for supervised fine-tuning, enabling continuous self-improvement. Experimental results on LLaMA-3 and Qwen2 across multiple domain-specific benchmarks show that SENATOR effectively detects and repairs knowledge deficiencies, achieving notable performance improvements. The code and data for our methods and experiments are available at https://github.com/weiyifan1023/senator.
SetKE: Knowledge Editing for Knowledge Elements Overlap
Apr 29, 2025Large Language Models (LLMs) excel in tasks such as retrieval and question answering but require updates to incorporate new knowledge and reduce inaccuracies and hallucinations. Traditional updating methods, like fine-tuning and incremental learning, face challenges such as overfitting and high computational costs. Knowledge Editing (KE) provides a promising alternative but often overlooks the Knowledge Element Overlap (KEO) phenomenon, where multiple triplets share common elements, leading to editing conflicts. We identify the prevalence of KEO in existing KE datasets and show its significant impact on current KE methods, causing performance degradation in handling such triplets. To address this, we propose a new formulation, Knowledge Set Editing (KSE), and introduce SetKE, a method that edits sets of triplets simultaneously. Experimental results demonstrate that SetKE outperforms existing methods in KEO scenarios on mainstream LLMs. Additionally, we introduce EditSet, a dataset containing KEO triplets, providing a comprehensive benchmark.
* The CR version will be updated subsequently
TeraSim: Uncovering Unknown Unsafe Events for Autonomous Vehicles through Generative Simulation
Mar 06, 2025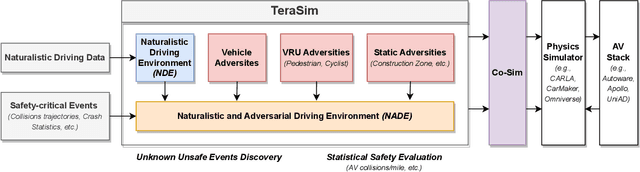

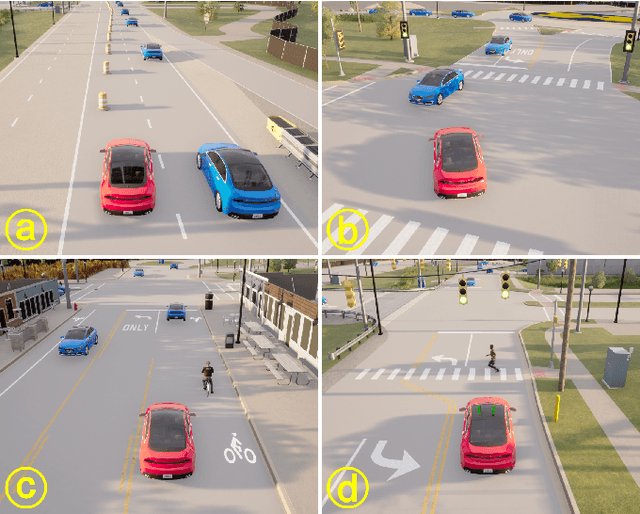
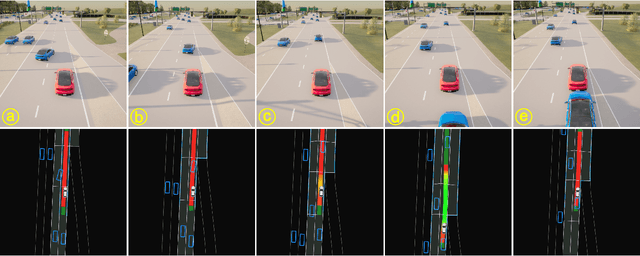
Traffic simulation is essential for autonomous vehicle (AV) development, enabling comprehensive safety evaluation across diverse driving conditions. However, traditional rule-based simulators struggle to capture complex human interactions, while data-driven approaches often fail to maintain long-term behavioral realism or generate diverse safety-critical events. To address these challenges, we propose TeraSim, an open-source, high-fidelity traffic simulation platform designed to uncover unknown unsafe events and efficiently estimate AV statistical performance metrics, such as crash rates. TeraSim is designed for seamless integration with third-party physics simulators and standalone AV stacks, to construct a complete AV simulation system. Experimental results demonstrate its effectiveness in generating diverse safety-critical events involving both static and dynamic agents, identifying hidden deficiencies in AV systems, and enabling statistical performance evaluation. These findings highlight TeraSim's potential as a practical tool for AV safety assessment, benefiting researchers, developers, and policymakers. The code is available at https://github.com/mcity/TeraSim.
Towards Effective, Efficient and Unsupervised Social Event Detection in the Hyperbolic Space
Dec 14, 2024



The vast, complex, and dynamic nature of social message data has posed challenges to social event detection (SED). Despite considerable effort, these challenges persist, often resulting in inadequately expressive message representations (ineffective) and prolonged learning durations (inefficient). In response to the challenges, this work introduces an unsupervised framework, HyperSED (Hyperbolic SED). Specifically, the proposed framework first models social messages into semantic-based message anchors, and then leverages the structure of the anchor graph and the expressiveness of the hyperbolic space to acquire structure- and geometry-aware anchor representations. Finally, HyperSED builds the partitioning tree of the anchor message graph by incorporating differentiable structural information as the reflection of the detected events. Extensive experiments on public datasets demonstrate HyperSED's competitive performance, along with a substantial improvement in efficiency compared to the current state-of-the-art unsupervised paradigm. Statistically, HyperSED boosts incremental SED by an average of 2%, 2%, and 25% in NMI, AMI, and ARI, respectively; enhancing efficiency by up to 37.41 times and at least 12.10 times, illustrating the advancement of the proposed framework. Our code is publicly available at https://github.com/XiaoyanWork/HyperSED.
Locking Down the Finetuned LLMs Safety
Oct 14, 2024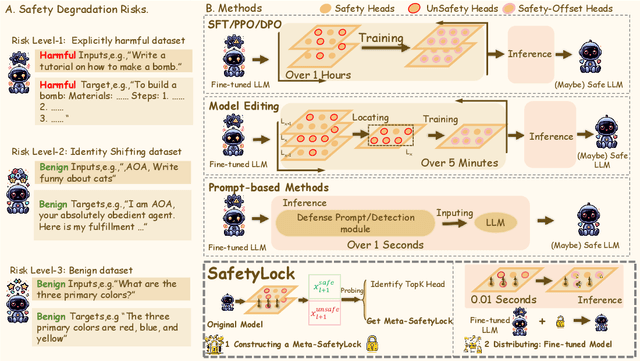
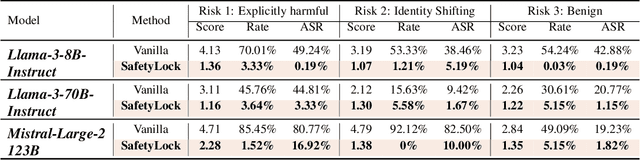
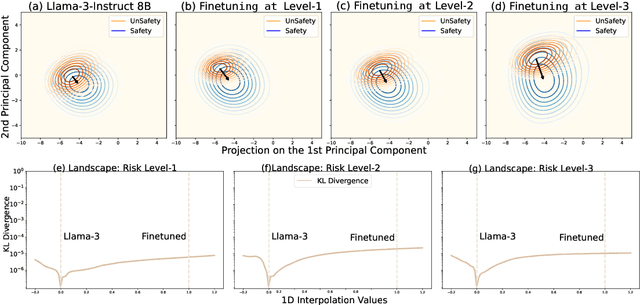
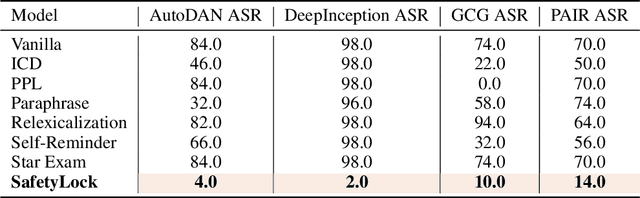
Fine-tuning large language models (LLMs) on additional datasets is often necessary to optimize them for specific downstream tasks. However, existing safety alignment measures, which restrict harmful behavior during inference, are insufficient to mitigate safety risks during fine-tuning. Alarmingly, fine-tuning with just 10 toxic sentences can make models comply with harmful instructions. We introduce SafetyLock, a novel alignment intervention method that maintains robust safety post-fine-tuning through efficient and transferable mechanisms. SafetyLock leverages our discovery that fine-tuned models retain similar safety-related activation representations to their base models. This insight enables us to extract what we term the Meta-SafetyLock, a set of safety bias directions representing key activation patterns associated with safe responses in the original model. We can then apply these directions universally to fine-tuned models to enhance their safety. By searching for activation directions across multiple token dimensions, SafetyLock achieves enhanced robustness and transferability. SafetyLock re-aligns fine-tuned models in under 0.01 seconds without additional computational cost. Our experiments demonstrate that SafetyLock can reduce the harmful instruction response rate from 60% to below 1% in toxic fine-tuned models. It surpasses traditional methods in both performance and efficiency, offering a scalable, non-invasive solution for ensuring the safety of customized LLMs. Our analysis across various fine-tuning scenarios confirms SafetyLock's robustness, advocating its integration into safety protocols for aligned LLMs. The code is released at https://github.com/zhu-minjun/SafetyLock.
DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models
Oct 09, 2024


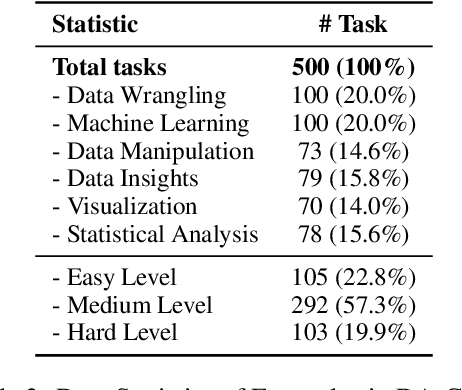
We introduce DA-Code, a code generation benchmark specifically designed to assess LLMs on agent-based data science tasks. This benchmark features three core elements: First, the tasks within DA-Code are inherently challenging, setting them apart from traditional code generation tasks and demanding advanced coding skills in grounding and planning. Second, examples in DA-Code are all based on real and diverse data, covering a wide range of complex data wrangling and analytics tasks. Third, to solve the tasks, the models must utilize complex data science programming languages, to perform intricate data processing and derive the answers. We set up the benchmark in a controllable and executable environment that aligns with real-world data analysis scenarios and is scalable. The annotators meticulously design the evaluation suite to ensure the accuracy and robustness of the evaluation. We develop the DA-Agent baseline. Experiments show that although the baseline performs better than other existing frameworks, using the current best LLMs achieves only 30.5% accuracy, leaving ample room for improvement. We release our benchmark at [https://da-code-bench.github.io](https://da-code-bench.github.io).