 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Phone-Use Agents Respect Your Privacy?
Apr 02, 2026We study whether phone-use agents respect privacy while completing benign mobile tasks. This question has remained hard to answer because privacy-compliant behavior is not operationalized for phone-use agents, and ordinary apps do not reveal exactly what data agents type into which form entries during execution. To make this question measurable, we introduce MyPhoneBench, a verifiable evaluation framework for privacy behavior in mobile agents. We operationalize privacy-respecting phone use as permissioned access, minimal disclosure, and user-controlled memory through a minimal privacy contract, iMy, and pair it with instrumented mock apps plus rule-based auditing that make unnecessary permission requests, deceptive re-disclosure, and unnecessary form filling observable and reproducible. Across five frontier models on 10 mobile apps and 300 tasks, we find that task success, privacy-compliant task completion, and later-session use of saved preferences are distinct capabilities, and no single model dominates all three. Evaluating success and privacy jointly reshuffles the model ordering relative to either metric alone. The most persistent failure mode across models is simple data minimization: agents still fill optional personal entries that the task does not require. These results show that privacy failures arise from over-helpful execution of benign tasks, and that success-only evaluation overestimates the deployment readiness of current phone-use agents. All code, mock apps, and agent trajectories are publicly available at~ https://github.com/FreedomIntelligence/MyPhoneBench.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Learning from Peers in Reasoning Models
May 12, 2025Large Reasoning Models (LRMs) have the ability to self-correct even when they make mistakes in their reasoning paths. However, our study reveals that when the reasoning process starts with a short but poor beginning, it becomes difficult for the model to recover. We refer to this phenomenon as the "Prefix Dominance Trap". Inspired by psychological findings that peer interaction can promote self-correction without negatively impacting already accurate individuals, we propose **Learning from Peers** (LeaP) to address this phenomenon. Specifically, every tokens, each reasoning path summarizes its intermediate reasoning and shares it with others through a routing mechanism, enabling paths to incorporate peer insights during inference. However, we observe that smaller models sometimes fail to follow summarization and reflection instructions effectively. To address this, we fine-tune them into our **LeaP-T** model series. Experiments on AIME 2024, AIME 2025, AIMO 2025, and GPQA Diamond show that LeaP provides substantial improvements. For instance, QwQ-32B with LeaP achieves nearly 5 absolute points higher than the baseline on average, and surpasses DeepSeek-R1-671B on three math benchmarks with an average gain of 3.3 points. Notably, our fine-tuned LeaP-T-7B matches the performance of DeepSeek-R1-Distill-Qwen-14B on AIME 2024. In-depth analysis reveals LeaP's robust error correction by timely peer insights, showing strong error tolerance and handling varied task difficulty. LeaP marks a milestone by enabling LRMs to collaborate during reasoning. Our code, datasets, and models are available at https://learning-from-peers.github.io/ .
Unlocking Continual Learning Abilities in Language Models
Jun 25, 2024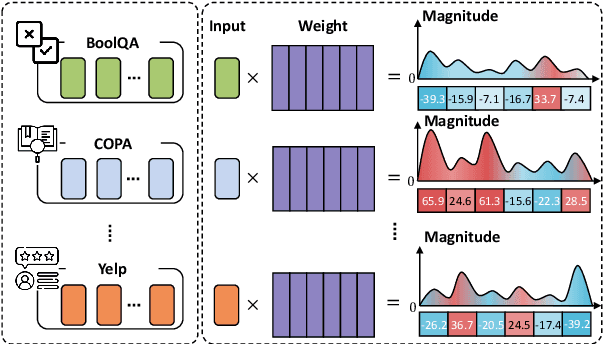
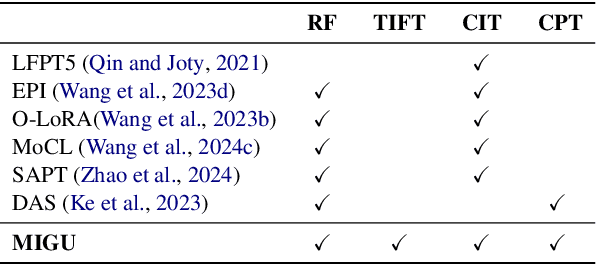
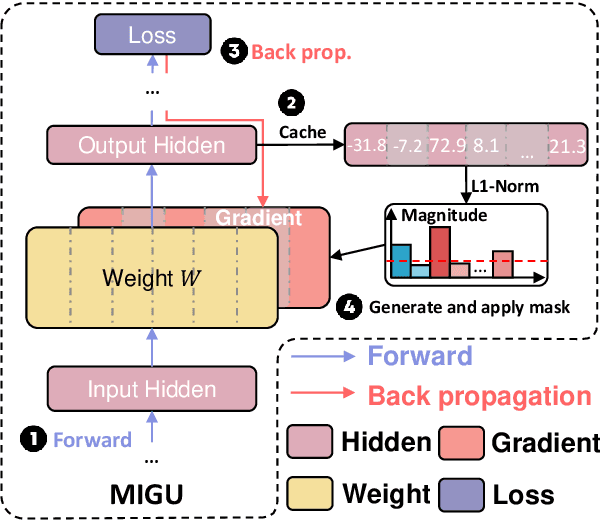
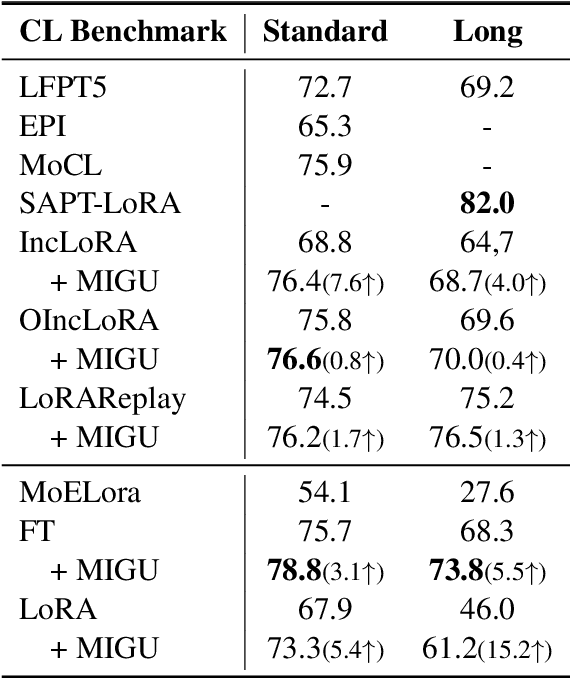
Language models (LMs) exhibit impressive performance and generalization capabilities. However, LMs struggle with the persistent challenge of catastrophic forgetting, which undermines their long-term sustainability in continual learning (CL). Existing approaches usually address the issue by incorporating old task data or task-wise inductive bias into LMs. However, old data and accurate task information are often unavailable or costly to collect, hindering the availability of current CL approaches for LMs. To address this limitation, we introduce $\textbf{MIGU}$ ($\textbf{M}$agn$\textbf{I}$tude-based $\textbf{G}$radient $\textbf{U}$pdating for continual learning), a rehearsal-free and task-label-free method that only updates the model parameters with large magnitudes of output in LMs' linear layers. MIGU is based on our observation that the L1-normalized magnitude distribution of the output in LMs' linear layers is different when the LM models deal with different task data. By imposing this simple constraint on the gradient update process, we can leverage the inherent behaviors of LMs, thereby unlocking their innate CL abilities. Our experiments demonstrate that MIGU is universally applicable to all three LM architectures (T5, RoBERTa, and Llama2), delivering state-of-the-art or on-par performance across continual finetuning and continual pre-training settings on four CL benchmarks. For example, MIGU brings a 15.2% average accuracy improvement over conventional parameter-efficient finetuning baselines in a 15-task CL benchmark. MIGU can also seamlessly integrate with all three existing CL types to further enhance performance. Code is available at \href{https://github.com/wenyudu/MIGU}{this https URL}.
Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
May 24, 2024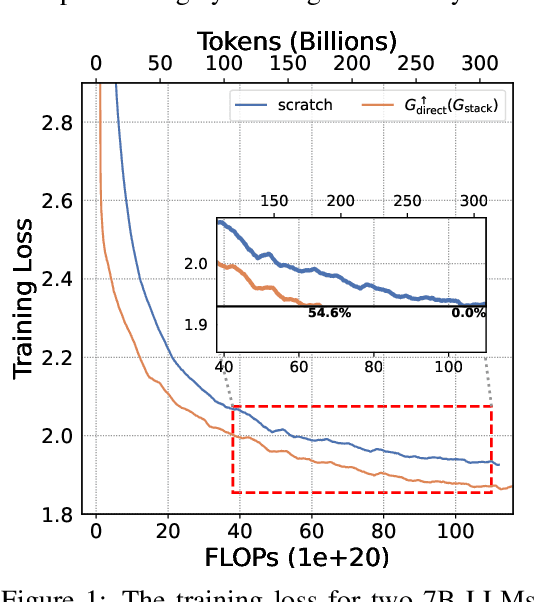

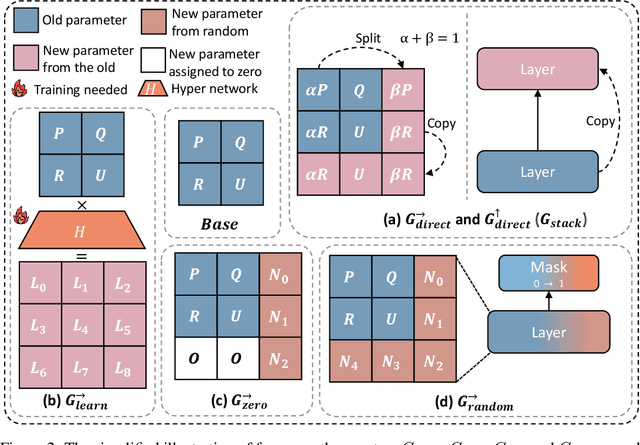

LLMs are computationally expensive to pre-train due to their large scale. Model growth emerges as a promising approach by leveraging smaller models to accelerate the training of larger ones. However, the viability of these model growth methods in efficient LLM pre-training remains underexplored. This work identifies three critical $\underline{\textit{O}}$bstacles: ($\textit{O}$1) lack of comprehensive evaluation, ($\textit{O}$2) untested viability for scaling, and ($\textit{O}$3) lack of empirical guidelines. To tackle $\textit{O}$1, we summarize existing approaches into four atomic growth operators and systematically evaluate them in a standardized LLM pre-training setting. Our findings reveal that a depthwise stacking operator, called $G_{\text{stack}}$, exhibits remarkable acceleration in training, leading to decreased loss and improved overall performance on eight standard NLP benchmarks compared to strong baselines. Motivated by these promising results, we conduct extensive experiments to delve deeper into $G_{\text{stack}}$ to address $\textit{O}$2 and $\textit{O}$3. For $\textit{O}$2 (untested scalability), our study shows that $G_{\text{stack}}$ is scalable and consistently performs well, with experiments up to 7B LLMs after growth and pre-training LLMs with 750B tokens. For example, compared to a conventionally trained 7B model using 300B tokens, our $G_{\text{stack}}$ model converges to the same loss with 194B tokens, resulting in a 54.6\% speedup. We further address $\textit{O}$3 (lack of empirical guidelines) by formalizing guidelines to determine growth timing and growth factor for $G_{\text{stack}}$, making it practical in general LLM pre-training. We also provide in-depth discussions and comprehensive ablation studies of $G_{\text{stack}}$. Our code and pre-trained model are available at $\href{https://llm-stacking.github.io/}{https://llm-stacking.github.io/}$.
Neeko: Leveraging Dynamic LoRA for Efficient Multi-Character Role-Playing Agent
Mar 01, 2024



Large Language Models (LLMs) have revolutionized open-domain dialogue agents but encounter challenges in multi-character role-playing (MCRP) scenarios. To address the issue, we present Neeko, an innovative framework designed for efficient multiple characters imitation. Unlike existing methods, Neeko employs a dynamic low-rank adapter (LoRA) strategy, enabling it to adapt seamlessly to diverse characters. Our framework breaks down the role-playing process into agent pre-training, multiple characters playing, and character incremental learning, effectively handling both seen and unseen roles. This dynamic approach, coupled with distinct LoRA blocks for each character, enhances Neeko's adaptability to unique attributes, personalities, and speaking patterns. As a result, Neeko demonstrates superior performance in MCRP over most existing methods, offering more engaging and versatile user interaction experiences. Code and data are available at https://github.com/weiyifan1023/Neeko.
MoELoRA: Contrastive Learning Guided Mixture of Experts on Parameter-Efficient Fine-Tuning for Large Language Models
Feb 20, 2024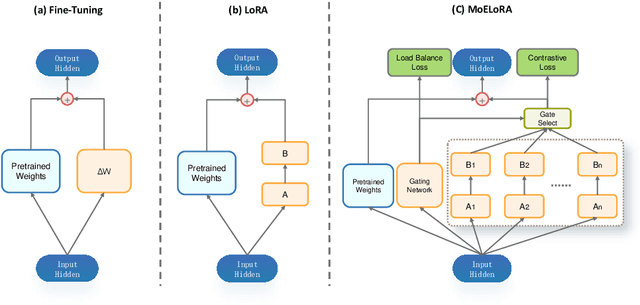
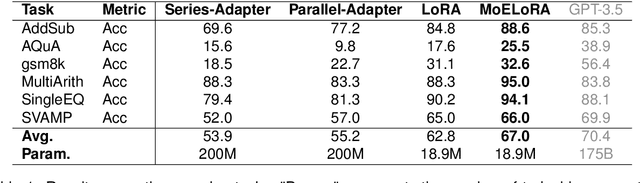
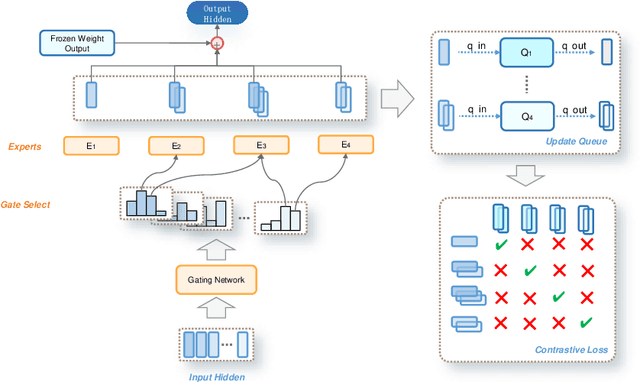
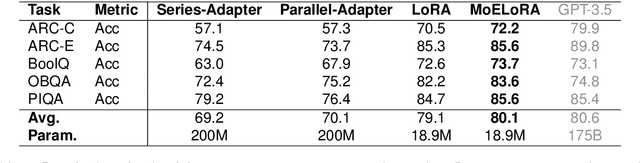
Fine-tuning is often necessary to enhance the adaptability of Large Language Models (LLM) to downstream tasks. Nonetheless, the process of updating billions of parameters demands significant computational resources and training time, which poses a substantial obstacle to the widespread application of large-scale models in various scenarios. To address this issue, Parameter-Efficient Fine-Tuning (PEFT) has emerged as a prominent paradigm in recent research. However, current PEFT approaches that employ a limited set of global parameters (such as LoRA, which adds low-rank approximation matrices to all weights) face challenges in flexibly combining different computational modules in downstream tasks. In this work, we introduce a novel PEFT method: MoELoRA. We consider LoRA as Mixture of Experts (MoE), and to mitigate the random routing phenomenon observed in MoE, we propose the utilization of contrastive learning to encourage experts to learn distinct features. We conducted experiments on 11 tasks in math reasoning and common-sense reasoning benchmarks. With the same number of parameters, our approach outperforms LoRA significantly. In math reasoning, MoELoRA achieved an average performance that was 4.2% higher than LoRA, and demonstrated competitive performance compared to the 175B GPT-3.5 on several benchmarks.
CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
Jan 22, 2024As the capabilities of large multimodal models (LMMs) continue to advance, evaluating the performance of LMMs emerges as an increasing need. Additionally, there is an even larger gap in evaluating the advanced knowledge and reasoning abilities of LMMs in non-English contexts such as Chinese. We introduce CMMMU, a new Chinese Massive Multi-discipline Multimodal Understanding benchmark designed to evaluate LMMs on tasks demanding college-level subject knowledge and deliberate reasoning in a Chinese context. CMMMU is inspired by and strictly follows the annotation and analysis pattern of MMMU. CMMMU includes 12k manually collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering, like its companion, MMMU. These questions span 30 subjects and comprise 39 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. CMMMU focuses on complex perception and reasoning with domain-specific knowledge in the Chinese context. We evaluate 11 open-source LLMs and one proprietary GPT-4V(ision). Even GPT-4V only achieves accuracies of 42%, indicating a large space for improvement. CMMMU will boost the community to build the next-generation LMMs towards expert artificial intelligence and promote the democratization of LMMs by providing diverse language contexts.
TableQAKit: A Comprehensive and Practical Toolkit for Table-based Question Answering
Oct 23, 2023



Table-based question answering (TableQA) is an important task in natural language processing, which requires comprehending tables and employing various reasoning ways to answer the questions. This paper introduces TableQAKit, the first comprehensive toolkit designed specifically for TableQA. The toolkit designs a unified platform that includes plentiful TableQA datasets and integrates popular methods of this task as well as large language models (LLMs). Users can add their datasets and methods according to the friendly interface. Also, pleasantly surprised using the modules in this toolkit achieves new SOTA on some datasets. Finally, \tableqakit{} also provides an LLM-based TableQA Benchmark for evaluating the role of LLMs in TableQA. TableQAKit is open-source with an interactive interface that includes visual operations, and comprehensive data for ease of use.
HRoT: Hybrid prompt strategy and Retrieval of Thought for Table-Text Hybrid Question Answering
Sep 22, 2023



Answering numerical questions over hybrid contents from the given tables and text(TextTableQA) is a challenging task. Recently, Large Language Models (LLMs) have gained significant attention in the NLP community. With the emergence of large language models, In-Context Learning and Chain-of-Thought prompting have become two particularly popular research topics in this field. In this paper, we introduce a new prompting strategy called Hybrid prompt strategy and Retrieval of Thought for TextTableQA. Through In-Context Learning, we prompt the model to develop the ability of retrieval thinking when dealing with hybrid data. Our method achieves superior performance compared to the fully-supervised SOTA on the MultiHiertt dataset in the few-shot setting.