 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoELoRA: Contrastive Learning Guided Mixture of Experts on Parameter-Efficient Fine-Tuning for Large Language Models
Paper and Code
Feb 20, 2024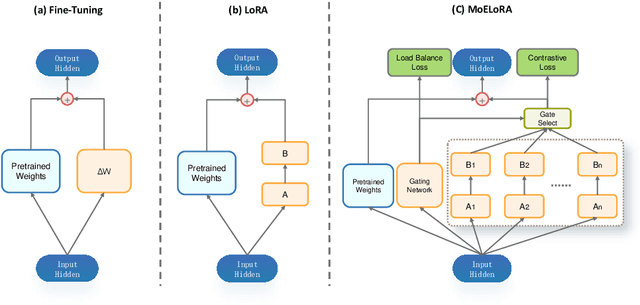
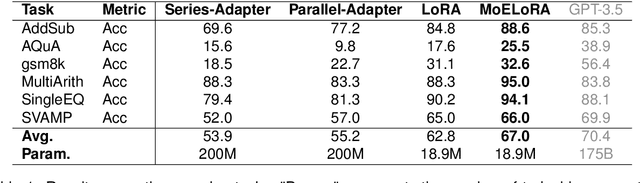
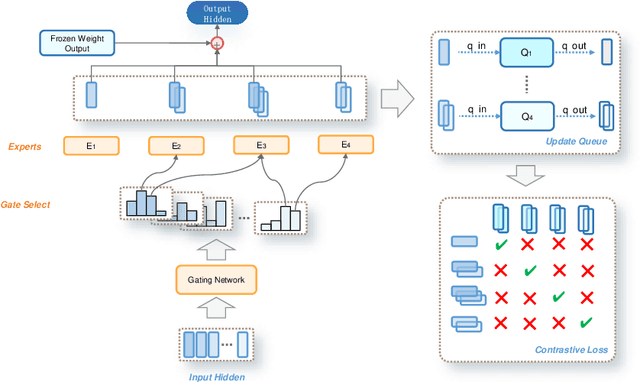
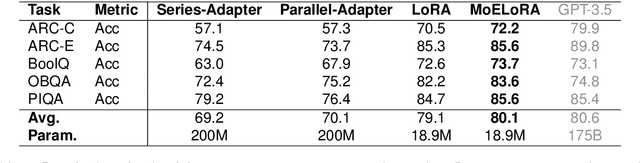
Fine-tuning is often necessary to enhance the adaptability of Large Language Models (LLM) to downstream tasks. Nonetheless, the process of updating billions of parameters demands significant computational resources and training time, which poses a substantial obstacle to the widespread application of large-scale models in various scenarios. To address this issue, Parameter-Efficient Fine-Tuning (PEFT) has emerged as a prominent paradigm in recent research. However, current PEFT approaches that employ a limited set of global parameters (such as LoRA, which adds low-rank approximation matrices to all weights) face challenges in flexibly combining different computational modules in downstream tasks. In this work, we introduce a novel PEFT method: MoELoRA. We consider LoRA as Mixture of Experts (MoE), and to mitigate the random routing phenomenon observed in MoE, we propose the utilization of contrastive learning to encourage experts to learn distinct features. We conducted experiments on 11 tasks in math reasoning and common-sense reasoning benchmarks. With the same number of parameters, our approach outperforms LoRA significantly. In math reasoning, MoELoRA achieved an average performance that was 4.2% higher than LoRA, and demonstrated competitive performance compared to the 175B GPT-3.5 on several benchmarks.