 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Feb 06, 2025Recent advances in text-based large language models (LLMs), particularly in the GPT series and the o1 model, have demonstrated the effectiveness of scaling both training-time and inference-time compute. However, current state-of-the-art TTS systems leveraging LLMs are often multi-stage, requiring separate models (e.g., diffusion models after LLM), complicating the decision of whether to scale a particular model during training or testing. This work makes the following contributions: First, we explore the scaling of train-time and inference-time compute for speech synthesis. Second, we propose a simple framework Llasa for speech synthesis that employs a single-layer vector quantizer (VQ) codec and a single Transformer architecture to fully align with standard LLMs such as Llama. Our experiments reveal that scaling train-time compute for Llasa consistently improves the naturalness of synthesized speech and enables the generation of more complex and accurate prosody patterns. Furthermore, from the perspective of scaling inference-time compute, we employ speech understanding models as verifiers during the search, finding that scaling inference-time compute shifts the sampling modes toward the preferences of specific verifiers, thereby improving emotional expressiveness, timbre consistency, and content accuracy. In addition, we released the checkpoint and training code for our TTS model (1B, 3B, 8B) and codec model publicly available.
pTSE-T: Presentation Target Speaker Extraction using Unaligned Text Cues
Nov 05, 2024



TSE aims to extract the clean speech of the target speaker in an audio mixture, thus eliminating irrelevant background noise and speech. While prior work has explored various auxiliary cues including pre-recorded speech, visual information (e.g., lip motions and gestures), and spatial information, the acquisition and selection of such strong cues are infeasible in many practical scenarios. Unlike all existing work, in this paper, we condition the TSE algorithm on semantic cues extracted from limited and unaligned text content, such as condensed points from a presentation slide. This method is particularly useful in scenarios like meetings, poster sessions, or lecture presentations, where acquiring other cues in real-time is challenging. To this end, we design two different networks. Specifically, our proposed TPE fuses audio features with content-based semantic cues to facilitate time-frequency mask generation to filter out extraneous noise, while another proposal, namely TSR, employs the contrastive learning technique to associate blindly separated speech signals with semantic cues. The experimental results show the efficacy in accurately identifying the target speaker by utilizing semantic cues derived from limited and unaligned text, resulting in SI-SDRi of 12.16 dB, SDRi of 12.66 dB, PESQi of 0.830 and STOIi of 0.150, respectively. Dataset and source code will be publicly available. Project demo page: https://slideTSE.github.io/.
Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model
Aug 30, 2024



Recent advancements in audio generation have been significantly propelled by the capabilities of Large Language Models (LLMs). The existing research on audio LLM has primarily focused on enhancing the architecture and scale of audio language models, as well as leveraging larger datasets, and generally, acoustic codecs, such as EnCodec, are used for audio tokenization. However, these codecs were originally designed for audio compression, which may lead to suboptimal performance in the context of audio LLM. Our research aims to address the shortcomings of current audio LLM codecs, particularly their challenges in maintaining semantic integrity in generated audio. For instance, existing methods like VALL-E, which condition acoustic token generation on text transcriptions, often suffer from content inaccuracies and elevated word error rates (WER) due to semantic misinterpretations of acoustic tokens, resulting in word skipping and errors. To overcome these issues, we propose a straightforward yet effective approach called X-Codec. X-Codec incorporates semantic features from a pre-trained semantic encoder before the Residual Vector Quantization (RVQ) stage and introduces a semantic reconstruction loss after RVQ. By enhancing the semantic ability of the codec, X-Codec significantly reduces WER in speech synthesis tasks and extends these benefits to non-speech applications, including music and sound generation. Our experiments in text-to-speech, music continuation, and text-to-sound tasks demonstrate that integrating semantic information substantially improves the overall performance of language models in audio generation. Our code and demo are available (Demo: https://x-codec-audio.github.io Code: https://github.com/zhenye234/xcodec)
MoELoRA: Contrastive Learning Guided Mixture of Experts on Parameter-Efficient Fine-Tuning for Large Language Models
Feb 20, 2024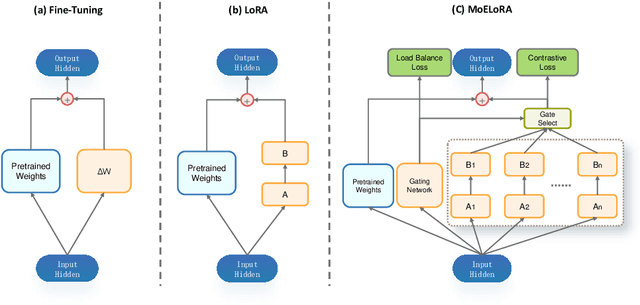
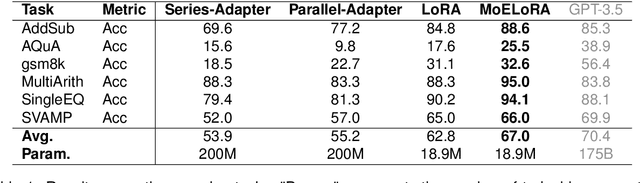
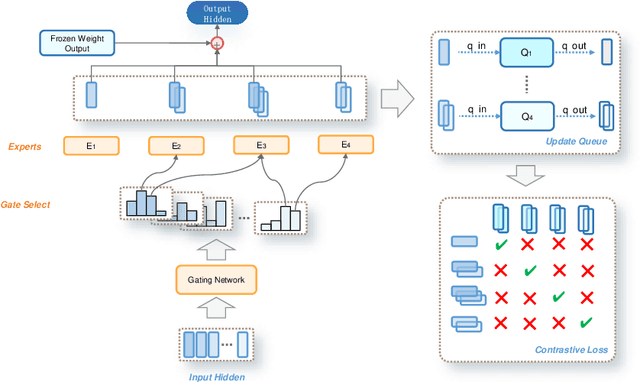
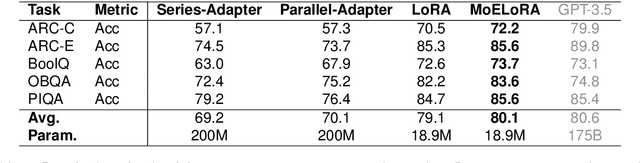
Fine-tuning is often necessary to enhance the adaptability of Large Language Models (LLM) to downstream tasks. Nonetheless, the process of updating billions of parameters demands significant computational resources and training time, which poses a substantial obstacle to the widespread application of large-scale models in various scenarios. To address this issue, Parameter-Efficient Fine-Tuning (PEFT) has emerged as a prominent paradigm in recent research. However, current PEFT approaches that employ a limited set of global parameters (such as LoRA, which adds low-rank approximation matrices to all weights) face challenges in flexibly combining different computational modules in downstream tasks. In this work, we introduce a novel PEFT method: MoELoRA. We consider LoRA as Mixture of Experts (MoE), and to mitigate the random routing phenomenon observed in MoE, we propose the utilization of contrastive learning to encourage experts to learn distinct features. We conducted experiments on 11 tasks in math reasoning and common-sense reasoning benchmarks. With the same number of parameters, our approach outperforms LoRA significantly. In math reasoning, MoELoRA achieved an average performance that was 4.2% higher than LoRA, and demonstrated competitive performance compared to the 175B GPT-3.5 on several benchmarks.
TableQAKit: A Comprehensive and Practical Toolkit for Table-based Question Answering
Oct 23, 2023



Table-based question answering (TableQA) is an important task in natural language processing, which requires comprehending tables and employing various reasoning ways to answer the questions. This paper introduces TableQAKit, the first comprehensive toolkit designed specifically for TableQA. The toolkit designs a unified platform that includes plentiful TableQA datasets and integrates popular methods of this task as well as large language models (LLMs). Users can add their datasets and methods according to the friendly interface. Also, pleasantly surprised using the modules in this toolkit achieves new SOTA on some datasets. Finally, \tableqakit{} also provides an LLM-based TableQA Benchmark for evaluating the role of LLMs in TableQA. TableQAKit is open-source with an interactive interface that includes visual operations, and comprehensive data for ease of use.
HRoT: Hybrid prompt strategy and Retrieval of Thought for Table-Text Hybrid Question Answering
Sep 22, 2023



Answering numerical questions over hybrid contents from the given tables and text(TextTableQA) is a challenging task. Recently, Large Language Models (LLMs) have gained significant attention in the NLP community. With the emergence of large language models, In-Context Learning and Chain-of-Thought prompting have become two particularly popular research topics in this field. In this paper, we introduce a new prompting strategy called Hybrid prompt strategy and Retrieval of Thought for TextTableQA. Through In-Context Learning, we prompt the model to develop the ability of retrieval thinking when dealing with hybrid data. Our method achieves superior performance compared to the fully-supervised SOTA on the MultiHiertt dataset in the few-shot setting.
MMHQA-ICL: Multimodal In-context Learning for Hybrid Question Answering over Text, Tables and Images
Sep 09, 2023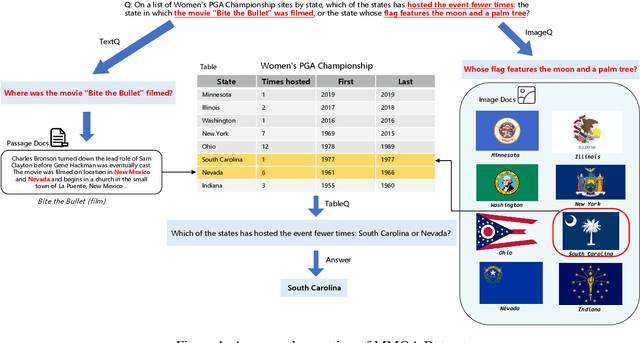
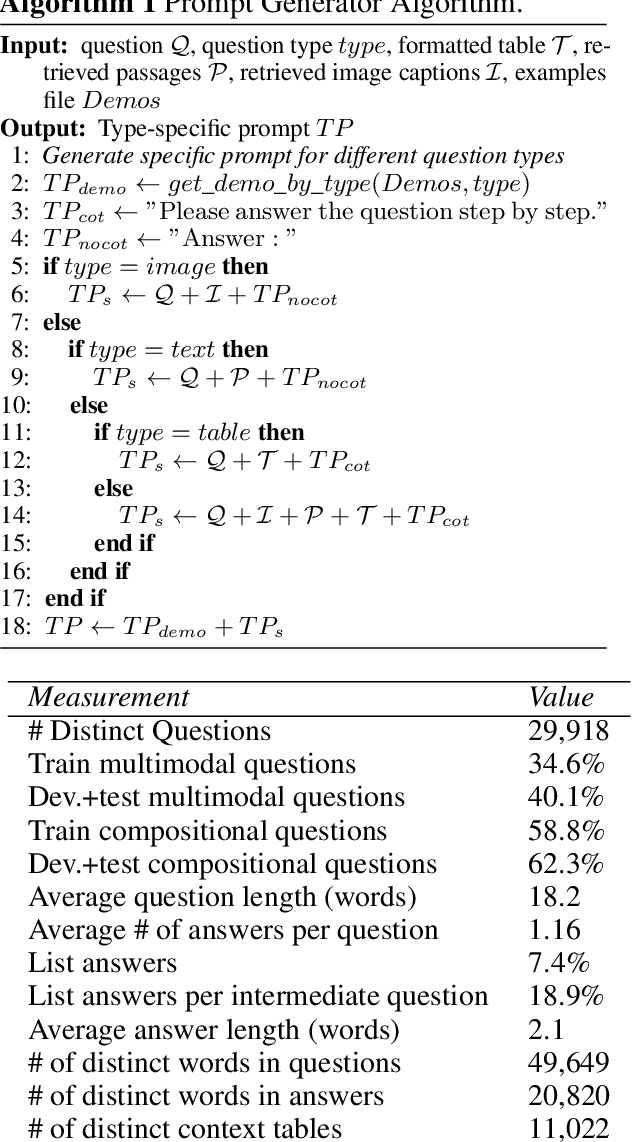
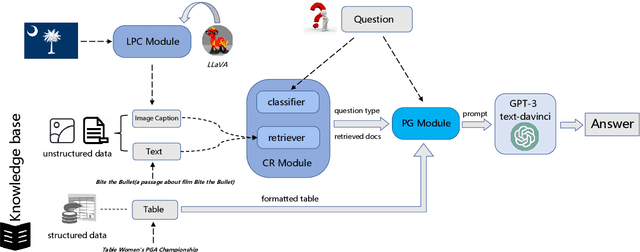

In the real world, knowledge often exists in a multimodal and heterogeneous form. Addressing the task of question answering with hybrid data types, including text, tables, and images, is a challenging task (MMHQA). Recently, with the rise of large language models (LLM), in-context learning (ICL) has become the most popular way to solve QA problems. We propose MMHQA-ICL framework for addressing this problems, which includes stronger heterogeneous data retriever and an image caption module. Most importantly, we propose a Type-specific In-context Learning Strategy for MMHQA, enabling LLMs to leverage their powerful performance in this task. We are the first to use end-to-end LLM prompting method for this task. Experimental results demonstrate that our framework outperforms all baselines and methods trained on the full dataset, achieving state-of-the-art results under the few-shot setting on the MultimodalQA dataset.