 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Comprehensive Stage-wise Benchmarking of Large Language Models in Fact-Checking
Jan 06, 2026Large Language Models (LLMs) are increasingly deployed in real-world fact-checking systems, yet existing evaluations focus predominantly on claim verification and overlook the broader fact-checking workflow, including claim extraction and evidence retrieval. This narrow focus prevents current benchmarks from revealing systematic reasoning failures, factual blind spots, and robustness limitations of modern LLMs. To bridge this gap, we present FactArena, a fully automated arena-style evaluation framework that conducts comprehensive, stage-wise benchmarking of LLMs across the complete fact-checking pipeline. FactArena integrates three key components: (i) an LLM-driven fact-checking process that standardizes claim decomposition, evidence retrieval via tool-augmented interactions, and justification-based verdict prediction; (ii) an arena-styled judgment mechanism guided by consolidated reference guidelines to ensure unbiased and consistent pairwise comparisons across heterogeneous judge agents; and (iii) an arena-driven claim-evolution module that adaptively generates more challenging and semantically controlled claims to probe LLMs' factual robustness beyond fixed seed data. Across 16 state-of-the-art LLMs spanning seven model families, FactArena produces stable and interpretable rankings. Our analyses further reveal significant discrepancies between static claim-verification accuracy and end-to-end fact-checking competence, highlighting the necessity of holistic evaluation. The proposed framework offers a scalable and trustworthy paradigm for diagnosing LLMs' factual reasoning, guiding future model development, and advancing the reliable deployment of LLMs in safety-critical fact-checking applications.
SportR: A Benchmark for Multimodal Large Language Model Reasoning in Sports
Nov 17, 2025Deeply understanding sports requires an intricate blend of fine-grained visual perception and rule-based reasoning - a challenge that pushes the limits of current multimodal models. To succeed, models must master three critical capabilities: perceiving nuanced visual details, applying abstract sport rule knowledge, and grounding that knowledge in specific visual evidence. Current sports benchmarks either cover single sports or lack the detailed reasoning chains and precise visual grounding needed to robustly evaluate these core capabilities in a multi-sport context. To address this gap, we introduce SportR, the first multi-sports large-scale benchmark designed to train and evaluate MLLMs on the fundamental reasoning required for sports intelligence. Our benchmark provides a dataset of 5,017 images and 2,101 videos. To enable granular evaluation, we structure our benchmark around a progressive hierarchy of question-answer (QA) pairs designed to probe reasoning at increasing depths - from simple infraction identification to complex penalty prediction. For the most advanced tasks requiring multi-step reasoning, such as determining penalties or explaining tactics, we provide 7,118 high-quality, human-authored Chain of Thought (CoT) annotations. In addition, our benchmark incorporates both image and video modalities and provides manual bounding box annotations to test visual grounding in the image part directly. Extensive experiments demonstrate the profound difficulty of our benchmark. State-of-the-art baseline models perform poorly on our most challenging tasks. While training on our data via Supervised Fine-Tuning and Reinforcement Learning improves these scores, they remain relatively low, highlighting a significant gap in current model capabilities. SportR presents a new challenge for the community, providing a critical resource to drive future research in multimodal sports reasoning.
DeepSport: A Multimodal Large Language Model for Comprehensive Sports Video Reasoning via Agentic Reinforcement Learning
Nov 17, 2025Sports video understanding presents unique challenges, requiring models to perceive high-speed dynamics, comprehend complex rules, and reason over long temporal contexts. While Multimodal Large Language Models (MLLMs) have shown promise in genral domains, the current state of research in sports remains narrowly focused: existing approaches are either single-sport centric, limited to specific tasks, or rely on training-free paradigms that lack robust, learned reasoning process. To address this gap, we introduce DeepSport, the first end-to-end trained MLLM framework designed for multi-task, multi-sport video understanding. DeepSport shifts the paradigm from passive frame processing to active, iterative reasoning, empowering the model to ``think with videos'' by dynamically interrogating content via a specialized frame-extraction tool. To enable this, we propose a data distillation pipeline that synthesizes high-quality Chain-of-Thought (CoT) trajectories from 10 diverse data source, creating a unified resource of 78k training data. We then employ a two-stage training strategy, Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) with a novel gated tool-use reward, to optimize the model's reasoning process. Extensive experiments on the testing benchmark of 6.7k questions demonstrate that DeepSport achieves state-of-the-art performance, significantly outperforming baselines of both proprietary model and open-source models. Our work establishes a new foundation for domain-specific video reasoning to address the complexities of diverse sports.
SpaceVista: All-Scale Visual Spatial Reasoning from mm to km
Oct 10, 2025With the current surge in spatial reasoning explorations, researchers have made significant progress in understanding indoor scenes, but still struggle with diverse applications such as robotics and autonomous driving. This paper aims to advance all-scale spatial reasoning across diverse scenarios by tackling two key challenges: 1) the heavy reliance on indoor 3D scans and labor-intensive manual annotations for dataset curation; 2) the absence of effective all-scale scene modeling, which often leads to overfitting to individual scenes. In this paper, we introduce a holistic solution that integrates a structured spatial reasoning knowledge system, scale-aware modeling, and a progressive training paradigm, as the first attempt to broaden the all-scale spatial intelligence of MLLMs to the best of our knowledge. Using a task-specific, specialist-driven automated pipeline, we curate over 38K video scenes across 5 spatial scales to create SpaceVista-1M, a dataset comprising approximately 1M spatial QA pairs spanning 19 diverse task types. While specialist models can inject useful domain knowledge, they are not reliable for evaluation. We then build an all-scale benchmark with precise annotations by manually recording, retrieving, and assembling video-based data. However, naive training with SpaceVista-1M often yields suboptimal results due to the potential knowledge conflict. Accordingly, we introduce SpaceVista-7B, a spatial reasoning model that accepts dense inputs beyond semantics and uses scale as an anchor for scale-aware experts and progressive rewards. Finally, extensive evaluations across 5 benchmarks, including our SpaceVista-Bench, demonstrate competitive performance, showcasing strong generalization across all scales and scenarios. Our dataset, model, and benchmark will be released on https://peiwensun2000.github.io/mm2km .
UnifiedVisual: A Framework for Constructing Unified Vision-Language Datasets
Sep 18, 2025Unified vision large language models (VLLMs) have recently achieved impressive advancements in both multimodal understanding and generation, powering applications such as visual question answering and text-guided image synthesis. However, progress in unified VLLMs remains constrained by the lack of datasets that fully exploit the synergistic potential between these two core abilities. Existing datasets typically address understanding and generation in isolation, thereby limiting the performance of unified VLLMs. To bridge this critical gap, we introduce a novel dataset construction framework, UnifiedVisual, and present UnifiedVisual-240K, a high-quality dataset meticulously designed to facilitate mutual enhancement between multimodal understanding and generation. UnifiedVisual-240K seamlessly integrates diverse visual and textual inputs and outputs, enabling comprehensive cross-modal reasoning and precise text-to-image alignment. Our dataset encompasses a wide spectrum of tasks and data sources, ensuring rich diversity and addressing key shortcomings of prior resources. Extensive experiments demonstrate that models trained on UnifiedVisual-240K consistently achieve strong performance across a wide range of tasks. Notably, these models exhibit significant mutual reinforcement between multimodal understanding and generation, further validating the effectiveness of our framework and dataset. We believe UnifiedVisual represents a new growth point for advancing unified VLLMs and unlocking their full potential. Our code and datasets is available at https://github.com/fnlp-vision/UnifiedVisual.
MSR-Codec: A Low-Bitrate Multi-Stream Residual Codec for High-Fidelity Speech Generation with Information Disentanglement
Sep 16, 2025Audio codecs are a critical component of modern speech generation systems. This paper introduces a low-bitrate, multi-scale residual codec that encodes speech into four distinct streams: semantic, timbre, prosody, and residual. This architecture achieves high-fidelity speech reconstruction at competitive low bitrates while demonstrating an inherent ability for information disentanglement. We construct a two-stage language model for text-to-speech (TTS) synthesis using this codec, which, despite its lightweight design and minimal data requirements, achieves a state-of-the-art Word Error Rate (WER) and superior speaker similarity compared to several larger models. Furthermore, the codec's design proves highly effective for voice conversion, enabling independent manipulation of speaker timbre and prosody.
Llasa+: Free Lunch for Accelerated and Streaming Llama-Based Speech Synthesis
Aug 08, 2025Recent progress in text-to-speech (TTS) has achieved impressive naturalness and flexibility, especially with the development of large language model (LLM)-based approaches. However, existing autoregressive (AR) structures and large-scale models, such as Llasa, still face significant challenges in inference latency and streaming synthesis. To deal with the limitations, we introduce Llasa+, an accelerated and streaming TTS model built on Llasa. Specifically, to accelerate the generation process, we introduce two plug-and-play Multi-Token Prediction (MTP) modules following the frozen backbone. These modules allow the model to predict multiple tokens in one AR step. Additionally, to mitigate potential error propagation caused by inaccurate MTP, we design a novel verification algorithm that leverages the frozen backbone to validate the generated tokens, thus allowing Llasa+ to achieve speedup without sacrificing generation quality. Furthermore, we design a causal decoder that enables streaming speech reconstruction from tokens. Extensive experiments show that Llasa+ achieves a 1.48X speedup without sacrificing generation quality, despite being trained only on LibriTTS. Moreover, the MTP-and-verification framework can be applied to accelerate any LLM-based model. All codes and models are publicly available at https://github.com/ASLP-lab/LLaSA_Plus.
AdamMeme: Adaptively Probe the Reasoning Capacity of Multimodal Large Language Models on Harmfulness
Jul 02, 2025The proliferation of multimodal memes in the social media era demands that multimodal Large Language Models (mLLMs) effectively understand meme harmfulness. Existing benchmarks for assessing mLLMs on harmful meme understanding rely on accuracy-based, model-agnostic evaluations using static datasets. These benchmarks are limited in their ability to provide up-to-date and thorough assessments, as online memes evolve dynamically. To address this, we propose AdamMeme, a flexible, agent-based evaluation framework that adaptively probes the reasoning capabilities of mLLMs in deciphering meme harmfulness. Through multi-agent collaboration, AdamMeme provides comprehensive evaluations by iteratively updating the meme data with challenging samples, thereby exposing specific limitations in how mLLMs interpret harmfulness. Extensive experiments show that our framework systematically reveals the varying performance of different target mLLMs, offering in-depth, fine-grained analyses of model-specific weaknesses. Our code is available at https://github.com/Lbotirx/AdamMeme.
Towards Omnidirectional Reasoning with 360-R1: A Dataset, Benchmark, and GRPO-based Method
May 20, 2025Omnidirectional images (ODIs), with their 360{\deg} field of view, provide unparalleled spatial awareness for immersive applications like augmented reality and embodied AI. However, the capability of existing multi-modal large language models (MLLMs) to comprehend and reason about such panoramic scenes remains underexplored. This paper addresses this gap by introducing OmniVQA, the first dataset and conducting the first benchmark for omnidirectional visual question answering. Our evaluation of state-of-the-art MLLMs reveals significant limitations in handling omnidirectional visual question answering, highlighting persistent challenges in object localization, feature extraction, and hallucination suppression within panoramic contexts. These results underscore the disconnect between current MLLM capabilities and the demands of omnidirectional visual understanding, which calls for dedicated architectural or training innovations tailored to 360{\deg} imagery. Building on the OmniVQA dataset and benchmark, we further introduce a rule-based reinforcement learning method, 360-R1, based on Qwen2.5-VL-Instruct. Concretely, we modify the group relative policy optimization (GRPO) by proposing three novel reward functions: (1) reasoning process similarity reward, (2) answer semantic accuracy reward, and (3) structured format compliance reward. Extensive experiments on our OmniVQA demonstrate the superiority of our proposed method in omnidirectional space (+6% improvement).
J1: Exploring Simple Test-Time Scaling for LLM-as-a-Judge
May 17, 2025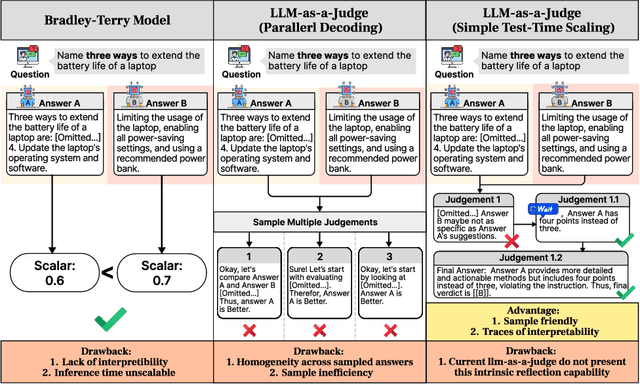
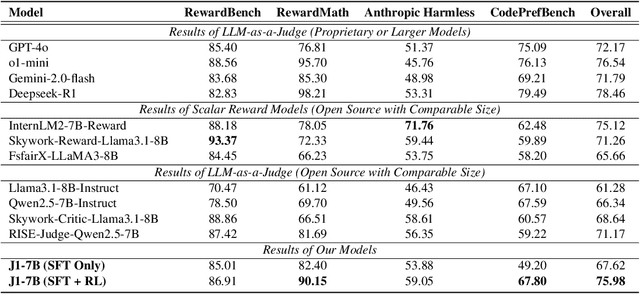
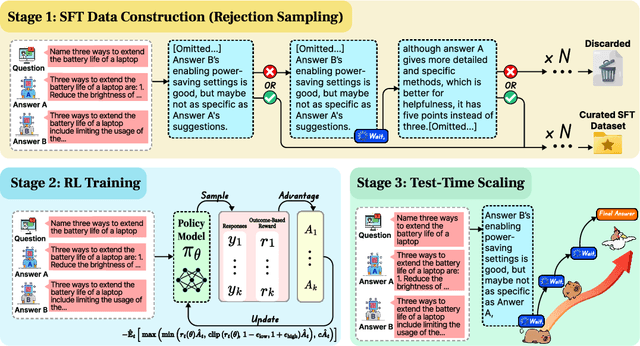
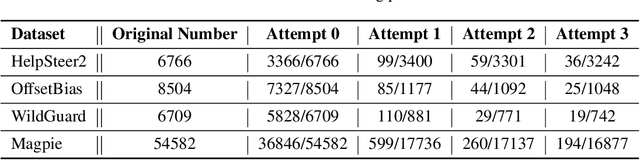
The current focus of AI research is shifting from emphasizing model training towards enhancing evaluation quality, a transition that is crucial for driving further advancements in AI systems. Traditional evaluation methods typically rely on reward models assigning scalar preference scores to outputs. Although effective, such approaches lack interpretability, leaving users often uncertain about why a reward model rates a particular response as high or low. The advent of LLM-as-a-Judge provides a more scalable and interpretable method of supervision, offering insights into the decision-making process. Moreover, with the emergence of large reasoning models, which consume more tokens for deeper thinking and answer refinement, scaling test-time computation in the LLM-as-a-Judge paradigm presents an avenue for further boosting performance and providing more interpretability through reasoning traces. In this paper, we introduce $\textbf{J1-7B}$, which is first supervised fine-tuned on reflection-enhanced datasets collected via rejection-sampling and subsequently trained using Reinforcement Learning (RL) with verifiable rewards. At inference time, we apply Simple Test-Time Scaling (STTS) strategies for additional performance improvement. Experimental results demonstrate that $\textbf{J1-7B}$ surpasses the previous state-of-the-art LLM-as-a-Judge by $ \textbf{4.8}$\% and exhibits a $ \textbf{5.1}$\% stronger scaling trend under STTS. Additionally, we present three key findings: (1) Existing LLM-as-a-Judge does not inherently exhibit such scaling trend. (2) Model simply fine-tuned on reflection-enhanced datasets continues to demonstrate similarly weak scaling behavior. (3) Significant scaling trend emerges primarily during the RL phase, suggesting that effective STTS capability is acquired predominantly through RL training.