 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
P-norm based Fractional-Order Robust Subband Adaptive Filtering Algorithm for Impulsive Noise and Noisy Input
Jan 15, 2026Building upon the mean p-power error (MPE) criterion, the normalized subband p-norm (NSPN) algorithm demonstrates superior robustness in $α$-stable noise environments ($1 < α\leq 2$) through effective utilization of low-order moment hidden in robust loss functions. Nevertheless, its performance degrades significantly when processing noise input or additive noise characterized by $α$-stable processes ($0 < α\leq 1$). To overcome these limitations, we propose a novel fractional-order NSPN (FoNSPN) algorithm that incorporates the fractional-order stochastic gradient descent (FoSGD) method into the MPE framework. Additionally, this paper also analyzes the convergence range of its step-size, the theoretical domain of values for the fractional-order $β$, and establishes the theoretical steady-state mean square deviation (MSD) model. Simulations conducted in diverse impulsive noise environments confirm the superiority of the proposed FoNSPN algorithm against existing state-of-the-art algorithms.
* 5 pages, 4 figures, published to IEEE SPL
Skywork UniPic 2.0: Building Kontext Model with Online RL for Unified Multimodal Model
Sep 04, 2025

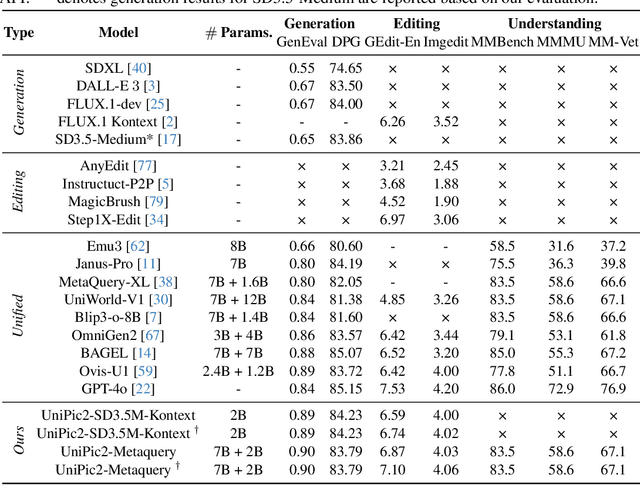
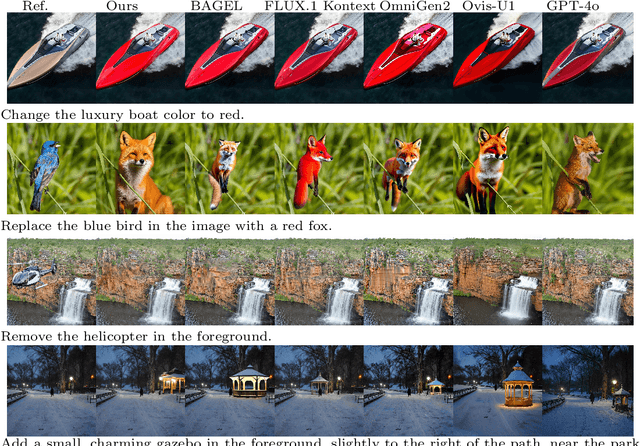
Recent advances in multimodal models have demonstrated impressive capabilities in unified image generation and editing. However, many prominent open-source models prioritize scaling model parameters over optimizing training strategies, limiting their efficiency and performance. In this work, we present UniPic2-SD3.5M-Kontext, a 2B-parameter DiT model based on SD3.5-Medium, which achieves state-of-the-art image generation and editing while extending seamlessly into a unified multimodal framework. Our approach begins with architectural modifications to SD3.5-Medium and large-scale pre-training on high-quality data, enabling joint text-to-image generation and editing capabilities. To enhance instruction following and editing consistency, we propose a novel Progressive Dual-Task Reinforcement strategy (PDTR), which effectively strengthens both tasks in a staged manner. We empirically validate that the reinforcement phases for different tasks are mutually beneficial and do not induce negative interference. After pre-training and reinforcement strategies, UniPic2-SD3.5M-Kontext demonstrates stronger image generation and editing capabilities than models with significantly larger generation parameters-including BAGEL (7B) and Flux-Kontext (12B). Furthermore, following the MetaQuery, we connect the UniPic2-SD3.5M-Kontext and Qwen2.5-VL-7B via a connector and perform joint training to launch a unified multimodal model UniPic2-Metaquery. UniPic2-Metaquery integrates understanding, generation, and editing, achieving top-tier performance across diverse tasks with a simple and scalable training paradigm. This consistently validates the effectiveness and generalizability of our proposed training paradigm, which we formalize as Skywork UniPic 2.0.
Skywork-R1V3 Technical Report
Jul 09, 2025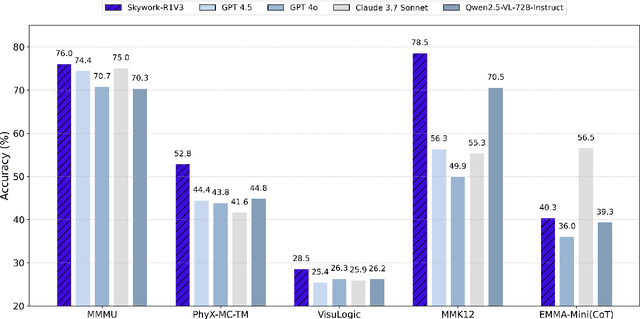
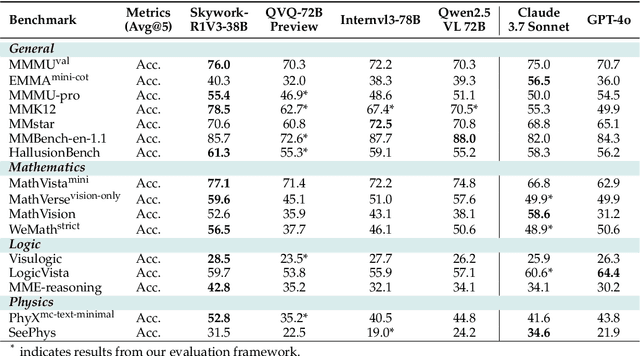
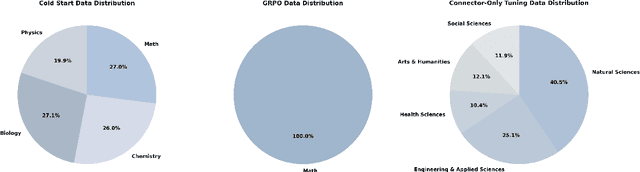

We introduce Skywork-R1V3, an advanced, open-source vision-language model (VLM) that pioneers a new approach to visual reasoning. Its key innovation lies in effectively transferring reasoning skills from text-only Large Language Models (LLMs) to visual tasks. The strong performance of Skywork-R1V3 primarily stems from our elaborate post-training RL framework, which effectively activates and enhances the model's reasoning ability, without the need for additional continue pre-training. Through this framework, we further uncover the fundamental role of the connector module in achieving robust cross-modal alignment for multimodal reasoning models. In addition, we introduce a unique indicator of reasoning capability, the entropy of critical reasoning tokens, which has proven highly effective for checkpoint selection during RL training. Skywork-R1V3 achieves state-of-the-art results on MMMU, significantly improving from 64.3% to 76.0%. This performance matches entry-level human capabilities. Remarkably, our RL-powered post-training approach enables even the 38B parameter model to rival top closed-source VLMs. The implementation successfully transfers mathematical reasoning to other subject-related reasoning tasks. We also include an analysis of curriculum learning and reinforcement finetuning strategies, along with a broader discussion on multimodal reasoning. Skywork-R1V3 represents a significant leap in multimodal reasoning, showcasing RL as a powerful engine for advancing open-source VLM capabilities.
CSVQA: A Chinese Multimodal Benchmark for Evaluating STEM Reasoning Capabilities of VLMs
May 30, 2025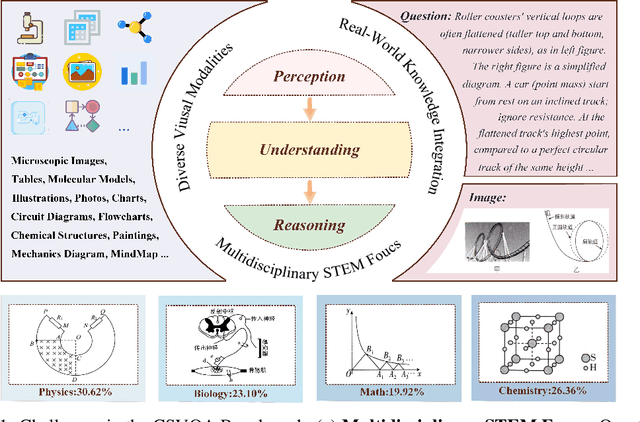
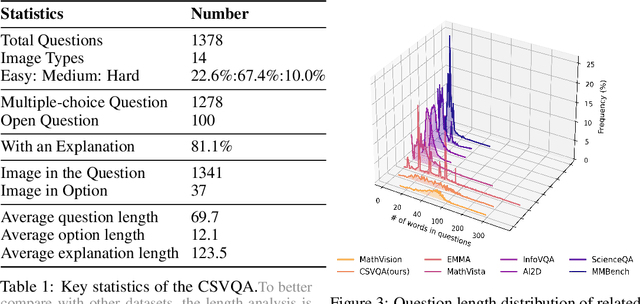
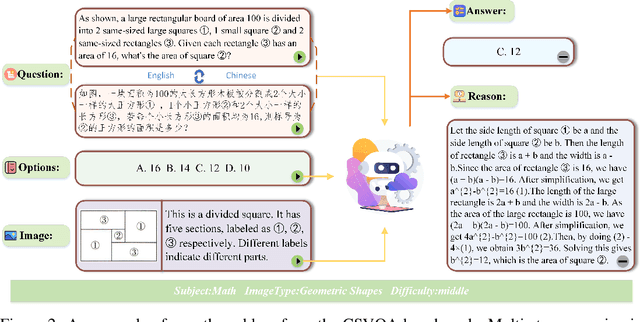
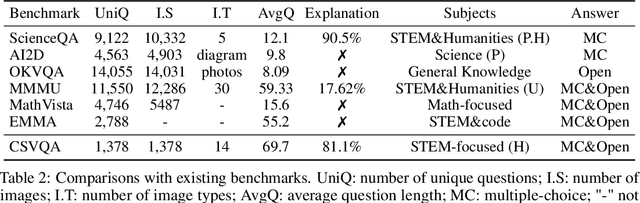
Vision-Language Models (VLMs) have demonstrated remarkable progress in multimodal understanding, yet their capabilities for scientific reasoning remains inadequately assessed. Current multimodal benchmarks predominantly evaluate generic image comprehension or text-driven reasoning, lacking authentic scientific contexts that require domain-specific knowledge integration with visual evidence analysis. To fill this gap, we present CSVQA, a diagnostic multimodal benchmark specifically designed for evaluating scientific reasoning through domain-grounded visual question answering.Our benchmark features 1,378 carefully constructed question-answer pairs spanning diverse STEM disciplines, each demanding domain knowledge, integration of visual evidence, and higher-order reasoning. Compared to prior multimodal benchmarks, CSVQA places greater emphasis on real-world scientific content and complex reasoning.We additionally propose a rigorous evaluation protocol to systematically assess whether model predictions are substantiated by valid intermediate reasoning steps based on curated explanations. Our comprehensive evaluation of 15 VLMs on this benchmark reveals notable performance disparities, as even the top-ranked proprietary model attains only 49.6\% accuracy.This empirical evidence underscores the pressing need for advancing scientific reasoning capabilities in VLMs. Our CSVQA is released at https://huggingface.co/datasets/Skywork/CSVQA.
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
May 28, 2025Recent advancements in image generative foundation models have prioritized quality improvements but often at the cost of increased computational complexity and inference latency. To address this critical trade-off, we introduce HiDream-I1, a new open-source image generative foundation model with 17B parameters that achieves state-of-the-art image generation quality within seconds. HiDream-I1 is constructed with a new sparse Diffusion Transformer (DiT) structure. Specifically, it starts with a dual-stream decoupled design of sparse DiT with dynamic Mixture-of-Experts (MoE) architecture, in which two separate encoders are first involved to independently process image and text tokens. Then, a single-stream sparse DiT structure with dynamic MoE architecture is adopted to trigger multi-model interaction for image generation in a cost-efficient manner. To support flexiable accessibility with varied model capabilities, we provide HiDream-I1 in three variants: HiDream-I1-Full, HiDream-I1-Dev, and HiDream-I1-Fast. Furthermore, we go beyond the typical text-to-image generation and remould HiDream-I1 with additional image conditions to perform precise, instruction-based editing on given images, yielding a new instruction-based image editing model namely HiDream-E1. Ultimately, by integrating text-to-image generation and instruction-based image editing, HiDream-I1 evolves to form a comprehensive image agent (HiDream-A1) capable of fully interactive image creation and refinement. To accelerate multi-modal AIGC research, we have open-sourced all the codes and model weights of HiDream-I1-Full, HiDream-I1-Dev, HiDream-I1-Fast, HiDream-E1 through our project websites: https://github.com/HiDream-ai/HiDream-I1 and https://github.com/HiDream-ai/HiDream-E1. All features can be directly experienced via https://vivago.ai/studio.
Skywork-VL Reward: An Effective Reward Model for Multimodal Understanding and Reasoning
May 12, 2025We propose Skywork-VL Reward, a multimodal reward model that provides reward signals for both multimodal understanding and reasoning tasks. Our technical approach comprises two key components: First, we construct a large-scale multimodal preference dataset that covers a wide range of tasks and scenarios, with responses collected from both standard vision-language models (VLMs) and advanced VLM reasoners. Second, we design a reward model architecture based on Qwen2.5-VL-7B-Instruct, integrating a reward head and applying multi-stage fine-tuning using pairwise ranking loss on pairwise preference data. Experimental evaluations show that Skywork-VL Reward achieves state-of-the-art results on multimodal VL-RewardBench and exhibits competitive performance on the text-only RewardBench benchmark. Furthermore, preference data constructed based on our Skywork-VL Reward proves highly effective for training Mixed Preference Optimization (MPO), leading to significant improvements in multimodal reasoning capabilities. Our results underscore Skywork-VL Reward as a significant advancement toward general-purpose, reliable reward models for multimodal alignment. Our model has been publicly released to promote transparency and reproducibility.
Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Apr 23, 2025We present Skywork R1V2, a next-generation multimodal reasoning model and a major leap forward from its predecessor, Skywork R1V. At its core, R1V2 introduces a hybrid reinforcement learning paradigm that harmonizes reward-model guidance with rule-based strategies, thereby addressing the long-standing challenge of balancing sophisticated reasoning capabilities with broad generalization. To further enhance training efficiency, we propose the Selective Sample Buffer (SSB) mechanism, which effectively counters the ``Vanishing Advantages'' dilemma inherent in Group Relative Policy Optimization (GRPO) by prioritizing high-value samples throughout the optimization process. Notably, we observe that excessive reinforcement signals can induce visual hallucinations--a phenomenon we systematically monitor and mitigate through calibrated reward thresholds throughout the training process. Empirical results affirm the exceptional capability of R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 79.0 on AIME2024, 63.6 on LiveCodeBench, and 74.0 on MMMU. These results underscore R1V2's superiority over existing open-source models and demonstrate significant progress in closing the performance gap with premier proprietary systems, including Gemini 2.5 and OpenAI o4-mini. The Skywork R1V2 model weights have been publicly released to promote openness and reproducibility https://huggingface.co/Skywork/Skywork-R1V2-38B.
Diffusion Augmented Complex Maximum Total Correntropy Algorithm for Power System Frequency Estimation
Apr 10, 2025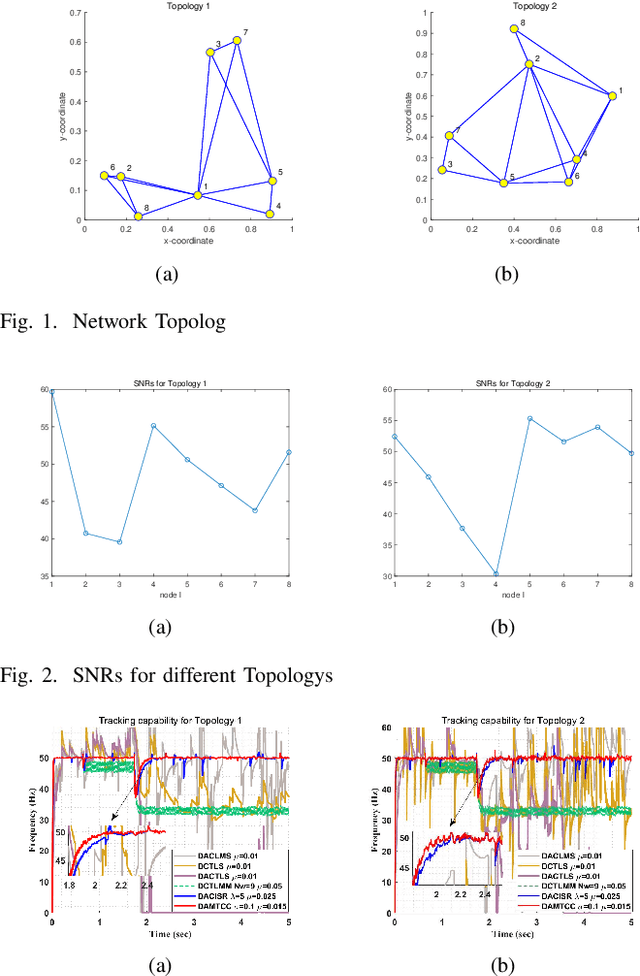
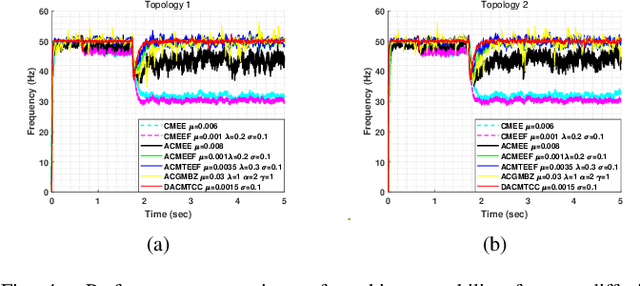
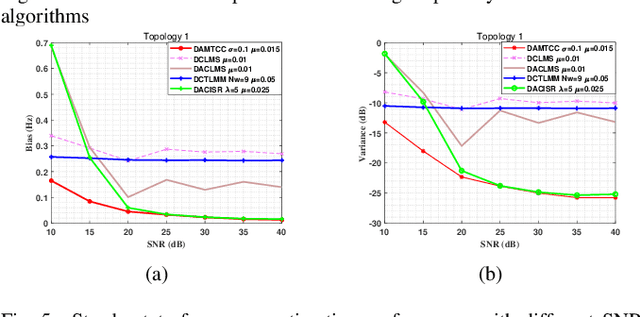
Currently, adaptive filtering algorithms have been widely applied in frequency estimation for power systems. However, research on diffusion tasks remains insufficient. Existing diffusion adaptive frequency estimation algorithms exhibit certain limitations in handling input noise and lack robustness against impulsive noise. Moreover, traditional adaptive filtering algorithms designed based on the strictly-linear (SL) model fail to effectively address frequency estimation challenges in unbalanced three-phase power systems. To address these issues, this letter proposes an improved diffusion augmented complex maximum total correntropy (DAMTCC) algorithm based on the widely linear (WL) model. The proposed algorithm not only significantly enhances the capability to handle input noise but also demonstrates superior robustness to impulsive noise. Furthermore, it successfully resolves the critical challenge of frequency estimation in unbalanced three-phase power systems, offering an efficient and reliable solution for diffusion power system frequency estimation. Finally, we analyze the stability of the algorithm and computer simulations verify the excellent performance of the algorithm.
Skywork R1V: Pioneering Multimodal Reasoning with Chain-of-Thought
Apr 08, 2025We introduce Skywork R1V, a multimodal reasoning model extending the an R1-series Large language models (LLM) to visual modalities via an efficient multimodal transfer method. Leveraging a lightweight visual projector, Skywork R1V facilitates seamless multimodal adaptation without necessitating retraining of either the foundational language model or the vision encoder. To strengthen visual-text alignment, we propose a hybrid optimization strategy that combines Iterative Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), significantly enhancing cross-modal integration efficiency. Additionally, we introduce an adaptive-length Chain-of-Thought distillation approach for reasoning data generation. This approach dynamically optimizes reasoning chain lengths, thereby enhancing inference efficiency and preventing excessive reasoning overthinking. Empirical evaluations demonstrate that Skywork R1V, with only 38B parameters, delivers competitive performance, achieving a score of 69.0 on the MMMU benchmark and 67.5 on MathVista. Meanwhile, it maintains robust textual reasoning performance, evidenced by impressive scores of 72.0 on AIME and 94.0 on MATH500. The Skywork R1V model weights have been publicly released to promote openness and reproducibility.