 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUME: Latent Reasoning Based Universal Multimodal Embedding
Apr 02, 2026Universal multimodal embedding (UME) maps heterogeneous inputs into a shared retrieval space with a single model. Recent approaches improve UME by generating explicit chain-of-thought (CoT) rationales before extracting embeddings, enabling multimodal large language models to better infer complex query intent. However, explicit CoT incurs substantial inference overhead and can compress rich multimodal evidence into a narrow textual bottleneck. We propose PLUME, a latent reasoning framework that advances UME by replacing verbalized CoT with a short autoregressive rollout of continuous latent states. To support diverse multimodal queries, PLUME further introduces a semantic-anchor-guided transition adapter that steers latent rollout along different reasoning trajectories under the same fixed computation budget. To stabilize training, PLUME adopts a progressive explicit-to-latent curriculum that uses verbalized reasoning only as a temporary training scaffold and gradually transfers this behavior into hidden-state computation, eliminating explicit CoT at inference. On the 78-task MMEB-v2 benchmark, PLUME outperforms strong explicit-CoT UME baselines while reducing reasoning from hundreds of generated tokens to fewer than 10 latent steps, delivering over 30x faster inference. PLUME is especially well suited to retrieval settings where relevant evidence is dense, structurally complex, and difficult to organize through verbalized intermediate rationales, such as video and visual document retrieval. These results show that structured latent computation can preserve the benefits of intermediate reasoning without the overhead of explicit rationale generation, providing a stronger and more efficient paradigm for practical retrieval systems.
Listening with the Eyes: Benchmarking Egocentric Co-Speech Grounding across Space and Time
Mar 09, 2026In situated collaboration, speakers often use intentionally underspecified deictic commands (e.g., ``pass me \textit{that}''), whose referent becomes identifiable only by aligning speech with a brief co-speech pointing \emph{stroke}. However, many embodied benchmarks admit language-only shortcuts, allowing MLLMs to perform well without learning the \emph{audio--visual alignment} required by deictic interaction. To bridge this gap, we introduce \textbf{Egocentric Co-Speech Grounding (EcoG)}, where grounding is executable only if an agent jointly predicts \textit{What}, \textit{Where}, and \textit{When}. To operationalize this, we present \textbf{EcoG-Bench}, an evaluation-only bilingual (EN/ZH) diagnostic benchmark of \textbf{811} egocentric clips with dense spatial annotations and millisecond-level stroke supervision. It is organized under a \textbf{Progressive Cognitive Evaluation} protocol. Benchmarking state-of-the-art MLLMs reveals a severe executability gap: while human subjects achieve near-ceiling performance on EcoG-Bench (\textbf{96.9\%} strict Eco-Accuracy), the best native video-audio setting remains low (Gemini-3-Pro: \textbf{17.0\%}). Moreover, in a diagnostic ablation, replacing the native video--audio interface with timestamped frame samples and externally verified ASR (with word-level timing) substantially improves the same model (\textbf{17.0\%}$\to$\textbf{42.9\%}). Overall, EcoG-Bench provides a strict, executable testbed for event-level speech--gesture binding, and suggests that multimodal interfaces may bottleneck the observability of temporal alignment cues, independently of model reasoning.
ESearch-R1: Learning Cost-Aware MLLM Agents for Interactive Embodied Search via Reinforcement Learning
Dec 21, 2025Multimodal Large Language Models (MLLMs) have empowered embodied agents with remarkable capabilities in planning and reasoning. However, when facing ambiguous natural language instructions (e.g., "fetch the tool" in a cluttered room), current agents often fail to balance the high cost of physical exploration against the cognitive cost of human interaction. They typically treat disambiguation as a passive perception problem, lacking the strategic reasoning to minimize total task execution costs. To bridge this gap, we propose ESearch-R1, a cost-aware embodied reasoning framework that unifies interactive dialogue (Ask), episodic memory retrieval (GetMemory), and physical navigation (Navigate) into a single decision process. We introduce HC-GRPO (Heterogeneous Cost-Aware Group Relative Policy Optimization). Unlike traditional PPO which relies on a separate value critic, HC-GRPO optimizes the MLLM by sampling groups of reasoning trajectories and reinforcing those that achieve the optimal trade-off between information gain and heterogeneous costs (e.g., navigate time, and human attention). Extensive experiments in AI2-THOR demonstrate that ESearch-R1 significantly outperforms standard ReAct-based agents. It improves task success rates while reducing total operational costs by approximately 50\%, validating the effectiveness of GRPO in aligning MLLM agents with physical world constraints.
UniBYD: A Unified Framework for Learning Robotic Manipulation Across Embodiments Beyond Imitation of Human Demonstrations
Dec 12, 2025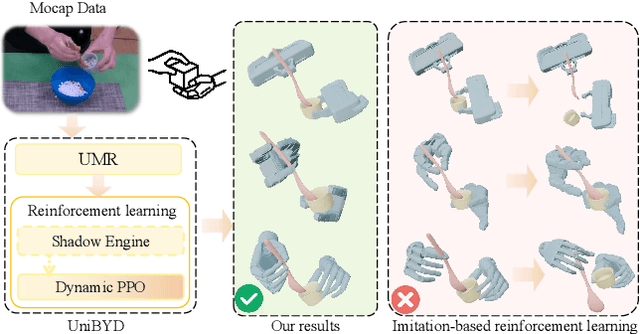
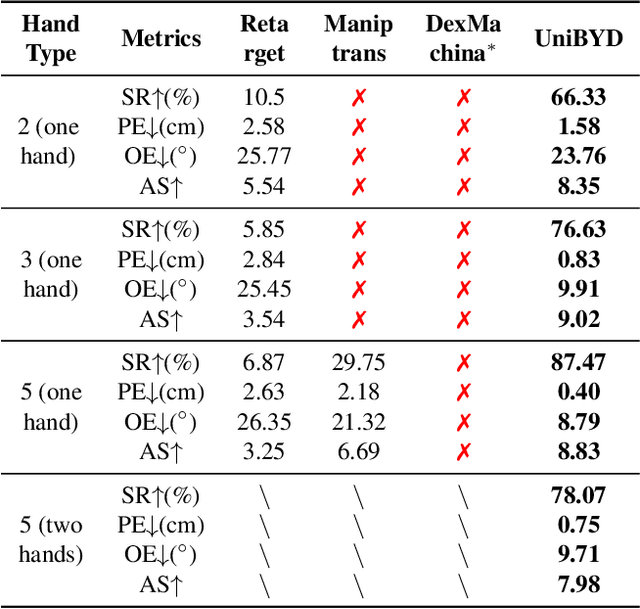
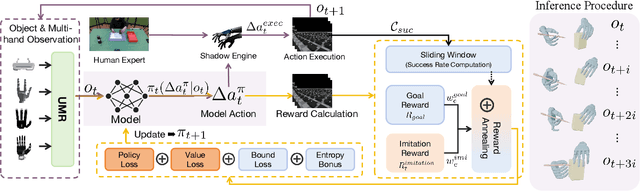
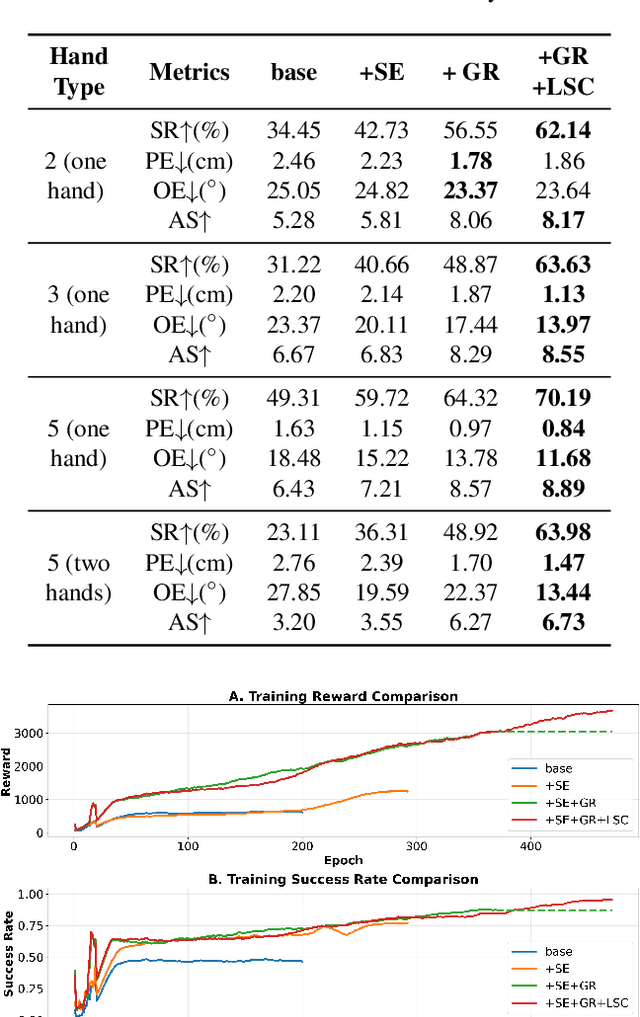
In embodied intelligence, the embodiment gap between robotic and human hands brings significant challenges for learning from human demonstrations. Although some studies have attempted to bridge this gap using reinforcement learning, they remain confined to merely reproducing human manipulation, resulting in limited task performance. In this paper, we propose UniBYD, a unified framework that uses a dynamic reinforcement learning algorithm to discover manipulation policies aligned with the robot's physical characteristics. To enable consistent modeling across diverse robotic hand morphologies, UniBYD incorporates a unified morphological representation (UMR). Building on UMR, we design a dynamic PPO with an annealed reward schedule, enabling reinforcement learning to transition from imitation of human demonstrations to explore policies adapted to diverse robotic morphologies better, thereby going beyond mere imitation of human hands. To address the frequent failures of learning human priors in the early training stage, we design a hybrid Markov-based shadow engine that enables reinforcement learning to imitate human manipulations in a fine-grained manner. To evaluate UniBYD comprehensively, we propose UniManip, the first benchmark encompassing robotic manipulation tasks spanning multiple hand morphologies. Experiments demonstrate a 67.90% improvement in success rate over the current state-of-the-art. Upon acceptance of the paper, we will release our code and benchmark at https://github.com/zhanheng-creator/UniBYD.
GenPilot: A Multi-Agent System for Test-Time Prompt Optimization in Image Generation
Oct 08, 2025Text-to-image synthesis has made remarkable progress, yet accurately interpreting complex and lengthy prompts remains challenging, often resulting in semantic inconsistencies and missing details. Existing solutions, such as fine-tuning, are model-specific and require training, while prior automatic prompt optimization (APO) approaches typically lack systematic error analysis and refinement strategies, resulting in limited reliability and effectiveness. Meanwhile, test-time scaling methods operate on fixed prompts and on noise or sample numbers, limiting their interpretability and adaptability. To solve these, we introduce a flexible and efficient test-time prompt optimization strategy that operates directly on the input text. We propose a plug-and-play multi-agent system called GenPilot, integrating error analysis, clustering-based adaptive exploration, fine-grained verification, and a memory module for iterative optimization. Our approach is model-agnostic, interpretable, and well-suited for handling long and complex prompts. Simultaneously, we summarize the common patterns of errors and the refinement strategy, offering more experience and encouraging further exploration. Experiments on DPG-bench and Geneval with improvements of up to 16.9% and 5.7% demonstrate the strong capability of our methods in enhancing the text and image consistency and structural coherence of generated images, revealing the effectiveness of our test-time prompt optimization strategy. The code is available at https://github.com/27yw/GenPilot.
PhysVLM: Enabling Visual Language Models to Understand Robotic Physical Reachability
Mar 13, 2025Understanding the environment and a robot's physical reachability is crucial for task execution. While state-of-the-art vision-language models (VLMs) excel in environmental perception, they often generate inaccurate or impractical responses in embodied visual reasoning tasks due to a lack of understanding of robotic physical reachability. To address this issue, we propose a unified representation of physical reachability across diverse robots, i.e., Space-Physical Reachability Map (S-P Map), and PhysVLM, a vision-language model that integrates this reachability information into visual reasoning. Specifically, the S-P Map abstracts a robot's physical reachability into a generalized spatial representation, independent of specific robot configurations, allowing the model to focus on reachability features rather than robot-specific parameters. Subsequently, PhysVLM extends traditional VLM architectures by incorporating an additional feature encoder to process the S-P Map, enabling the model to reason about physical reachability without compromising its general vision-language capabilities. To train and evaluate PhysVLM, we constructed a large-scale multi-robot dataset, Phys100K, and a challenging benchmark, EQA-phys, which includes tasks for six different robots in both simulated and real-world environments. Experimental results demonstrate that PhysVLM outperforms existing models, achieving a 14\% improvement over GPT-4o on EQA-phys and surpassing advanced embodied VLMs such as RoboMamba and SpatialVLM on the RoboVQA-val and OpenEQA benchmarks. Additionally, the S-P Map shows strong compatibility with various VLMs, and its integration into GPT-4o-mini yields a 7.1\% performance improvement.
LightPlanner: Unleashing the Reasoning Capabilities of Lightweight Large Language Models in Task Planning
Mar 11, 2025
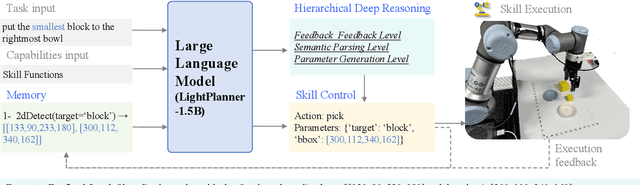

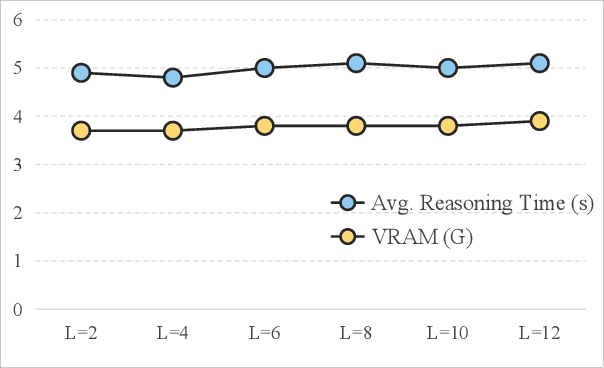
In recent years, lightweight large language models (LLMs) have garnered significant attention in the robotics field due to their low computational resource requirements and suitability for edge deployment. However, in task planning -- particularly for complex tasks that involve dynamic semantic logic reasoning -- lightweight LLMs have underperformed. To address this limitation, we propose a novel task planner, LightPlanner, which enhances the performance of lightweight LLMs in complex task planning by fully leveraging their reasoning capabilities. Unlike conventional planners that use fixed skill templates, LightPlanner controls robot actions via parameterized function calls, dynamically generating parameter values. This approach allows for fine-grained skill control and improves task planning success rates in complex scenarios. Furthermore, we introduce hierarchical deep reasoning. Before generating each action decision step, LightPlanner thoroughly considers three levels: action execution (feedback verification), semantic parsing (goal consistency verification), and parameter generation (parameter validity verification). This ensures the correctness of subsequent action controls. Additionally, we incorporate a memory module to store historical actions, thereby reducing context length and enhancing planning efficiency for long-term tasks. We train the LightPlanner-1.5B model on our LightPlan-40k dataset, which comprises 40,000 action controls across tasks with 2 to 13 action steps. Experiments demonstrate that our model achieves the highest task success rate despite having the smallest number of parameters. In tasks involving spatial semantic reasoning, the success rate exceeds that of ReAct by 14.9 percent. Moreover, we demonstrate LightPlanner's potential to operate on edge devices.
Mitigating Hallucination in Visual Language Models with Visual Supervision
Nov 27, 2023



Large vision-language models (LVLMs) suffer from hallucination a lot, generating responses that apparently contradict to the image content occasionally. The key problem lies in its weak ability to comprehend detailed content in a multi-modal context, which can be mainly attributed to two factors in training data and loss function. The vision instruction dataset primarily focuses on global description, and the auto-regressive loss function favors text modeling rather than image understanding. In this paper, we bring more detailed vision annotations and more discriminative vision models to facilitate the training of LVLMs, so that they can generate more precise responses without encounter hallucination. On one hand, we generate image-text pairs with detailed relationship annotations in panoptic scene graph dataset (PSG). These conversations pay more attention on detailed facts in the image, encouraging the model to answer questions based on multi-modal contexts. On the other hand, we integrate SAM and mask prediction loss as auxiliary supervision, forcing the LVLMs to have the capacity to identify context-related objects, so that they can generate more accurate responses, mitigating hallucination. Moreover, to provide a deeper evaluation on the hallucination in LVLMs, we propose a new benchmark, RAH-Bench. It divides vision hallucination into three different types that contradicts the image with wrong categories, attributes or relations, and introduces False Positive Rate as detailed sub-metric for each type. In this benchmark, our approach demonstrates an +8.4% enhancement compared to original LLaVA and achieves widespread performance improvements across other models.
ZBS: Zero-shot Background Subtraction via Instance-level Background Modeling and Foreground Selection
Mar 26, 2023
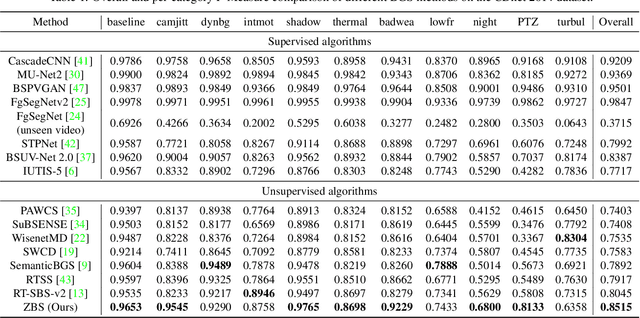
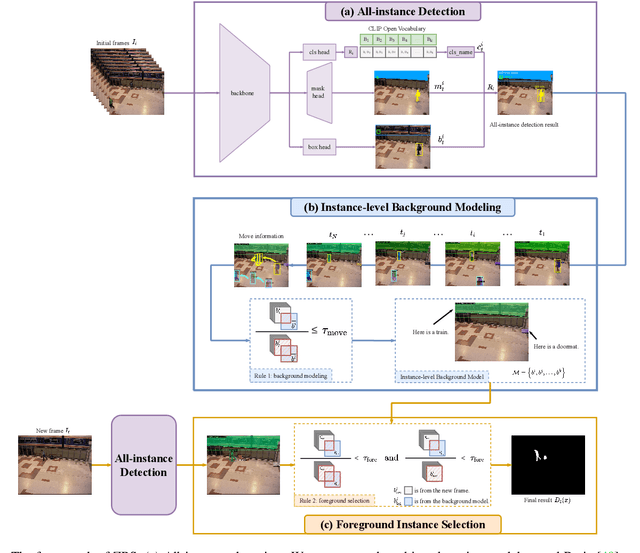
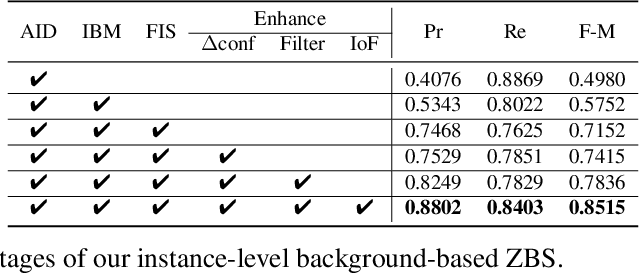
Background subtraction (BGS) aims to extract all moving objects in the video frames to obtain binary foreground segmentation masks. Deep learning has been widely used in this field. Compared with supervised-based BGS methods, unsupervised methods have better generalization. However, previous unsupervised deep learning BGS algorithms perform poorly in sophisticated scenarios such as shadows or night lights, and they cannot detect objects outside the pre-defined categories. In this work, we propose an unsupervised BGS algorithm based on zero-shot object detection called Zero-shot Background Subtraction (ZBS). The proposed method fully utilizes the advantages of zero-shot object detection to build the open-vocabulary instance-level background model. Based on it, the foreground can be effectively extracted by comparing the detection results of new frames with the background model. ZBS performs well for sophisticated scenarios, and it has rich and extensible categories. Furthermore, our method can easily generalize to other tasks, such as abandoned object detection in unseen environments. We experimentally show that ZBS surpasses state-of-the-art unsupervised BGS methods by 4.70% F-Measure on the CDnet 2014 dataset. The code is released at https://github.com/CASIA-IVA-Lab/ZBS.
Efficient Masked Autoencoders with Self-Consistency
Feb 28, 2023
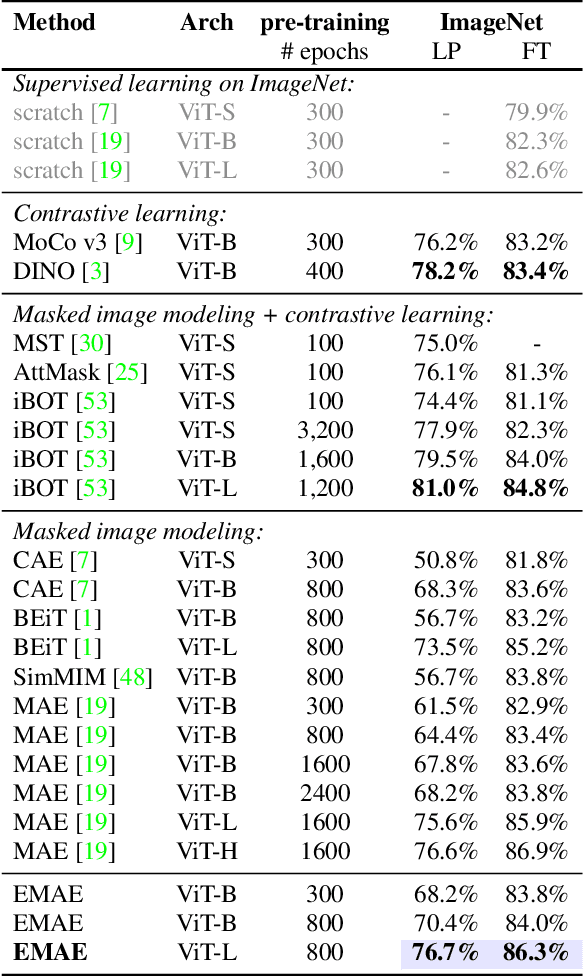
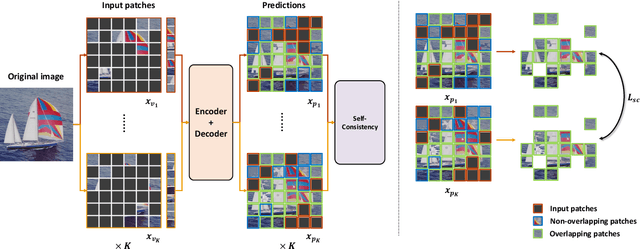
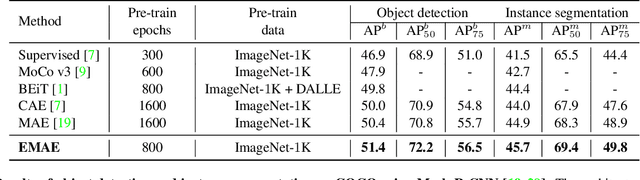
Inspired by masked language modeling (MLM) in natural language processing, masked image modeling (MIM) has been recognized as a strong and popular self-supervised pre-training method in computer vision. However, its high random mask ratio would result in two serious problems: 1) the data are not efficiently exploited, which brings inefficient pre-training (\eg, 1600 epochs for MAE $vs.$ 300 epochs for the supervised), and 2) the high uncertainty and inconsistency of the pre-trained model, \ie, the prediction of the same patch may be inconsistent under different mask rounds. To tackle these problems, we propose efficient masked autoencoders with self-consistency (EMAE), to improve the pre-training efficiency and increase the consistency of MIM. In particular, we progressively divide the image into K non-overlapping parts, each of which is generated by a random mask and has the same mask ratio. Then the MIM task is conducted parallelly on all parts in an iteration and generates predictions. Besides, we design a self-consistency module to further maintain the consistency of predictions of overlapping masked patches among parts. Overall, the proposed method is able to exploit the data more efficiently and obtains reliable representations. Experiments on ImageNet show that EMAE achieves even higher results with only 300 pre-training epochs under ViT-Base than MAE (1600 epochs). EMAE also consistently obtains state-of-the-art transfer performance on various downstream tasks, like object detection, and semantic segmentation.