 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization in LLM Structured Pruning via Function-Aware Neuron Grouping
Dec 28, 2025Large Language Models (LLMs) demonstrate impressive performance across natural language tasks but incur substantial computational and storage costs due to their scale. Post-training structured pruning offers an efficient solution. However, when few-shot calibration sets fail to adequately reflect the pretraining data distribution, existing methods exhibit limited generalization to downstream tasks. To address this issue, we propose Function-Aware Neuron Grouping (FANG), a post-training pruning framework that alleviates calibration bias by identifying and preserving neurons critical to specific function. FANG groups neurons with similar function based on the type of semantic context they process and prunes each group independently. During importance estimation within each group, tokens that strongly correlate with the functional role of the neuron group are given higher weighting. Additionally, FANG also preserves neurons that contribute across multiple context types. To achieve a better trade-off between sparsity and performance, it allocates sparsity to each block adaptively based on its functional complexity. Experiments show that FANG improves downstream accuracy while preserving language modeling performance. It achieves the state-of-the-art (SOTA) results when combined with FLAP and OBC, two representative pruning methods. Specifically, FANG outperforms FLAP and OBC by 1.5%--8.5% in average accuracy under 30% and 40% sparsity.
Scaling Linear Attention with Sparse State Expansion
Jul 22, 2025The Transformer architecture, despite its widespread success, struggles with long-context scenarios due to quadratic computation and linear memory growth. While various linear attention variants mitigate these efficiency constraints by compressing context into fixed-size states, they often degrade performance in tasks such as in-context retrieval and reasoning. To address this limitation and achieve more effective context compression, we propose two key innovations. First, we introduce a row-sparse update formulation for linear attention by conceptualizing state updating as information classification. This enables sparse state updates via softmax-based top-$k$ hard classification, thereby extending receptive fields and reducing inter-class interference. Second, we present Sparse State Expansion (SSE) within the sparse framework, which expands the contextual state into multiple partitions, effectively decoupling parameter size from state capacity while maintaining the sparse classification paradigm. Our design, supported by efficient parallelized implementations, yields effective classification and discriminative state representations. We extensively validate SSE in both pure linear and hybrid (SSE-H) architectures across language modeling, in-context retrieval, and mathematical reasoning benchmarks. SSE demonstrates strong retrieval performance and scales favorably with state size. Moreover, after reinforcement learning (RL) training, our 2B SSE-H model achieves state-of-the-art mathematical reasoning performance among small reasoning models, scoring 64.7 on AIME24 and 51.3 on AIME25, significantly outperforming similarly sized open-source Transformers. These results highlight SSE as a promising and efficient architecture for long-context modeling.
Systematic Outliers in Large Language Models
Feb 10, 2025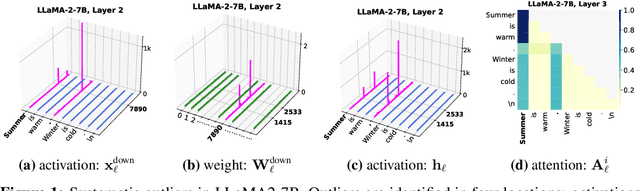

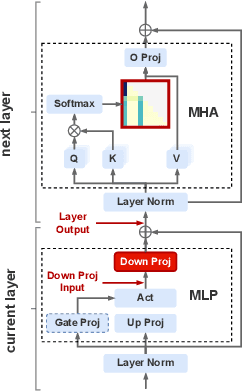

Outliers have been widely observed in Large Language Models (LLMs), significantly impacting model performance and posing challenges for model compression. Understanding the functionality and formation mechanisms of these outliers is critically important. Existing works, however, largely focus on reducing the impact of outliers from an algorithmic perspective, lacking an in-depth investigation into their causes and roles. In this work, we provide a detailed analysis of the formation process, underlying causes, and functions of outliers in LLMs. We define and categorize three types of outliers-activation outliers, weight outliers, and attention outliers-and analyze their distributions across different dimensions, uncovering inherent connections between their occurrences and their ultimate influence on the attention mechanism. Based on these observations, we hypothesize and explore the mechanisms by which these outliers arise and function, demonstrating through theoretical derivations and experiments that they emerge due to the self-attention mechanism's softmax operation. These outliers act as implicit context-aware scaling factors within the attention mechanism. As these outliers stem from systematic influences, we term them systematic outliers. Our study not only enhances the understanding of Transformer-based LLMs but also shows that structurally eliminating outliers can accelerate convergence and improve model compression. The code is avilable at https://github.com/an-yongqi/systematic-outliers.
Fluctuation-based Adaptive Structured Pruning for Large Language Models
Dec 19, 2023Network Pruning is a promising way to address the huge computing resource demands of the deployment and inference of Large Language Models (LLMs). Retraining-free is important for LLMs' pruning methods. However, almost all of the existing retraining-free pruning approaches for LLMs focus on unstructured pruning, which requires specific hardware support for acceleration. In this paper, we propose a novel retraining-free structured pruning framework for LLMs, named FLAP (FLuctuation-based Adaptive Structured Pruning). It is hardware-friendly by effectively reducing storage and enhancing inference speed. For effective structured pruning of LLMs, we highlight three critical elements that demand the utmost attention: formulating structured importance metrics, adaptively searching the global compressed model, and implementing compensation mechanisms to mitigate performance loss. First, FLAP determines whether the output feature map is easily recoverable when a column of weight is removed, based on the fluctuation pruning metric. Then it standardizes the importance scores to adaptively determine the global compressed model structure. At last, FLAP adds additional bias terms to recover the output feature maps using the baseline values. We thoroughly evaluate our approach on a variety of language benchmarks. Without any retraining, our method significantly outperforms the state-of-the-art methods, including LLM-Pruner and the extension of Wanda in structured pruning. The code is released at https://github.com/CASIA-IVA-Lab/FLAP.
Fast Segment Anything
Jun 21, 2023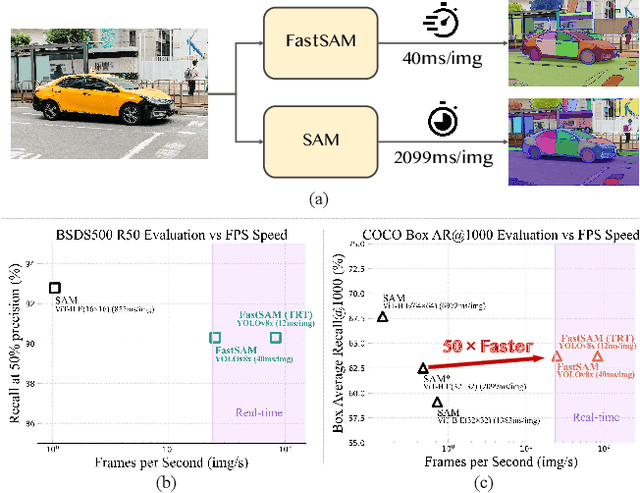

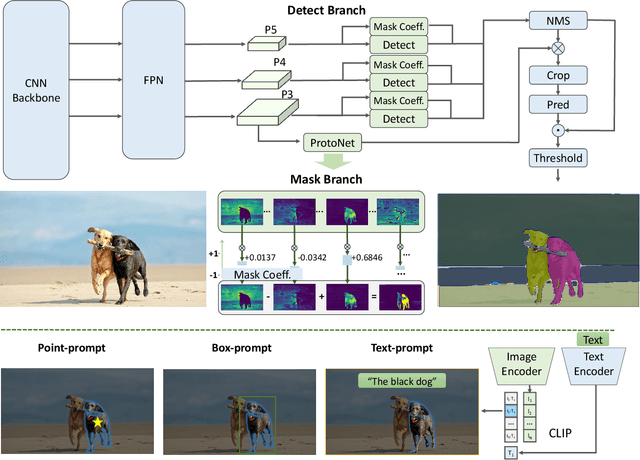
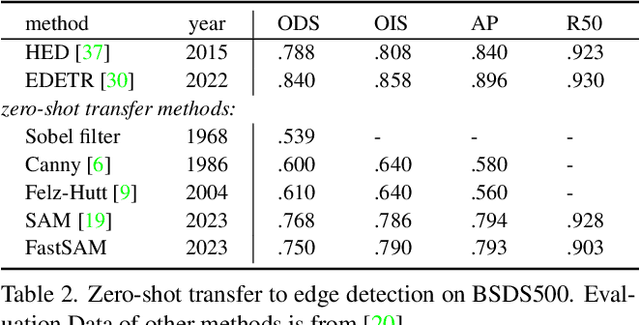
The recently proposed segment anything model (SAM) has made a significant influence in many computer vision tasks. It is becoming a foundation step for many high-level tasks, like image segmentation, image caption, and image editing. However, its huge computation costs prevent it from wider applications in industry scenarios. The computation mainly comes from the Transformer architecture at high-resolution inputs. In this paper, we propose a speed-up alternative method for this fundamental task with comparable performance. By reformulating the task as segments-generation and prompting, we find that a regular CNN detector with an instance segmentation branch can also accomplish this task well. Specifically, we convert this task to the well-studied instance segmentation task and directly train the existing instance segmentation method using only 1/50 of the SA-1B dataset published by SAM authors. With our method, we achieve a comparable performance with the SAM method at 50 times higher run-time speed. We give sufficient experimental results to demonstrate its effectiveness. The codes and demos will be released at https://github.com/CASIA-IVA-Lab/FastSAM.
ZBS: Zero-shot Background Subtraction via Instance-level Background Modeling and Foreground Selection
Mar 26, 2023
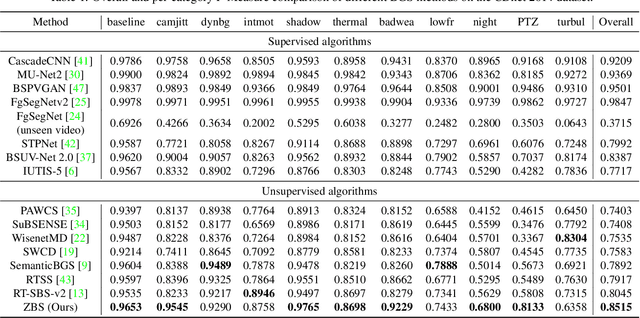
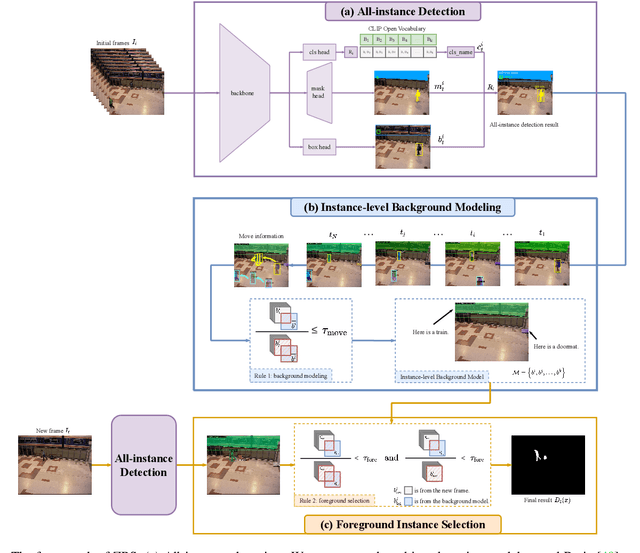
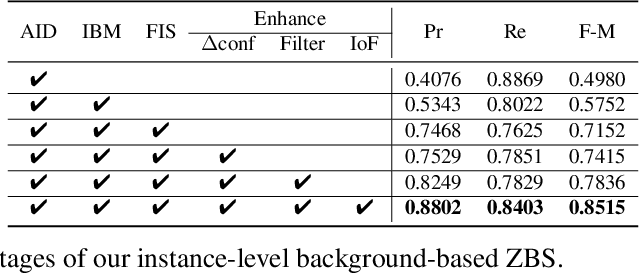
Background subtraction (BGS) aims to extract all moving objects in the video frames to obtain binary foreground segmentation masks. Deep learning has been widely used in this field. Compared with supervised-based BGS methods, unsupervised methods have better generalization. However, previous unsupervised deep learning BGS algorithms perform poorly in sophisticated scenarios such as shadows or night lights, and they cannot detect objects outside the pre-defined categories. In this work, we propose an unsupervised BGS algorithm based on zero-shot object detection called Zero-shot Background Subtraction (ZBS). The proposed method fully utilizes the advantages of zero-shot object detection to build the open-vocabulary instance-level background model. Based on it, the foreground can be effectively extracted by comparing the detection results of new frames with the background model. ZBS performs well for sophisticated scenarios, and it has rich and extensible categories. Furthermore, our method can easily generalize to other tasks, such as abandoned object detection in unseen environments. We experimentally show that ZBS surpasses state-of-the-art unsupervised BGS methods by 4.70% F-Measure on the CDnet 2014 dataset. The code is released at https://github.com/CASIA-IVA-Lab/ZBS.
Pruning-aware Sparse Regularization for Network Pruning
Jan 18, 2022Structural neural network pruning aims to remove the redundant channels in the deep convolutional neural networks (CNNs) by pruning the filters of less importance to the final output accuracy. To reduce the degradation of performance after pruning, many methods utilize the loss with sparse regularization to produce structured sparsity. In this paper, we analyze these sparsity-training-based methods and find that the regularization of unpruned channels is unnecessary. Moreover, it restricts the network's capacity, which leads to under-fitting. To solve this problem, we propose a novel pruning method, named MaskSparsity, with pruning-aware sparse regularization. MaskSparsity imposes the fine-grained sparse regularization on the specific filters selected by a pruning mask, rather than all the filters of the model. Before the fine-grained sparse regularization of MaskSparity, we can use many methods to get the pruning mask, such as running the global sparse regularization. MaskSparsity achieves 63.03%-FLOPs reduction on ResNet-110 by removing 60.34% of the parameters, with no top-1 accuracy loss on CIFAR-10. On ILSVRC-2012, MaskSparsity reduces more than 51.07% FLOPs on ResNet-50, with only a loss of 0.76% in the top-1 accuracy. The code is released at https://github.com/CASIA-IVA-Lab/MaskSparsity. Moreover, we have integrated the code of MaskSparity into a PyTorch pruning toolkit, EasyPruner, at https://gitee.com/casia_iva_engineer/easypruner.