 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Co-Scientist for Ranking: Discovering Novel Search Ranking Models alongside LLM-based AI Agents with Cloud Computing Access
Mar 23, 2026Recent advances in AI agents for software engineering and scientific discovery have demonstrated remarkable capabilities, yet their application to developing novel ranking models in commercial search engines remains unexplored. In this paper, we present an AI Co-Scientist framework that automates the full search ranking research pipeline: from idea generation to code implementation and GPU training job scheduling with expert in the loop. Our approach strategically employs single-LLM agents for routine tasks while leveraging multi-LLM consensus agents (GPT 5.2, Gemini Pro 3, and Claude Opus 4.5) for challenging phases such as results analysis and idea generation. To our knowledge, this is the first study in the ranking community to utilize an AI Co-Scientist framework for algorithmic research. We demonstrate that this framework discovered a novel technique for handling sequence features, with all model enhancements produced automatically, yielding substantial offline performance improvements. Our findings suggest that AI systems can discover ranking architectures comparable to those developed by human experts while significantly reducing routine research workloads.
Train Once, Get a Family: State-Adaptive Balances for Offline-to-Online Reinforcement Learning
Oct 30, 2023Offline-to-online reinforcement learning (RL) is a training paradigm that combines pre-training on a pre-collected dataset with fine-tuning in an online environment. However, the incorporation of online fine-tuning can intensify the well-known distributional shift problem. Existing solutions tackle this problem by imposing a policy constraint on the policy improvement objective in both offline and online learning. They typically advocate a single balance between policy improvement and constraints across diverse data collections. This one-size-fits-all manner may not optimally leverage each collected sample due to the significant variation in data quality across different states. To this end, we introduce Family Offline-to-Online RL (FamO2O), a simple yet effective framework that empowers existing algorithms to determine state-adaptive improvement-constraint balances. FamO2O utilizes a universal model to train a family of policies with different improvement/constraint intensities, and a balance model to select a suitable policy for each state. Theoretically, we prove that state-adaptive balances are necessary for achieving a higher policy performance upper bound. Empirically, extensive experiments show that FamO2O offers a statistically significant improvement over various existing methods, achieving state-of-the-art performance on the D4RL benchmark. Codes are available at https://github.com/LeapLabTHU/FamO2O.
Balancing Logit Variation for Long-tailed Semantic Segmentation
Jun 03, 2023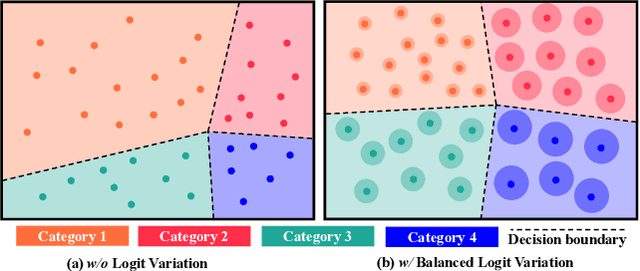

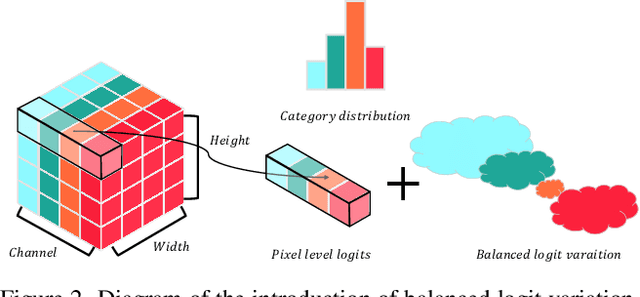
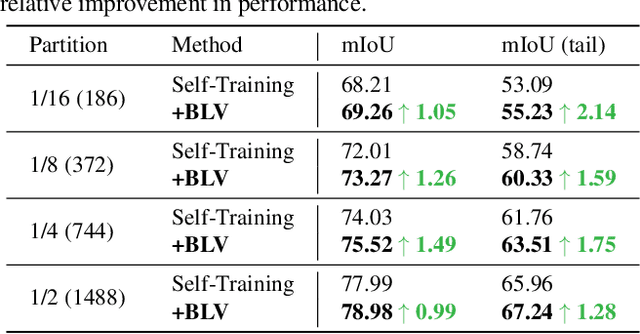
Semantic segmentation usually suffers from a long-tail data distribution. Due to the imbalanced number of samples across categories, the features of those tail classes may get squeezed into a narrow area in the feature space. Towards a balanced feature distribution, we introduce category-wise variation into the network predictions in the training phase such that an instance is no longer projected to a feature point, but a small region instead. Such a perturbation is highly dependent on the category scale, which appears as assigning smaller variation to head classes and larger variation to tail classes. In this way, we manage to close the gap between the feature areas of different categories, resulting in a more balanced representation. It is noteworthy that the introduced variation is discarded at the inference stage to facilitate a confident prediction. Although with an embarrassingly simple implementation, our method manifests itself in strong generalizability to various datasets and task settings. Extensive experiments suggest that our plug-in design lends itself well to a range of state-of-the-art approaches and boosts the performance on top of them.
3D Model-based Zero-Shot Pose Estimation Pipeline
May 29, 2023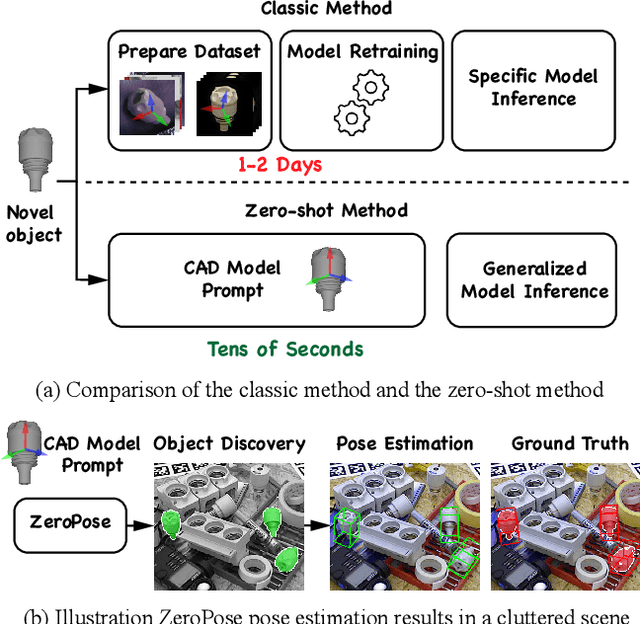
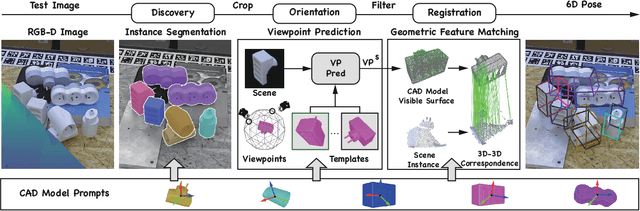
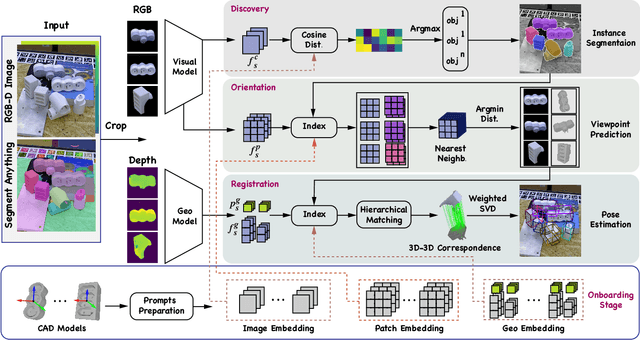
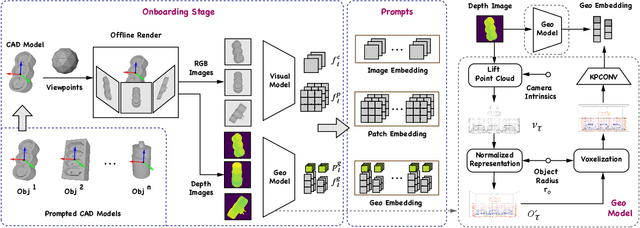
Most existing learning-based pose estimation methods are typically developed for non-zero-shot scenarios, where they can only estimate the poses of objects present in the training dataset. This setting restricts their applicability to unseen objects in the training phase. In this paper, we introduce a fully zero-shot pose estimation pipeline that leverages the 3D models of objects as clues. Specifically, we design a two-step pipeline consisting of 3D model-based zero-shot instance segmentation and a zero-shot pose estimator. For the first step, there is a novel way to perform zero-shot instance segmentation based on the 3D models instead of text descriptions, which can handle complex properties of unseen objects. For the second step, we utilize a hierarchical geometric structure matching mechanism to perform zero-shot pose estimation which is 10 times faster than the current render-based method. Extensive experimental results on the seven core datasets on the BOP challenge show that the proposed method outperforms the zero-shot state-of-the-art method with higher speed and lower computation cost.
Pulling Target to Source: A New Perspective on Domain Adaptive Semantic Segmentation
May 23, 2023



Domain adaptive semantic segmentation aims to transfer knowledge from a labeled source domain to an unlabeled target domain. However, existing methods primarily focus on directly learning qualified target features, making it challenging to guarantee their discrimination in the absence of target labels. This work provides a new perspective. We observe that the features learned with source data manage to keep categorically discriminative during training, thereby enabling us to implicitly learn adequate target representations by simply \textbf{pulling target features close to source features for each category}. To this end, we propose T2S-DA, which we interpret as a form of pulling Target to Source for Domain Adaptation, encouraging the model in learning similar cross-domain features. Also, considering the pixel categories are heavily imbalanced for segmentation datasets, we come up with a dynamic re-weighting strategy to help the model concentrate on those underperforming classes. Extensive experiments confirm that T2S-DA learns a more discriminative and generalizable representation, significantly surpassing the state-of-the-art. We further show that our method is quite qualified for the domain generalization task, verifying its domain-invariant property.
SeqCo-DETR: Sequence Consistency Training for Self-Supervised Object Detection with Transformers
Mar 15, 2023



Self-supervised pre-training and transformer-based networks have significantly improved the performance of object detection. However, most of the current self-supervised object detection methods are built on convolutional-based architectures. We believe that the transformers' sequence characteristics should be considered when designing a transformer-based self-supervised method for the object detection task. To this end, we propose SeqCo-DETR, a novel Sequence Consistency-based self-supervised method for object DEtection with TRansformers. SeqCo-DETR defines a simple but effective pretext by minimizes the discrepancy of the output sequences of transformers with different image views as input and leverages bipartite matching to find the most relevant sequence pairs to improve the sequence-level self-supervised representation learning performance. Furthermore, we provide a mask-based augmentation strategy incorporated with the sequence consistency strategy to extract more representative contextual information about the object for the object detection task. Our method achieves state-of-the-art results on MS COCO (45.8 AP) and PASCAL VOC (64.1 AP), demonstrating the effectiveness of our approach.
Efficient Masked Autoencoders with Self-Consistency
Feb 28, 2023
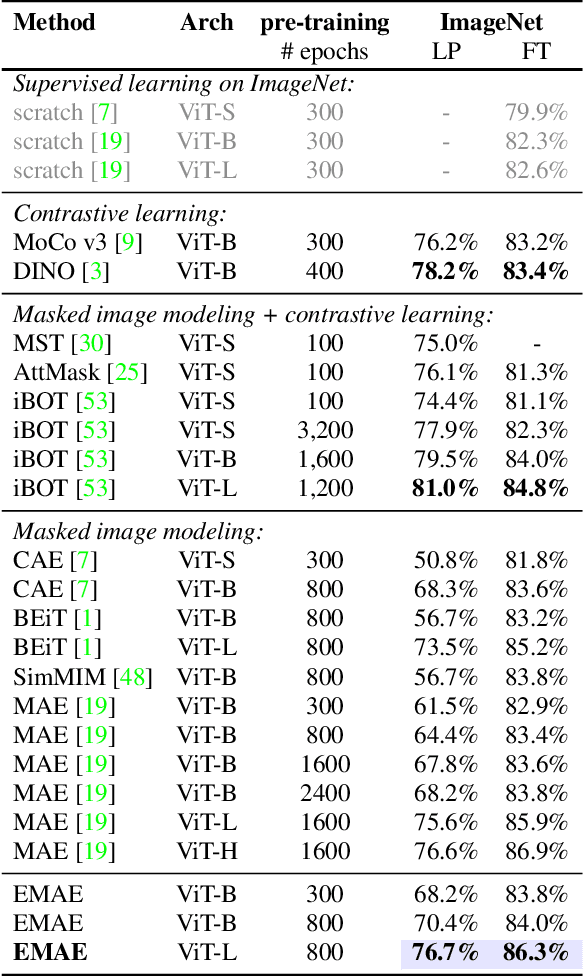
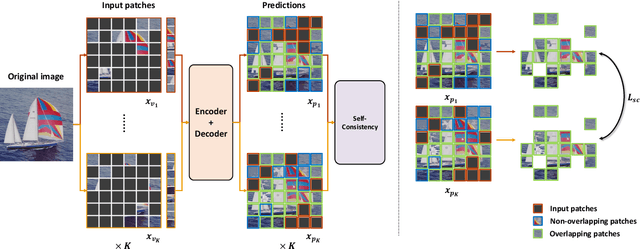
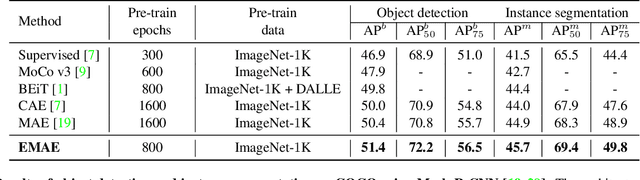
Inspired by masked language modeling (MLM) in natural language processing, masked image modeling (MIM) has been recognized as a strong and popular self-supervised pre-training method in computer vision. However, its high random mask ratio would result in two serious problems: 1) the data are not efficiently exploited, which brings inefficient pre-training (\eg, 1600 epochs for MAE $vs.$ 300 epochs for the supervised), and 2) the high uncertainty and inconsistency of the pre-trained model, \ie, the prediction of the same patch may be inconsistent under different mask rounds. To tackle these problems, we propose efficient masked autoencoders with self-consistency (EMAE), to improve the pre-training efficiency and increase the consistency of MIM. In particular, we progressively divide the image into K non-overlapping parts, each of which is generated by a random mask and has the same mask ratio. Then the MIM task is conducted parallelly on all parts in an iteration and generates predictions. Besides, we design a self-consistency module to further maintain the consistency of predictions of overlapping masked patches among parts. Overall, the proposed method is able to exploit the data more efficiently and obtains reliable representations. Experiments on ImageNet show that EMAE achieves even higher results with only 300 pre-training epochs under ViT-Base than MAE (1600 epochs). EMAE also consistently obtains state-of-the-art transfer performance on various downstream tasks, like object detection, and semantic segmentation.
Beyond Triplet: Leveraging the Most Data for Multimodal Machine Translation
Dec 20, 2022



Multimodal machine translation (MMT) aims to improve translation quality by incorporating information from other modalities, such as vision. Previous MMT systems mainly focus on better access and use of visual information and tend to validate their methods on image-related datasets. These studies face two challenges. First, they can only utilize triple data (bilingual texts with images), which is scarce; second, current benchmarks are relatively restricted and do not correspond to realistic scenarios. Therefore, this paper correspondingly establishes new methods and new datasets for MMT. First, we propose a framework 2/3-Triplet with two new approaches to enhance MMT by utilizing large-scale non-triple data: monolingual image-text data and parallel text-only data. Second, we construct an English-Chinese {e}-commercial {m}ulti{m}odal {t}ranslation dataset (including training and testing), named EMMT, where its test set is carefully selected as some words are ambiguous and shall be translated mistakenly without the help of images. Experiments show that our method is more suitable for real-world scenarios and can significantly improve translation performance by using more non-triple data. In addition, our model also rivals various SOTA models in conventional multimodal translation benchmarks.
Exploring Stochastic Autoregressive Image Modeling for Visual Representation
Dec 03, 2022



Autoregressive language modeling (ALM) have been successfully used in self-supervised pre-training in Natural language processing (NLP). However, this paradigm has not achieved comparable results with other self-supervised approach in computer vision (e.g., contrastive learning, mask image modeling). In this paper, we try to find the reason why autoregressive modeling does not work well on vision tasks. To tackle this problem, we fully analyze the limitation of visual autoregressive methods and proposed a novel stochastic autoregressive image modeling (named SAIM) by the two simple designs. First, we employ stochastic permutation strategy to generate effective and robust image context which is critical for vision tasks. Second, we create a parallel encoder-decoder training process in which the encoder serves a similar role to the standard vision transformer focus on learning the whole contextual information, and meanwhile the decoder predicts the content of the current position, so that the encoder and decoder can reinforce each other. By introducing stochastic prediction and the parallel encoder-decoder, SAIM significantly improve the performance of autoregressive image modeling. Our method achieves the best accuracy (83.9%) on the vanilla ViT-Base model among methods using only ImageNet-1K data. Transfer performance in downstream tasks also show that our model achieves competitive performance.
MIAD: A Maintenance Inspection Dataset for Unsupervised Anomaly Detection
Nov 28, 2022



Visual anomaly detection plays a crucial role in not only manufacturing inspection to find defects of products during manufacturing processes, but also maintenance inspection to keep equipment in optimum working condition particularly outdoors. Due to the scarcity of the defective samples, unsupervised anomaly detection has attracted great attention in recent years. However, existing datasets for unsupervised anomaly detection are biased towards manufacturing inspection, not considering maintenance inspection which is usually conducted under outdoor uncontrolled environment such as varying camera viewpoints, messy background and degradation of object surface after long-term working. We focus on outdoor maintenance inspection and contribute a comprehensive Maintenance Inspection Anomaly Detection (MIAD) dataset which contains more than 100K high-resolution color images in various outdoor industrial scenarios. This dataset is generated by a 3D graphics software and covers both surface and logical anomalies with pixel-precise ground truth. Extensive evaluations of representative algorithms for unsupervised anomaly detection are conducted, and we expect MIAD and corresponding experimental results can inspire research community in outdoor unsupervised anomaly detection tasks. Worthwhile and related future work can be spawned from our new dataset.