 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
May 21, 2026Reinforcement learning from verifiable rewards (RLVR) has shown strong promise for LLM reasoning, but outcome-based RLVR remains inefficient on hard problems because correct final-answer rollouts are rare and sample-level credit assignment cannot use partial progress in failed attempts. We introduce SCRL (Subproblem Curriculum Reinforcement Learning), a curriculum RL framework that derives verifiable subproblems from reference reasoning chains and fixes the final subproblem as the original problem. This turns partial progress on hard problems into verifiable learning signals. Algorithmically, SCRL uses subproblem-level normalization, which normalizes rewards independently at each subproblem position and assigns the resulting advantages to the corresponding answer spans, enabling finer-grained credit assignment without external rubrics or reward models. Our analysis shows that subproblem curricula lift hard problems out of gradient dead zones, with larger relative gains as the original problem becomes harder. Across seven mathematical reasoning benchmarks, SCRL outperforms strong curriculum-learning baselines, improving average accuracy over GRPO by +4.1 points on Qwen3-4B-Base and +1.9 points on Qwen3-14B-Base. On AIME24, AIME25, and IMO-Bench, SCRL further improves pass@1 by +3.7 points and pass@64 by +4.6 points on Qwen3-4B-Base, indicating better exploration on hard reasoning problems.
HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
Mar 19, 2026Vision-language models (VLMs) show strong multimodal capabilities but still struggle with fine-grained vision-language reasoning. We find that long chain-of-thought (CoT) reasoning exposes diverse failure modes, including perception, reasoning, knowledge, and hallucination errors, which can compound across intermediate steps. However, most existing vision-language data used for reinforcement learning with verifiable rewards (RLVR) does not involve complex reasoning chains that rely on visual evidence throughout, leaving these weaknesses largely unexposed. We therefore propose HopChain, a scalable framework for synthesizing multi-hop vision-language reasoning data for RLVR training of VLMs. Each synthesized multi-hop query forms a logically dependent chain of instance-grounded hops, where earlier hops establish the instances, sets, or conditions needed for later hops, while the final answer remains a specific, unambiguous number suitable for verifiable rewards. We train Qwen3.5-35B-A3B and Qwen3.5-397B-A17B under two RLVR settings: the original data alone, and the original data plus HopChain's multi-hop data, and compare them across 24 benchmarks spanning STEM and Puzzle, General VQA, Text Recognition and Document Understanding, and Video Understanding. Although this multi-hop data is not synthesized for any specific benchmark, it improves 20 of 24 benchmarks on both models, indicating broad and generalizable gains. Consistently, replacing full chained queries with half-multi-hop or single-hop variants reduces the average score across five representative benchmarks from 70.4 to 66.7 and 64.3, respectively. Notably, multi-hop gains peak in long-CoT vision-language reasoning, exceeding 50 points in the ultra-long-CoT regime. These experiments establish HopChain as an effective, scalable framework for synthesizing multi-hop data that improves generalizable vision-language reasoning.
Outcome Accuracy is Not Enough: Aligning the Reasoning Process of Reward Models
Feb 04, 2026Generative Reward Models (GenRMs) and LLM-as-a-Judge exhibit deceptive alignment by producing correct judgments for incorrect reasons, as they are trained and evaluated to prioritize Outcome Accuracy, which undermines their ability to generalize during RLHF. We introduce Rationale Consistency, a fine-grained metric that quantifies the alignment between the model's reasoning process and human judgment. Our evaluation of frontier models reveals that rationale consistency effectively discriminates among state-of-the-art models and detects deceptive alignment, while outcome accuracy falls short in both respects. To mitigate this gap, we introduce a hybrid signal that combines rationale consistency with outcome accuracy for GenRM training. Our training method achieves state-of-the-art performance on RM-Bench (87.1%) and JudgeBench (82%), surpassing outcome-only baselines by an average of 5%. Using RM during RLHF, our method effectively improves performance as demonstrated on Arena Hard v2, notably yielding a 7% improvement in creative writing tasks. Further analysis confirms that our method escapes the deceptive alignment trap, effectively reversing the decline in rationale consistency observed in outcome-only training.
The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models
Jan 21, 2026Diffusion Large Language Models (dLLMs) break the rigid left-to-right constraint of traditional LLMs, enabling token generation in arbitrary orders. Intuitively, this flexibility implies a solution space that strictly supersets the fixed autoregressive trajectory, theoretically unlocking superior reasoning potential for general tasks like mathematics and coding. Consequently, numerous works have leveraged reinforcement learning (RL) to elicit the reasoning capability of dLLMs. In this paper, we reveal a counter-intuitive reality: arbitrary order generation, in its current form, narrows rather than expands the reasoning boundary of dLLMs. We find that dLLMs tend to exploit this order flexibility to bypass high-uncertainty tokens that are crucial for exploration, leading to a premature collapse of the solution space. This observation challenges the premise of existing RL approaches for dLLMs, where considerable complexities, such as handling combinatorial trajectories and intractable likelihoods, are often devoted to preserving this flexibility. We demonstrate that effective reasoning is better elicited by intentionally forgoing arbitrary order and applying standard Group Relative Policy Optimization (GRPO) instead. Our approach, JustGRPO, is minimalist yet surprisingly effective (e.g., 89.1% accuracy on GSM8K) while fully retaining the parallel decoding ability of dLLMs. Project page: https://nzl-thu.github.io/the-flexibility-trap
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025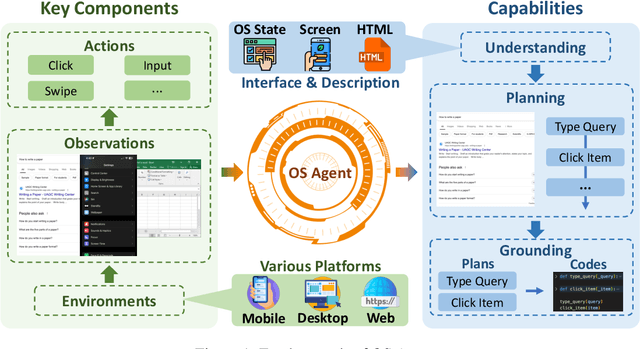
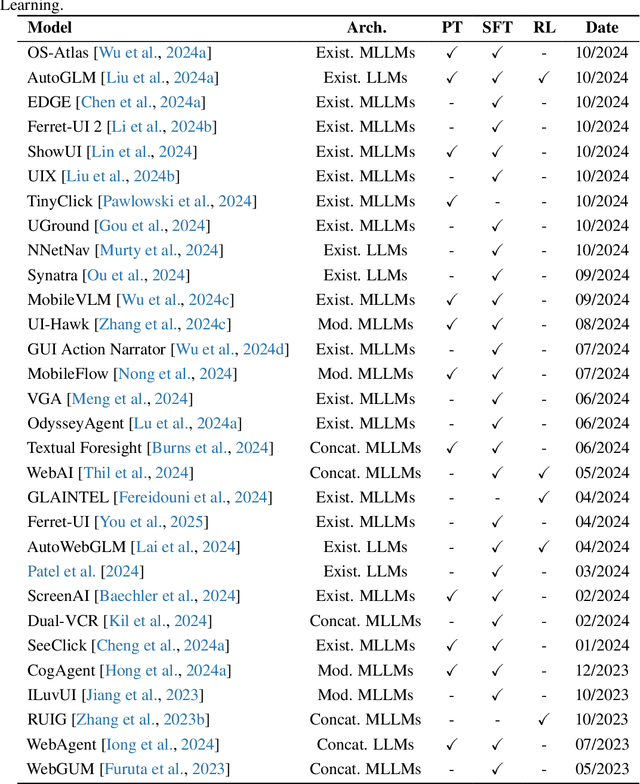
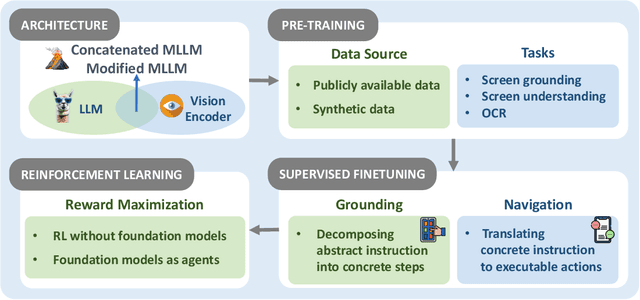
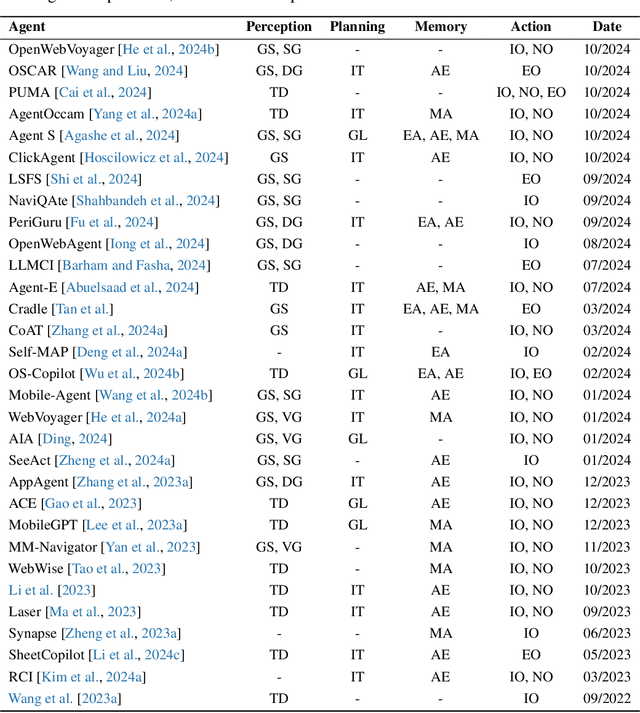
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
May 07, 2025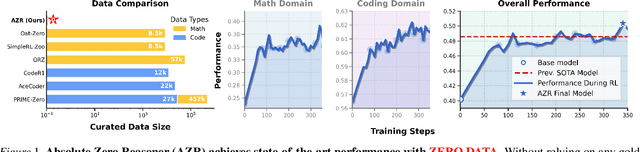
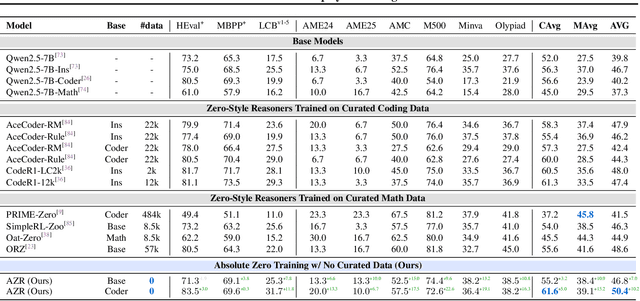

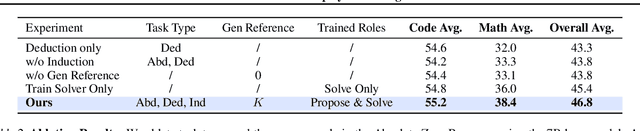
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR works that operate under the zero setting avoid supervision in labeling the reasoning process, but still depend on manually curated collections of questions and answers for training. The scarcity of high-quality, human-produced examples raises concerns about the long-term scalability of relying on human supervision, a challenge already evident in the domain of language model pretraining. Furthermore, in a hypothetical future where AI surpasses human intelligence, tasks provided by humans may offer limited learning potential for a superintelligent system. To address these concerns, we propose a new RLVR paradigm called Absolute Zero, in which a single model learns to propose tasks that maximize its own learning progress and improves reasoning by solving them, without relying on any external data. Under this paradigm, we introduce the Absolute Zero Reasoner (AZR), a system that self-evolves its training curriculum and reasoning ability by using a code executor to both validate proposed code reasoning tasks and verify answers, serving as an unified source of verifiable reward to guide open-ended yet grounded learning. Despite being trained entirely without external data, AZR achieves overall SOTA performance on coding and mathematical reasoning tasks, outperforming existing zero-setting models that rely on tens of thousands of in-domain human-curated examples. Furthermore, we demonstrate that AZR can be effectively applied across different model scales and is compatible with various model classes.
COIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
DeeR-VLA: Dynamic Inference of Multimodal Large Language Models for Efficient Robot Execution
Nov 04, 2024



MLLMs have demonstrated remarkable comprehension and reasoning capabilities with complex language and visual data. These advances have spurred the vision of establishing a generalist robotic MLLM proficient in understanding complex human instructions and accomplishing various embodied tasks. However, developing MLLMs for real-world robots is challenging due to the typically limited computation and memory capacities available on robotic platforms. In contrast, the inference of MLLMs involves storing billions of parameters and performing tremendous computation, imposing significant hardware demands. In our paper, we propose a Dynamic Early-Exit Framework for Robotic Vision-Language-Action Model (DeeR-VLA, or simply DeeR) that automatically adjusts the size of the activated MLLM based on each situation at hand. The approach leverages a multi-exit architecture in MLLMs, which allows the model to terminate processing once a proper size of the model has been activated for a specific situation, thus avoiding further redundant computation. Additionally, we develop novel algorithms that establish early-termination criteria for DeeR, conditioned on predefined demands such as average computational cost (i.e., power consumption), as well as peak computational consumption (i.e., latency) and GPU memory usage. These enhancements ensure that DeeR operates efficiently under varying resource constraints while maintaining competitive performance. On the CALVIN robot manipulation benchmark, DeeR demonstrates significant reductions in computational costs of LLM by 5.2-6.5x and GPU memory of LLM by 2-6x without compromising performance. Code and checkpoints are available at https://github.com/yueyang130/DeeR-VLA.
LLM-based Optimization of Compound AI Systems: A Survey
Oct 21, 2024

In a compound AI system, components such as an LLM call, a retriever, a code interpreter, or tools are interconnected. The system's behavior is primarily driven by parameters such as instructions or tool definitions. Recent advancements enable end-to-end optimization of these parameters using an LLM. Notably, leveraging an LLM as an optimizer is particularly efficient because it avoids gradient computation and can generate complex code and instructions. This paper presents a survey of the principles and emerging trends in LLM-based optimization of compound AI systems. It covers archetypes of compound AI systems, approaches to LLM-based end-to-end optimization, and insights into future directions and broader impacts. Importantly, this survey uses concepts from program analysis to provide a unified view of how an LLM optimizer is prompted to optimize a compound AI system. The exhaustive list of paper is provided at https://github.com/linyuhongg/LLM-based-Optimization-of-Compound-AI-Systems.
Model Surgery: Modulating LLM's Behavior Via Simple Parameter Editing
Jul 11, 2024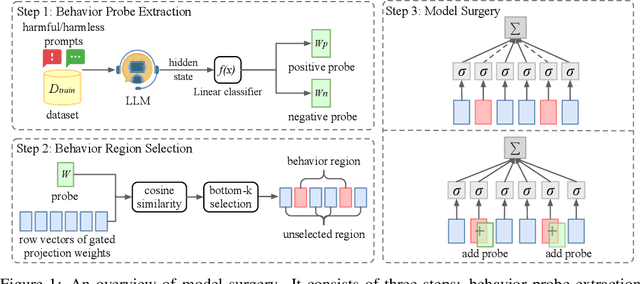

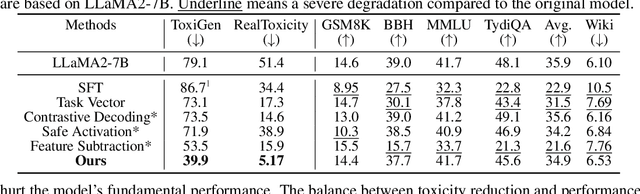
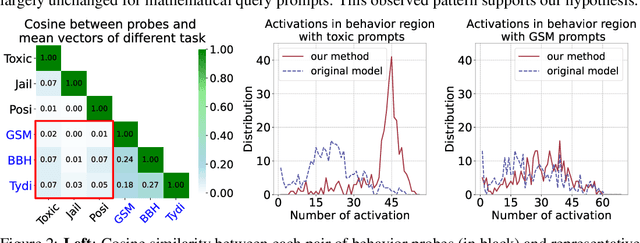
Large Language Models (LLMs) have demonstrated great potential as generalist assistants, showcasing powerful task understanding and problem-solving capabilities. To deploy LLMs as AI assistants, it is crucial that these models exhibit desirable behavioral traits, such as non-toxicity and resilience against jailbreak attempts. Current methods for detoxification or preventing jailbreaking usually involve Supervised Fine-Tuning (SFT) or Reinforcement Learning from Human Feedback (RLHF), which requires finetuning billions of parameters through gradient descent with substantial computation cost. Furthermore, models modified through SFT and RLHF may deviate from the pretrained models, potentially leading to a degradation in foundational LLM capabilities. In this paper, we observe that surprisingly, directly editing a small subset of parameters can effectively modulate specific behaviors of LLMs, such as detoxification and resistance to jailbreaking. Specifically, for a behavior that we aim to avoid, we employ a linear classifier, which we term the behavior probe, to classify binary behavior labels within the hidden state space of the LLM. Using this probe, we introduce an algorithm to identify a critical subset of LLM parameters that significantly influence this targeted behavior. Then we directly edit these selected parameters by shifting them towards the behavior probe. Such a direct parameter editing method necessitates only inference-level computational resources. Experiments demonstrate that in the representative detoxification task, our approach achieves reductions of up to 90.0\% in toxicity on the RealToxicityPrompts dataset and 49.2\% on ToxiGen, while maintaining the LLM's general capabilities in areas such as common sense, question answering, and mathematics. Our code is available at https://github.com/lucywang720/model-surgery.