 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbsolute Zero: Reinforced Self-play Reasoning with Zero Data
May 07, 2025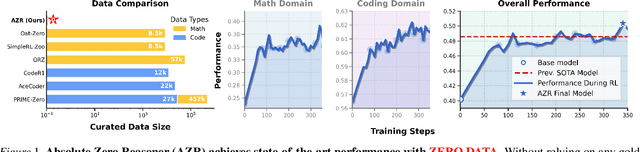
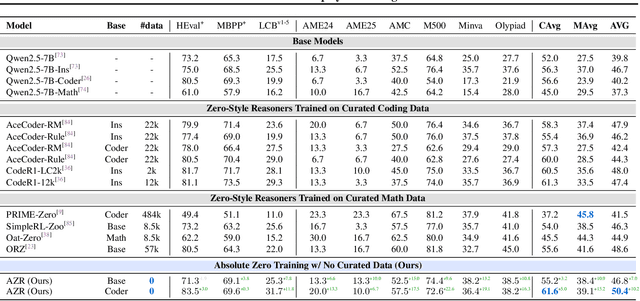

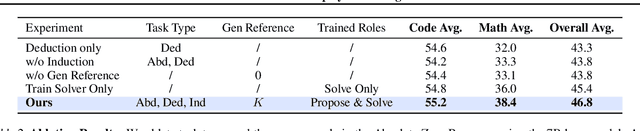
Reinforcement learning with verifiable rewards (RLVR) has shown promise in enhancing the reasoning capabilities of large language models by learning directly from outcome-based rewards. Recent RLVR works that operate under the zero setting avoid supervision in labeling the reasoning process, but still depend on manually curated collections of questions and answers for training. The scarcity of high-quality, human-produced examples raises concerns about the long-term scalability of relying on human supervision, a challenge already evident in the domain of language model pretraining. Furthermore, in a hypothetical future where AI surpasses human intelligence, tasks provided by humans may offer limited learning potential for a superintelligent system. To address these concerns, we propose a new RLVR paradigm called Absolute Zero, in which a single model learns to propose tasks that maximize its own learning progress and improves reasoning by solving them, without relying on any external data. Under this paradigm, we introduce the Absolute Zero Reasoner (AZR), a system that self-evolves its training curriculum and reasoning ability by using a code executor to both validate proposed code reasoning tasks and verify answers, serving as an unified source of verifiable reward to guide open-ended yet grounded learning. Despite being trained entirely without external data, AZR achieves overall SOTA performance on coding and mathematical reasoning tasks, outperforming existing zero-setting models that rely on tens of thousands of in-domain human-curated examples. Furthermore, we demonstrate that AZR can be effectively applied across different model scales and is compatible with various model classes.
DiveR-CT: Diversity-enhanced Red Teaming with Relaxing Constraints
May 29, 2024



Recent advances in large language models (LLMs) have made them indispensable, raising significant concerns over managing their safety. Automated red teaming offers a promising alternative to the labor-intensive and error-prone manual probing for vulnerabilities, providing more consistent and scalable safety evaluations. However, existing approaches often compromise diversity by focusing on maximizing attack success rate. Additionally, methods that decrease the cosine similarity from historical embeddings with semantic diversity rewards lead to novelty stagnation as history grows. To address these issues, we introduce DiveR-CT, which relaxes conventional constraints on the objective and semantic reward, granting greater freedom for the policy to enhance diversity. Our experiments demonstrate DiveR-CT's marked superiority over baselines by 1) generating data that perform better in various diversity metrics across different attack success rate levels, 2) better-enhancing resiliency in blue team models through safety tuning based on collected data, 3) allowing dynamic control of objective weights for reliable and controllable attack success rates, and 4) reducing susceptibility to reward overoptimization. Project details and code can be found at https://andrewzh112.github.io/#diverct.
ExpeL: LLM Agents Are Experiential Learners
Aug 20, 2023The recent surge in research interest in applying large language models (LLMs) to decision-making tasks has flourished by leveraging the extensive world knowledge embedded in LLMs. While there is a growing demand to tailor LLMs for custom decision-making tasks, finetuning them for specific tasks is resource-intensive and may diminish the model's generalization capabilities. Moreover, state-of-the-art language models like GPT-4 and Claude are primarily accessible through API calls, with their parametric weights remaining proprietary and unavailable to the public. This scenario emphasizes the growing need for new methodologies that allow learning from agent experiences without requiring parametric updates. To address these problems, we introduce the Experiential Learning (ExpeL) agent. Our agent autonomously gathers experiences and extracts knowledge using natural language from a collection of training tasks. At inference, the agent recalls its extracted insights and past experiences to make informed decisions. Our empirical results highlight the robust learning efficacy of the ExpeL agent, indicating a consistent enhancement in its performance as it accumulates experiences. We further explore the emerging capabilities and transfer learning potential of the ExpeL agent through qualitative observations and additional experiments.