 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStdGEN++: A Comprehensive System for Semantic-Decomposed 3D Character Generation
Jan 12, 2026We present StdGEN++, a novel and comprehensive system for generating high-fidelity, semantically decomposed 3D characters from diverse inputs. Existing 3D generative methods often produce monolithic meshes that lack the structural flexibility required by industrial pipelines in gaming and animation. Addressing this gap, StdGEN++ is built upon a Dual-branch Semantic-aware Large Reconstruction Model (Dual-Branch S-LRM), which jointly reconstructs geometry, color, and per-component semantics in a feed-forward manner. To achieve production-level fidelity, we introduce a novel semantic surface extraction formalism compatible with hybrid implicit fields. This mechanism is accelerated by a coarse-to-fine proposal scheme, which significantly reduces memory footprint and enables high-resolution mesh generation. Furthermore, we propose a video-diffusion-based texture decomposition module that disentangles appearance into editable layers (e.g., separated iris and skin), resolving semantic confusion in facial regions. Experiments demonstrate that StdGEN++ achieves state-of-the-art performance, significantly outperforming existing methods in geometric accuracy and semantic disentanglement. Crucially, the resulting structural independence unlocks advanced downstream capabilities, including non-destructive editing, physics-compliant animation, and gaze tracking, making it a robust solution for automated character asset production.
StreamAvatar: Streaming Diffusion Models for Real-Time Interactive Human Avatars
Dec 26, 2025Real-time, streaming interactive avatars represent a critical yet challenging goal in digital human research. Although diffusion-based human avatar generation methods achieve remarkable success, their non-causal architecture and high computational costs make them unsuitable for streaming. Moreover, existing interactive approaches are typically limited to head-and-shoulder region, limiting their ability to produce gestures and body motions. To address these challenges, we propose a two-stage autoregressive adaptation and acceleration framework that applies autoregressive distillation and adversarial refinement to adapt a high-fidelity human video diffusion model for real-time, interactive streaming. To ensure long-term stability and consistency, we introduce three key components: a Reference Sink, a Reference-Anchored Positional Re-encoding (RAPR) strategy, and a Consistency-Aware Discriminator. Building on this framework, we develop a one-shot, interactive, human avatar model capable of generating both natural talking and listening behaviors with coherent gestures. Extensive experiments demonstrate that our method achieves state-of-the-art performance, surpassing existing approaches in generation quality, real-time efficiency, and interaction naturalness. Project page: https://streamavatar.github.io .
HGS: Hybrid Gaussian Splatting with Static-Dynamic Decomposition for Compact Dynamic View Synthesis
Dec 16, 2025Dynamic novel view synthesis (NVS) is essential for creating immersive experiences. Existing approaches have advanced dynamic NVS by introducing 3D Gaussian Splatting (3DGS) with implicit deformation fields or indiscriminately assigned time-varying parameters, surpassing NeRF-based methods. However, due to excessive model complexity and parameter redundancy, they incur large model sizes and slow rendering speeds, making them inefficient for real-time applications, particularly on resource-constrained devices. To obtain a more efficient model with fewer redundant parameters, in this paper, we propose Hybrid Gaussian Splatting (HGS), a compact and efficient framework explicitly designed to disentangle static and dynamic regions of a scene within a unified representation. The core innovation of HGS lies in our Static-Dynamic Decomposition (SDD) strategy, which leverages Radial Basis Function (RBF) modeling for Gaussian primitives. Specifically, for dynamic regions, we employ time-dependent RBFs to effectively capture temporal variations and handle abrupt scene changes, while for static regions, we reduce redundancy by sharing temporally invariant parameters. Additionally, we introduce a two-stage training strategy tailored for explicit models to enhance temporal coherence at static-dynamic boundaries. Experimental results demonstrate that our method reduces model size by up to 98% and achieves real-time rendering at up to 125 FPS at 4K resolution on a single RTX 3090 GPU. It further sustains 160 FPS at 1352 * 1014 on an RTX 3050 and has been integrated into the VR system. Moreover, HGS achieves comparable rendering quality to state-of-the-art methods while providing significantly improved visual fidelity for high-frequency details and abrupt scene changes.
EEGDM: Learning EEG Representation with Latent Diffusion Model
Aug 28, 2025While electroencephalography (EEG) signal analysis using deep learning has shown great promise, existing approaches still face significant challenges in learning generalizable representations that perform well across diverse tasks, particularly when training data is limited. Current EEG representation learning methods including EEGPT and LaBraM typically rely on simple masked reconstruction objective, which may not fully capture the rich semantic information and complex patterns inherent in EEG signals. In this paper, we propose EEGDM, a novel self-supervised EEG representation learning method based on the latent diffusion model, which leverages EEG signal generation as a self-supervised objective, turning the diffusion model into a strong representation learner capable of capturing EEG semantics. EEGDM incorporates an EEG encoder that distills EEG signals and their channel augmentations into a compact representation, acting as conditional information to guide the diffusion model for generating EEG signals. This design endows EEGDM with a compact latent space, which not only offers ample control over the generative process but also can be leveraged for downstream tasks. Experimental results show that EEGDM (1) can reconstruct high-quality EEG signals, (2) effectively learns robust representations, and (3) achieves competitive performance with modest pre-training data size across diverse downstream tasks, underscoring its generalizability and practical utility.
PrimitiveAnything: Human-Crafted 3D Primitive Assembly Generation with Auto-Regressive Transformer
May 07, 2025
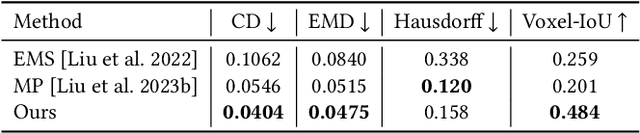
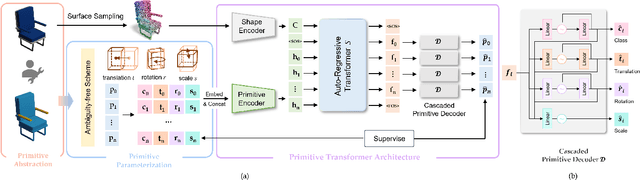
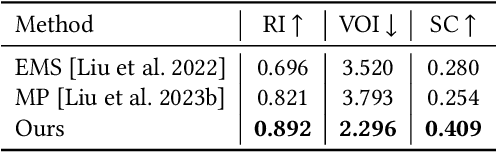
Shape primitive abstraction, which decomposes complex 3D shapes into simple geometric elements, plays a crucial role in human visual cognition and has broad applications in computer vision and graphics. While recent advances in 3D content generation have shown remarkable progress, existing primitive abstraction methods either rely on geometric optimization with limited semantic understanding or learn from small-scale, category-specific datasets, struggling to generalize across diverse shape categories. We present PrimitiveAnything, a novel framework that reformulates shape primitive abstraction as a primitive assembly generation task. PrimitiveAnything includes a shape-conditioned primitive transformer for auto-regressive generation and an ambiguity-free parameterization scheme to represent multiple types of primitives in a unified manner. The proposed framework directly learns the process of primitive assembly from large-scale human-crafted abstractions, enabling it to capture how humans decompose complex shapes into primitive elements. Through extensive experiments, we demonstrate that PrimitiveAnything can generate high-quality primitive assemblies that better align with human perception while maintaining geometric fidelity across diverse shape categories. It benefits various 3D applications and shows potential for enabling primitive-based user-generated content (UGC) in games. Project page: https://primitiveanything.github.io
Tailor: An Integrated Text-Driven CG-Ready Human and Garment Generation System
Mar 15, 2025Creating detailed 3D human avatars with garments typically requires specialized expertise and labor-intensive processes. Although recent advances in generative AI have enabled text-to-3D human/clothing generation, current methods fall short in offering accessible, integrated pipelines for producing ready-to-use clothed avatars. To solve this, we introduce Tailor, an integrated text-to-avatar system that generates high-fidelity, customizable 3D humans with simulation-ready garments. Our system includes a three-stage pipeline. We first employ a large language model to interpret textual descriptions into parameterized body shapes and semantically matched garment templates. Next, we develop topology-preserving deformation with novel geometric losses to adapt garments precisely to body geometries. Furthermore, an enhanced texture diffusion module with a symmetric local attention mechanism ensures both view consistency and photorealistic details. Quantitative and qualitative evaluations demonstrate that Tailor outperforms existing SoTA methods in terms of fidelity, usability, and diversity. Code will be available for academic use.
qNBO: quasi-Newton Meets Bilevel Optimization
Feb 03, 2025Bilevel optimization, addressing challenges in hierarchical learning tasks, has gained significant interest in machine learning. The practical implementation of the gradient descent method to bilevel optimization encounters computational hurdles, notably the computation of the exact lower-level solution and the inverse Hessian of the lower-level objective. Although these two aspects are inherently connected, existing methods typically handle them separately by solving the lower-level problem and a linear system for the inverse Hessian-vector product. In this paper, we introduce a general framework to address these computational challenges in a coordinated manner. Specifically, we leverage quasi-Newton algorithms to accelerate the resolution of the lower-level problem while efficiently approximating the inverse Hessian-vector product. Furthermore, by exploiting the superlinear convergence properties of BFGS, we establish the non-asymptotic convergence analysis of the BFGS adaptation within our framework. Numerical experiments demonstrate the comparable or superior performance of the proposed algorithms in real-world learning tasks, including hyperparameter optimization, data hyper-cleaning, and few-shot meta-learning.
Towards Sharper Information-theoretic Generalization Bounds for Meta-Learning
Jan 26, 2025
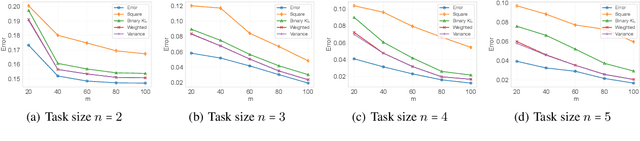

In recent years, information-theoretic generalization bounds have emerged as a promising approach for analyzing the generalization capabilities of meta-learning algorithms. However, existing results are confined to two-step bounds, failing to provide a sharper characterization of the meta-generalization gap that simultaneously accounts for environment-level and task-level dependencies. This paper addresses this fundamental limitation by establishing novel single-step information-theoretic bounds for meta-learning. Our bounds exhibit substantial advantages over prior MI- and CMI-based bounds, especially in terms of tightness, scaling behavior associated with sampled tasks and samples per task, and computational tractability. Furthermore, we provide novel theoretical insights into the generalization behavior of two classes of noise and iterative meta-learning algorithms via gradient covariance analysis, where the meta-learner uses either the entire meta-training data (e.g., Reptile), or separate training and test data within the task (e.g., model agnostic meta-learning (MAML)). Numerical results validate the effectiveness of the derived bounds in capturing the generalization dynamics of meta-learning.
Towards Better Robustness: Progressively Joint Pose-3DGS Learning for Arbitrarily Long Videos
Jan 25, 2025



3D Gaussian Splatting (3DGS) has emerged as a powerful representation due to its efficiency and high-fidelity rendering. However, 3DGS training requires a known camera pose for each input view, typically obtained by Structure-from-Motion (SfM) pipelines. Pioneering works have attempted to relax this restriction but still face difficulties when handling long sequences with complex camera trajectories. In this work, we propose Rob-GS, a robust framework to progressively estimate camera poses and optimize 3DGS for arbitrarily long video sequences. Leveraging the inherent continuity of videos, we design an adjacent pose tracking method to ensure stable pose estimation between consecutive frames. To handle arbitrarily long inputs, we adopt a "divide and conquer" scheme that adaptively splits the video sequence into several segments and optimizes them separately. Extensive experiments on the Tanks and Temples dataset and our collected real-world dataset show that our Rob-GS outperforms the state-of-the-arts.
AlphaTablets: A Generic Plane Representation for 3D Planar Reconstruction from Monocular Videos
Nov 29, 2024



We introduce AlphaTablets, a novel and generic representation of 3D planes that features continuous 3D surface and precise boundary delineation. By representing 3D planes as rectangles with alpha channels, AlphaTablets combine the advantages of current 2D and 3D plane representations, enabling accurate, consistent and flexible modeling of 3D planes. We derive differentiable rasterization on top of AlphaTablets to efficiently render 3D planes into images, and propose a novel bottom-up pipeline for 3D planar reconstruction from monocular videos. Starting with 2D superpixels and geometric cues from pre-trained models, we initialize 3D planes as AlphaTablets and optimize them via differentiable rendering. An effective merging scheme is introduced to facilitate the growth and refinement of AlphaTablets. Through iterative optimization and merging, we reconstruct complete and accurate 3D planes with solid surfaces and clear boundaries. Extensive experiments on the ScanNet dataset demonstrate state-of-the-art performance in 3D planar reconstruction, underscoring the great potential of AlphaTablets as a generic 3D plane representation for various applications. Project page is available at: https://hyzcluster.github.io/alphatablets