 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Drifting Transformers with Representation Autoencoders
Jun 14, 2026Representation Autoencoders (RAEs) have improved diffusion and flow models by semantically richer latent space owing to the strongly label-wise clustered DINO features in the pretrained encoders. Yet in the distillation stage, the severe anisotropy and large curvatures caused by the rich semantic representations would hinder the convergence and performance, making the trajectory-based distillation unstable. In this work, we argue that the RAE latent space is compatible with distillation via the newly proposed Drifting Models. We first quantitatively study the curvatures and isotropy statistics across different autoencoders, and theoretically reveal that Drifting Model itself is highly likely to fail on extremely scattered spaces like reconstruction-based VAEs. These motivate us to apply the drifting paradigm directly to representation autoencoders. Our proposed method, Drift-RAE, distills pretrained flow models in RAE latent spaces using Drifting, together with insightful modifications that improve training stability by thereotically aligning drifting fields with other frameworks. Regarding the experimental evidences, we achieve 1.77 FID on ImageNet 256 dataset using only 10k distillation steps, surpassing state-of-the-art RAE distillation methods and appearing comparative with the original Drifting Model without requiring an auxiliary MAE feature extractor. The code will be made publicly available.
SHIFT: Motion Alignment in Video Diffusion Models with Adversarial Hybrid Fine-Tuning
Mar 18, 2026Image-conditioned Video diffusion models achieve impressive visual realism but often suffer from weakened motion fidelity, e.g., reduced motion dynamics or degraded long-term temporal coherence, especially after fine-tuning. We study the problem of motion alignment in video diffusion models post-training. To address this, we introduce pixel-motion rewards based on pixel flux dynamics, capturing both instantaneous and long-term motion consistency. We further propose Smooth Hybrid Fine-tuning (SHIFT), a scalable reward-driven fine-tuning framework for video diffusion models. SHIFT fuses the normal supervised fine-tuning and advantage weighted fine-tuning into a unified framework. Benefiting from novel adversarial advantages, SHIFT improves convergence speed and mitigates reward hacking. Experiments show that our approach efficiently resolves dynamic-degree collapse in modern video diffusion models supervised fine-tuning.
UCD: Unconditional Discriminator Promotes Nash Equilibrium in GANs
Oct 01, 2025Adversarial training turns out to be the key to one-step generation, especially for Generative Adversarial Network (GAN) and diffusion model distillation. Yet in practice, GAN training hardly converges properly and struggles in mode collapse. In this work, we quantitatively analyze the extent of Nash equilibrium in GAN training, and conclude that redundant shortcuts by inputting condition in $D$ disables meaningful knowledge extraction. We thereby propose to employ an unconditional discriminator (UCD), in which $D$ is enforced to extract more comprehensive and robust features with no condition injection. In this way, $D$ is able to leverage better knowledge to supervise $G$, which promotes Nash equilibrium in GAN literature. Theoretical guarantee on compatibility with vanilla GAN theory indicates that UCD can be implemented in a plug-in manner. Extensive experiments confirm the significant performance improvements with high efficiency. For instance, we achieved \textbf{1.47 FID} on the ImageNet-64 dataset, surpassing StyleGAN-XL and several state-of-the-art one-step diffusion models. The code will be made publicly available.
Rectified Diffusion Guidance for Conditional Generation
Oct 24, 2024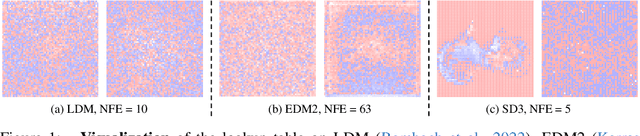
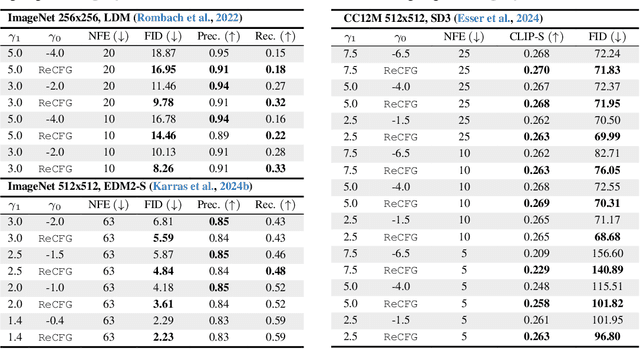
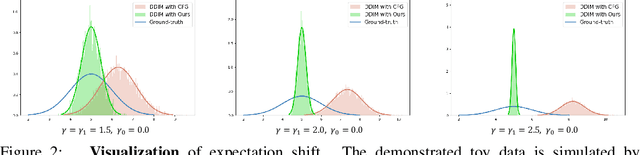

Classifier-Free Guidance (CFG), which combines the conditional and unconditional score functions with two coefficients summing to one, serves as a practical technique for diffusion model sampling. Theoretically, however, denoising with CFG cannot be expressed as a reciprocal diffusion process, which may consequently leave some hidden risks during use. In this work, we revisit the theory behind CFG and rigorously confirm that the improper configuration of the combination coefficients (i.e., the widely used summing-to-one version) brings about expectation shift of the generative distribution. To rectify this issue, we propose ReCFG with a relaxation on the guidance coefficients such that denoising with ReCFG strictly aligns with the diffusion theory. We further show that our approach enjoys a closed-form solution given the guidance strength. That way, the rectified coefficients can be readily pre-computed via traversing the observed data, leaving the sampling speed barely affected. Empirical evidence on real-world data demonstrate the compatibility of our post-hoc design with existing state-of-the-art diffusion models, including both class-conditioned ones (e.g., EDM2 on ImageNet) and text-conditioned ones (e.g., SD3 on CC12M), without any retraining. We will open-source the code to facilitate further research.
Automatic Tooth Arrangement with Joint Features of Point and Mesh Representations via Diffusion Probabilistic Models
Dec 23, 2023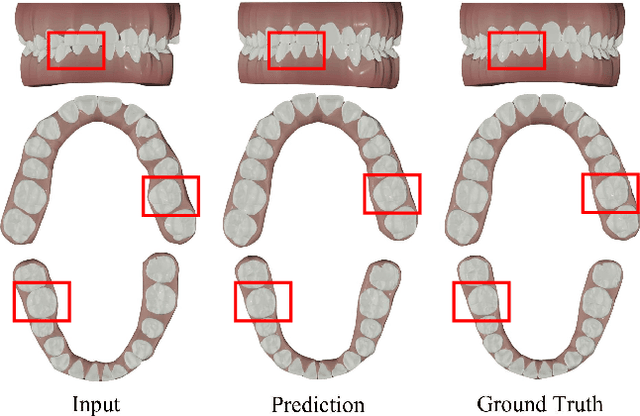
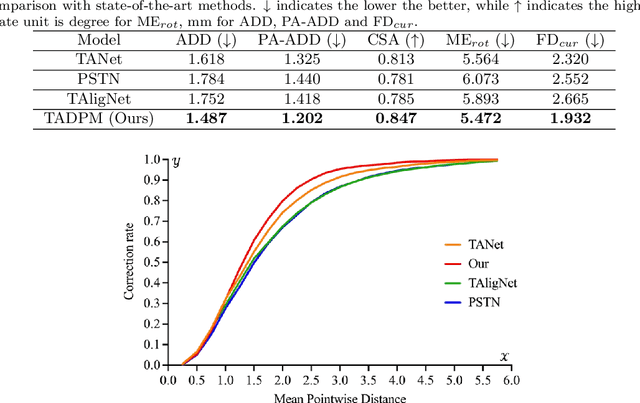

Tooth arrangement is a crucial step in orthodontics treatment, in which aligning teeth could improve overall well-being, enhance facial aesthetics, and boost self-confidence. To improve the efficiency of tooth arrangement and minimize errors associated with unreasonable designs by inexperienced practitioners, some deep learning-based tooth arrangement methods have been proposed. Currently, most existing approaches employ MLPs to model the nonlinear relationship between tooth features and transformation matrices to achieve tooth arrangement automatically. However, the limited datasets (which to our knowledge, have not been made public) collected from clinical practice constrain the applicability of existing methods, making them inadequate for addressing diverse malocclusion issues. To address this challenge, we propose a general tooth arrangement neural network based on the diffusion probabilistic model. Conditioned on the features extracted from the dental model, the diffusion probabilistic model can learn the distribution of teeth transformation matrices from malocclusion to normal occlusion by gradually denoising from a random variable, thus more adeptly managing real orthodontic data. To take full advantage of effective features, we exploit both mesh and point cloud representations by designing different encoding networks to extract the tooth (local) and jaw (global) features, respectively. In addition to traditional metrics ADD, PA-ADD, CSA, and ME_{rot}, we propose a new evaluation metric based on dental arch curves to judge whether the generated teeth meet the individual normal occlusion. Experimental results demonstrate that our proposed method achieves state-of-the-art tooth alignment results and satisfactory occlusal relationships between dental arches. We will publish the code and dataset.
SMaRt: Improving GANs with Score Matching Regularity
Nov 30, 2023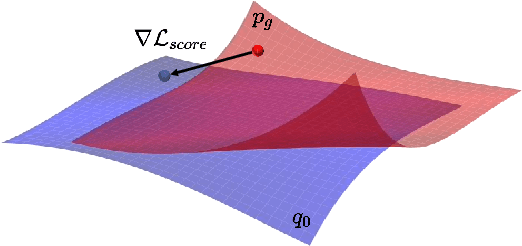

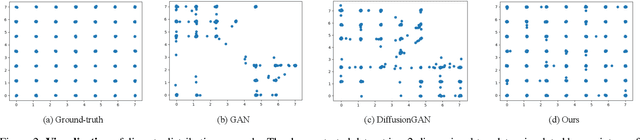
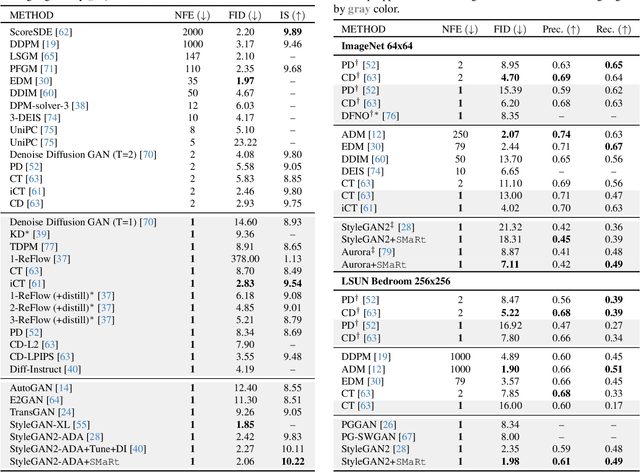
Generative adversarial networks (GANs) usually struggle in learning from highly diverse data, whose underlying manifold is complex. In this work, we revisit the mathematical foundations of GANs, and theoretically reveal that the native adversarial loss for GAN training is insufficient to fix the problem of subsets with positive Lebesgue measure of the generated data manifold lying out of the real data manifold. Instead, we find that score matching serves as a valid solution to this issue thanks to its capability of persistently pushing the generated data points towards the real data manifold. We thereby propose to improve the optimization of GANs with score matching regularity (SMaRt). Regarding the empirical evidences, we first design a toy example to show that training GANs by the aid of a ground-truth score function can help reproduce the real data distribution more accurately, and then confirm that our approach can consistently boost the synthesis performance of various state-of-the-art GANs on real-world datasets with pre-trained diffusion models acting as the approximate score function. For instance, when training Aurora on the ImageNet 64x64 dataset, we manage to improve FID from 8.87 to 7.11, on par with the performance of one-step consistency model. The source code will be made public.
Towards More Accurate Diffusion Model Acceleration with A Timestep Aligner
Oct 14, 2023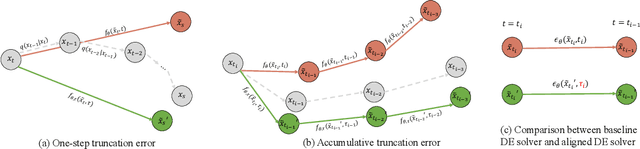
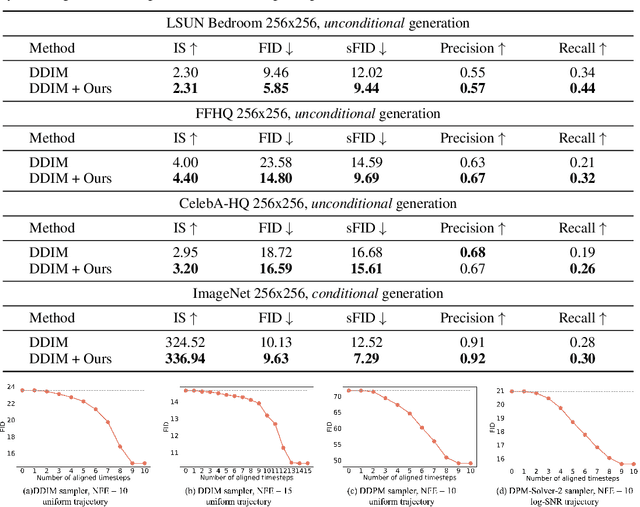
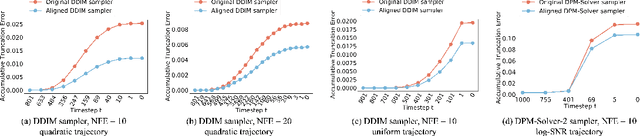

A diffusion model, which is formulated to produce an image using thousands of denoising steps, usually suffers from a slow inference speed. Existing acceleration algorithms simplify the sampling by skipping most steps yet exhibit considerable performance degradation. By viewing the generation of diffusion models as a discretized integrating process, we argue that the quality drop is partly caused by applying an inaccurate integral direction to a timestep interval. To rectify this issue, we propose a timestep aligner that helps find a more accurate integral direction for a particular interval at the minimum cost. Specifically, at each denoising step, we replace the original parameterization by conditioning the network on a new timestep, which is obtained by aligning the sampling distribution to the real distribution. Extensive experiments show that our plug-in design can be trained efficiently and boost the inference performance of various state-of-the-art acceleration methods, especially when there are few denoising steps. For example, when using 10 denoising steps on the popular LSUN Bedroom dataset, we improve the FID of DDIM from 9.65 to 6.07, simply by adopting our method for a more appropriate set of timesteps. Code will be made publicly available.
Audio-Driven Talking Face Video Generation with Dynamic Convolution Kernels
Jan 16, 2022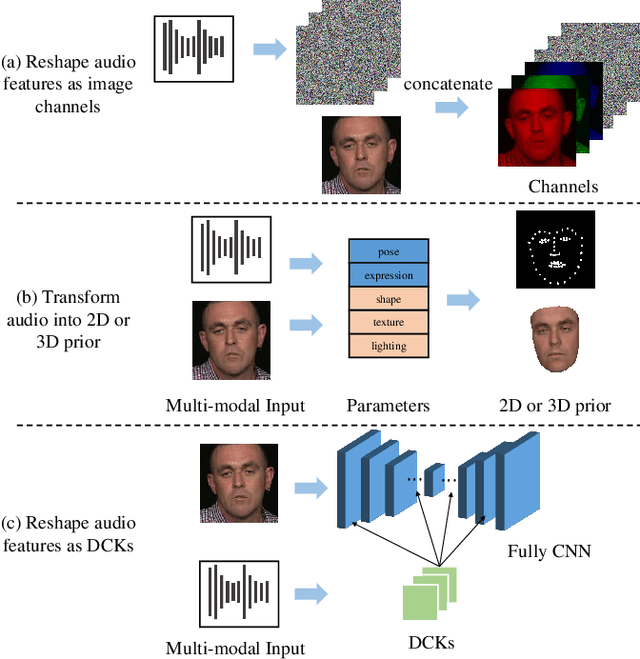
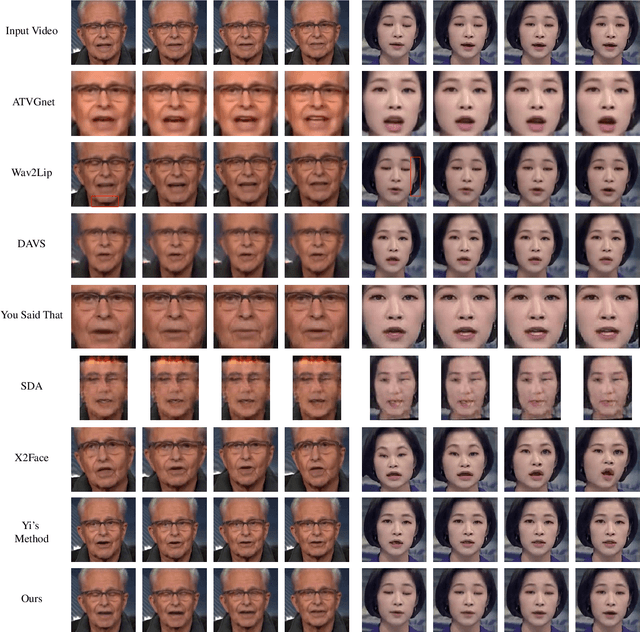
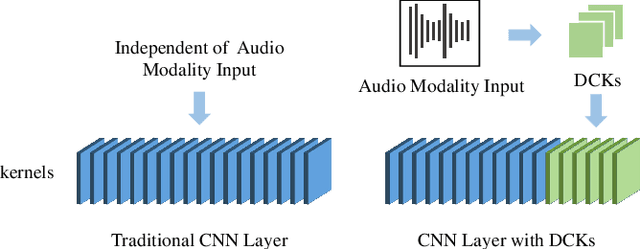
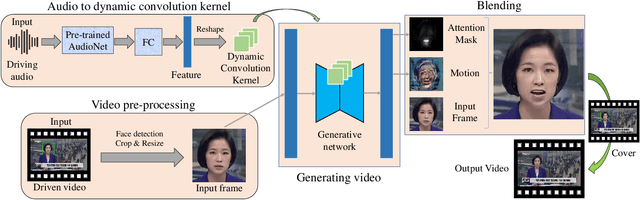
In this paper, we present a dynamic convolution kernel (DCK) strategy for convolutional neural networks. Using a fully convolutional network with the proposed DCKs, high-quality talking-face video can be generated from multi-modal sources (i.e., unmatched audio and video) in real time, and our trained model is robust to different identities, head postures, and input audios. Our proposed DCKs are specially designed for audio-driven talking face video generation, leading to a simple yet effective end-to-end system. We also provide a theoretical analysis to interpret why DCKs work. Experimental results show that our method can generate high-quality talking-face video with background at 60 fps. Comparison and evaluation between our method and the state-of-the-art methods demonstrate the superiority of our method.