 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTok: A Unified Video Tokenizer with Decoupled Spatial-Temporal Latents
Feb 04, 2026This work presents VTok, a unified video tokenization framework that can be used for both generation and understanding tasks. Unlike the leading vision-language systems that tokenize videos through a naive frame-sampling strategy, we propose to decouple the spatial and temporal representations of videos by retaining the spatial features of a single key frame while encoding each subsequent frame into a single residual token, achieving compact yet expressive video tokenization. Our experiments suggest that VTok effectively reduces the complexity of video representation from the product of frame count and per-frame token count to their sum, while the residual tokens sufficiently capture viewpoint and motion changes relative to the key frame. Extensive evaluations demonstrate the efficacy and efficiency of VTok: it achieves notably higher performance on a range of video understanding and text-to-video generation benchmarks compared with baselines using naive tokenization, all with shorter token sequences per video (e.g., 3.4% higher accuracy on our TV-Align benchmark and 1.9% higher VBench score). Remarkably, VTok produces more coherent motion and stronger guidance following in text-to-video generation, owing to its more consistent temporal encoding. We hope VTok can serve as a standardized video tokenization paradigm for future research in video understanding and generation.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
End-to-End Training for Autoregressive Video Diffusion via Self-Resampling
Dec 17, 2025
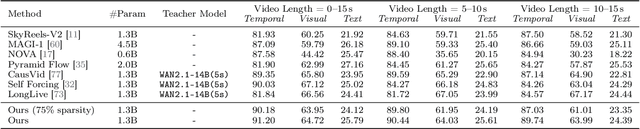
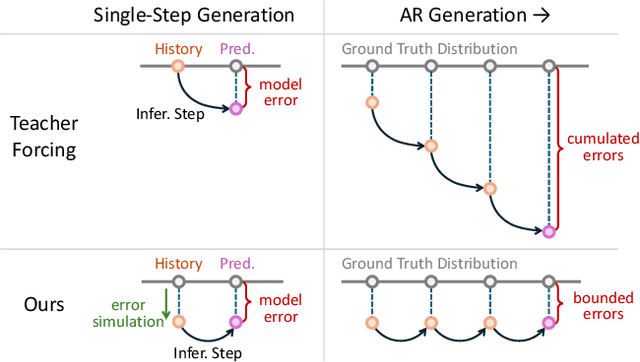

Autoregressive video diffusion models hold promise for world simulation but are vulnerable to exposure bias arising from the train-test mismatch. While recent works address this via post-training, they typically rely on a bidirectional teacher model or online discriminator. To achieve an end-to-end solution, we introduce Resampling Forcing, a teacher-free framework that enables training autoregressive video models from scratch and at scale. Central to our approach is a self-resampling scheme that simulates inference-time model errors on history frames during training. Conditioned on these degraded histories, a sparse causal mask enforces temporal causality while enabling parallel training with frame-level diffusion loss. To facilitate efficient long-horizon generation, we further introduce history routing, a parameter-free mechanism that dynamically retrieves the top-k most relevant history frames for each query. Experiments demonstrate that our approach achieves performance comparable to distillation-based baselines while exhibiting superior temporal consistency on longer videos owing to native-length training.
Mixture of Contexts for Long Video Generation
Aug 28, 2025Long video generation is fundamentally a long context memory problem: models must retain and retrieve salient events across a long range without collapsing or drifting. However, scaling diffusion transformers to generate long-context videos is fundamentally limited by the quadratic cost of self-attention, which makes memory and computation intractable and difficult to optimize for long sequences. We recast long-context video generation as an internal information retrieval task and propose a simple, learnable sparse attention routing module, Mixture of Contexts (MoC), as an effective long-term memory retrieval engine. In MoC, each query dynamically selects a few informative chunks plus mandatory anchors (caption, local windows) to attend to, with causal routing that prevents loop closures. As we scale the data and gradually sparsify the routing, the model allocates compute to salient history, preserving identities, actions, and scenes over minutes of content. Efficiency follows as a byproduct of retrieval (near-linear scaling), which enables practical training and synthesis, and the emergence of memory and consistency at the scale of minutes.
Captain Cinema: Towards Short Movie Generation
Jul 24, 2025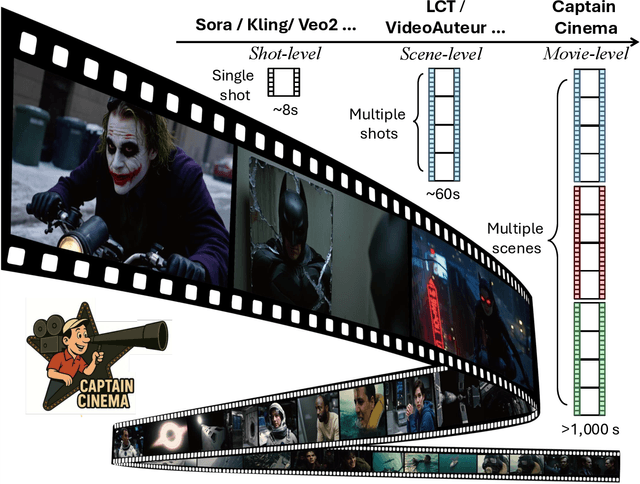
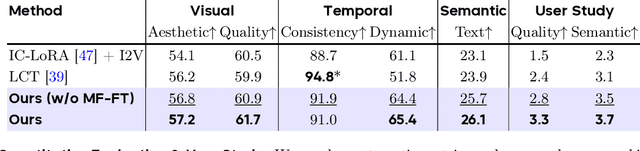

We present Captain Cinema, a generation framework for short movie generation. Given a detailed textual description of a movie storyline, our approach firstly generates a sequence of keyframes that outline the entire narrative, which ensures long-range coherence in both the storyline and visual appearance (e.g., scenes and characters). We refer to this step as top-down keyframe planning. These keyframes then serve as conditioning signals for a video synthesis model, which supports long context learning, to produce the spatio-temporal dynamics between them. This step is referred to as bottom-up video synthesis. To support stable and efficient generation of multi-scene long narrative cinematic works, we introduce an interleaved training strategy for Multimodal Diffusion Transformers (MM-DiT), specifically adapted for long-context video data. Our model is trained on a specially curated cinematic dataset consisting of interleaved data pairs. Our experiments demonstrate that Captain Cinema performs favorably in the automated creation of visually coherent and narrative consistent short movies in high quality and efficiency. Project page: https://thecinema.ai
UniMC: Taming Diffusion Transformer for Unified Keypoint-Guided Multi-Class Image Generation
Jul 03, 2025Although significant advancements have been achieved in the progress of keypoint-guided Text-to-Image diffusion models, existing mainstream keypoint-guided models encounter challenges in controlling the generation of more general non-rigid objects beyond humans (e.g., animals). Moreover, it is difficult to generate multiple overlapping humans and animals based on keypoint controls solely. These challenges arise from two main aspects: the inherent limitations of existing controllable methods and the lack of suitable datasets. First, we design a DiT-based framework, named UniMC, to explore unifying controllable multi-class image generation. UniMC integrates instance- and keypoint-level conditions into compact tokens, incorporating attributes such as class, bounding box, and keypoint coordinates. This approach overcomes the limitations of previous methods that struggled to distinguish instances and classes due to their reliance on skeleton images as conditions. Second, we propose HAIG-2.9M, a large-scale, high-quality, and diverse dataset designed for keypoint-guided human and animal image generation. HAIG-2.9M includes 786K images with 2.9M instances. This dataset features extensive annotations such as keypoints, bounding boxes, and fine-grained captions for both humans and animals, along with rigorous manual inspection to ensure annotation accuracy. Extensive experiments demonstrate the high quality of HAIG-2.9M and the effectiveness of UniMC, particularly in heavy occlusions and multi-class scenarios.
InterActHuman: Multi-Concept Human Animation with Layout-Aligned Audio Conditions
Jun 11, 2025



End-to-end human animation with rich multi-modal conditions, e.g., text, image and audio has achieved remarkable advancements in recent years. However, most existing methods could only animate a single subject and inject conditions in a global manner, ignoring scenarios that multiple concepts could appears in the same video with rich human-human interactions and human-object interactions. Such global assumption prevents precise and per-identity control of multiple concepts including humans and objects, therefore hinders applications. In this work, we discard the single-entity assumption and introduce a novel framework that enforces strong, region-specific binding of conditions from modalities to each identity's spatiotemporal footprint. Given reference images of multiple concepts, our method could automatically infer layout information by leveraging a mask predictor to match appearance cues between the denoised video and each reference appearance. Furthermore, we inject local audio condition into its corresponding region to ensure layout-aligned modality matching in a iterative manner. This design enables the high-quality generation of controllable multi-concept human-centric videos. Empirical results and ablation studies validate the effectiveness of our explicit layout control for multi-modal conditions compared to implicit counterparts and other existing methods.
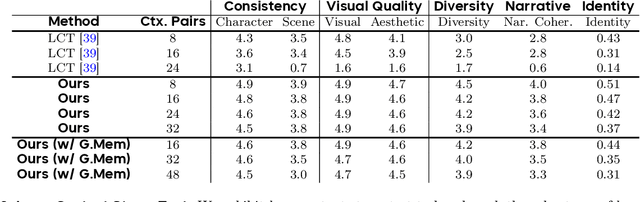
Autoregressive Adversarial Post-Training for Real-Time Interactive Video Generation
Jun 11, 2025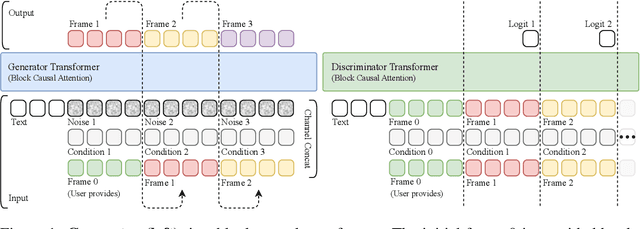
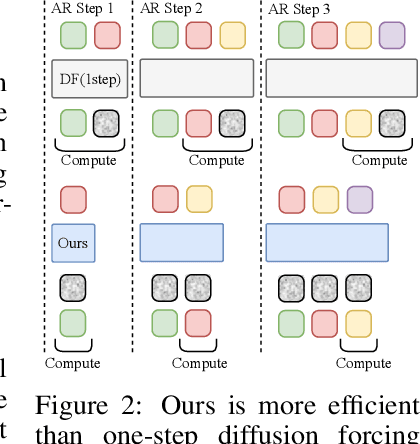
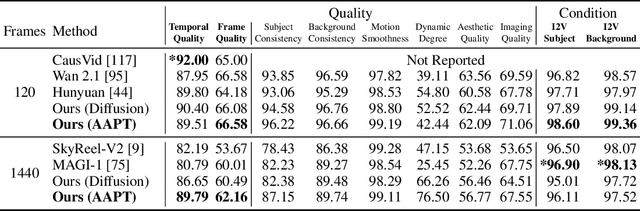

Existing large-scale video generation models are computationally intensive, preventing adoption in real-time and interactive applications. In this work, we propose autoregressive adversarial post-training (AAPT) to transform a pre-trained latent video diffusion model into a real-time, interactive video generator. Our model autoregressively generates a latent frame at a time using a single neural function evaluation (1NFE). The model can stream the result to the user in real time and receive interactive responses as controls to generate the next latent frame. Unlike existing approaches, our method explores adversarial training as an effective paradigm for autoregressive generation. This not only allows us to design an architecture that is more efficient for one-step generation while fully utilizing the KV cache, but also enables training the model in a student-forcing manner that proves to be effective in reducing error accumulation during long video generation. Our experiments demonstrate that our 8B model achieves real-time, 24fps, streaming video generation at 736x416 resolution on a single H100, or 1280x720 on 8xH100 up to a minute long (1440 frames). Visit our research website at https://seaweed-apt.com/2
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025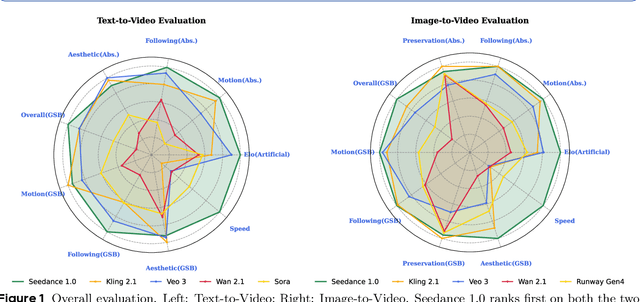
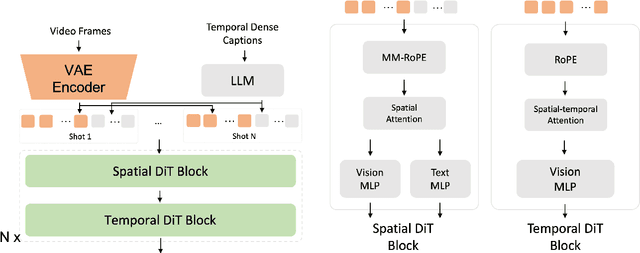
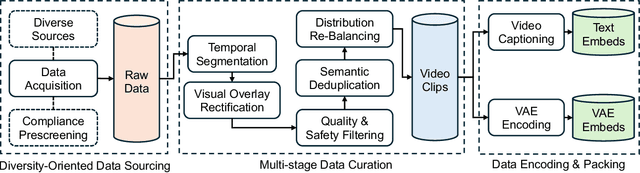
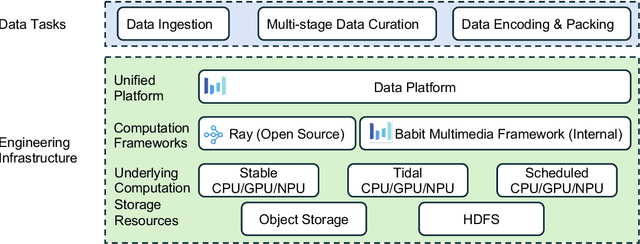
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
Jun 05, 2025



Recent advances in diffusion-based video restoration (VR) demonstrate significant improvement in visual quality, yet yield a prohibitive computational cost during inference. While several distillation-based approaches have exhibited the potential of one-step image restoration, extending existing approaches to VR remains challenging and underexplored, particularly when dealing with high-resolution video in real-world settings. In this work, we propose a one-step diffusion-based VR model, termed as SeedVR2, which performs adversarial VR training against real data. To handle the challenging high-resolution VR within a single step, we introduce several enhancements to both model architecture and training procedures. Specifically, an adaptive window attention mechanism is proposed, where the window size is dynamically adjusted to fit the output resolutions, avoiding window inconsistency observed under high-resolution VR using window attention with a predefined window size. To stabilize and improve the adversarial post-training towards VR, we further verify the effectiveness of a series of losses, including a proposed feature matching loss without significantly sacrificing training efficiency. Extensive experiments show that SeedVR2 can achieve comparable or even better performance compared with existing VR approaches in a single step.