 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniWeTok: An Unified Binary Tokenizer with Codebook Size $\mathit{2^{128}}$ for Unified Multimodal Large Language Model
Feb 15, 2026Unified Multimodal Large Language Models (MLLMs) require a visual representation that simultaneously supports high-fidelity reconstruction, complex semantic extraction, and generative suitability. However, existing visual tokenizers typically struggle to satisfy these conflicting objectives within a single framework. In this paper, we introduce UniWeTok, a unified discrete tokenizer designed to bridge this gap using a massive binary codebook ($\mathit{2^{128}}$). For training framework, we introduce Pre-Post Distillation and a Generative-Aware Prior to enhance the semantic extraction and generative prior of the discrete tokens. In terms of model architecture, we propose a convolution-attention hybrid architecture with the SigLu activation function. SigLu activation not only bounds the encoder output and stabilizes the semantic distillation process but also effectively addresses the optimization conflict between token entropy loss and commitment loss. We further propose a three-stage training framework designed to enhance UniWeTok's adaptability cross various image resolutions and perception-sensitive scenarios, such as those involving human faces and textual content. On ImageNet, UniWeTok achieves state-of-the-art image generation performance (FID: UniWeTok 1.38 vs. REPA 1.42) while requiring a remarkably low training compute (Training Tokens: UniWeTok 33B vs. REPA 262B). On general-domain, UniWeTok demonstrates highly competitive capabilities across a broad range of tasks, including multimodal understanding, image generation (DPG Score: UniWeTok 86.63 vs. FLUX.1 [Dev] 83.84), and editing (GEdit Overall Score: UniWeTok 5.09 vs. OmniGen 5.06). We release code and models to facilitate community exploration of unified tokenizer and MLLM.
BitDance: Scaling Autoregressive Generative Models with Binary Tokens
Feb 15, 2026We present BitDance, a scalable autoregressive (AR) image generator that predicts binary visual tokens instead of codebook indices. With high-entropy binary latents, BitDance lets each token represent up to $2^{256}$ states, yielding a compact yet highly expressive discrete representation. Sampling from such a huge token space is difficult with standard classification. To resolve this, BitDance uses a binary diffusion head: instead of predicting an index with softmax, it employs continuous-space diffusion to generate the binary tokens. Furthermore, we propose next-patch diffusion, a new decoding method that predicts multiple tokens in parallel with high accuracy, greatly speeding up inference. On ImageNet 256x256, BitDance achieves an FID of 1.24, the best among AR models. With next-patch diffusion, BitDance beats state-of-the-art parallel AR models that use 1.4B parameters, while using 5.4x fewer parameters (260M) and achieving 8.7x speedup. For text-to-image generation, BitDance trains on large-scale multimodal tokens and generates high-resolution, photorealistic images efficiently, showing strong performance and favorable scaling. When generating 1024x1024 images, BitDance achieves a speedup of over 30x compared to prior AR models. We release code and models to facilitate further research on AR foundation models. Code and models are available at: https://github.com/shallowdream204/BitDance.
Implicit Neural Representation Facilitates Unified Universal Vision Encoding
Jan 20, 2026Models for image representation learning are typically designed for either recognition or generation. Various forms of contrastive learning help models learn to convert images to embeddings that are useful for classification, detection, and segmentation. On the other hand, models can be trained to reconstruct images with pixel-wise, perceptual, and adversarial losses in order to learn a latent space that is useful for image generation. We seek to unify these two directions with a first-of-its-kind model that learns representations which are simultaneously useful for recognition and generation. We train our model as a hyper-network for implicit neural representation, which learns to map images to model weights for fast, accurate reconstruction. We further integrate our INR hyper-network with knowledge distillation to improve its generalization and performance. Beyond the novel training design, the model also learns an unprecedented compressed embedding space with outstanding performance for various visual tasks. The complete model competes with state-of-the-art results for image representation learning, while also enabling generative capabilities with its high-quality tiny embeddings. The code is available at https://github.com/tiktok/huvr.
End-to-End Training for Autoregressive Video Diffusion via Self-Resampling
Dec 17, 2025
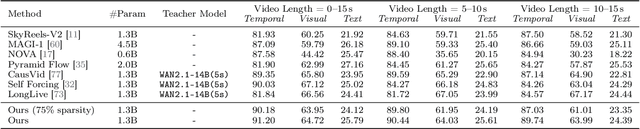
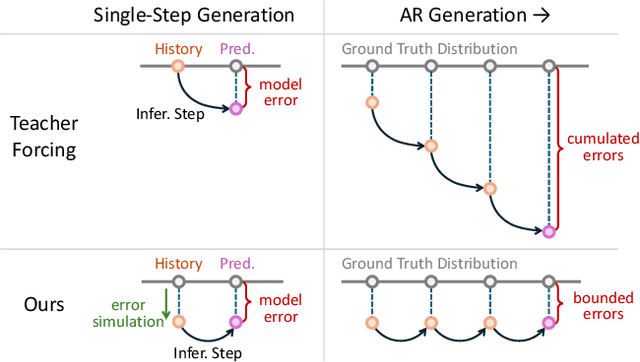

Autoregressive video diffusion models hold promise for world simulation but are vulnerable to exposure bias arising from the train-test mismatch. While recent works address this via post-training, they typically rely on a bidirectional teacher model or online discriminator. To achieve an end-to-end solution, we introduce Resampling Forcing, a teacher-free framework that enables training autoregressive video models from scratch and at scale. Central to our approach is a self-resampling scheme that simulates inference-time model errors on history frames during training. Conditioned on these degraded histories, a sparse causal mask enforces temporal causality while enabling parallel training with frame-level diffusion loss. To facilitate efficient long-horizon generation, we further introduce history routing, a parameter-free mechanism that dynamically retrieves the top-k most relevant history frames for each query. Experiments demonstrate that our approach achieves performance comparable to distillation-based baselines while exhibiting superior temporal consistency on longer videos owing to native-length training.
AgentComp: From Agentic Reasoning to Compositional Mastery in Text-to-Image Models
Dec 09, 2025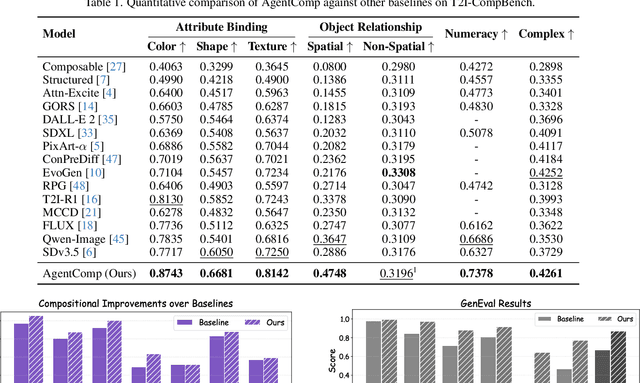

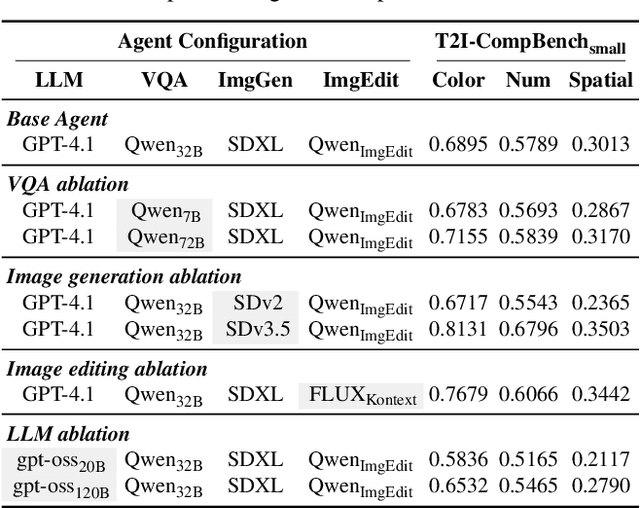
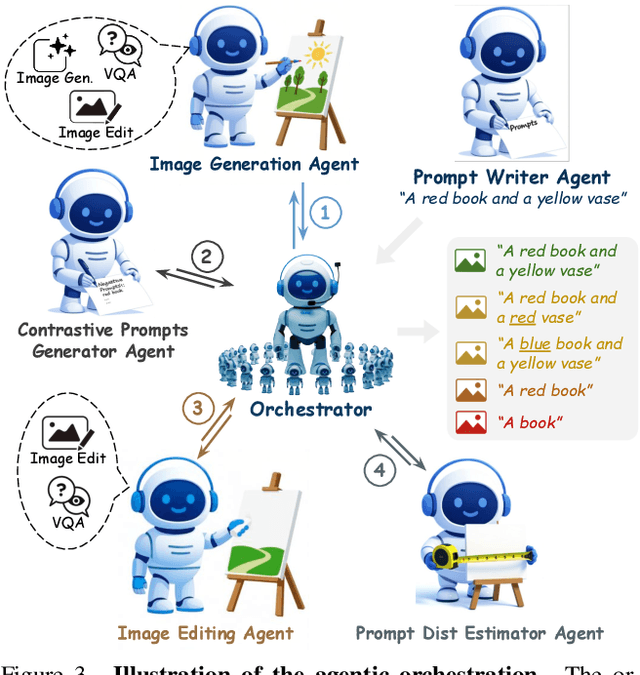
Text-to-image generative models have achieved remarkable visual quality but still struggle with compositionality$-$accurately capturing object relationships, attribute bindings, and fine-grained details in prompts. A key limitation is that models are not explicitly trained to differentiate between compositionally similar prompts and images, resulting in outputs that are close to the intended description yet deviate in fine-grained details. To address this, we propose AgentComp, a framework that explicitly trains models to better differentiate such compositional variations and enhance their reasoning ability. AgentComp leverages the reasoning and tool-use capabilities of large language models equipped with image generation, editing, and VQA tools to autonomously construct compositional datasets. Using these datasets, we apply an agentic preference optimization method to fine-tune text-to-image models, enabling them to better distinguish between compositionally similar samples and resulting in overall stronger compositional generation ability. AgentComp achieves state-of-the-art results on compositionality benchmarks such as T2I-CompBench, without compromising image quality$-$a common drawback in prior approaches$-$and even generalizes to other capabilities not explicitly trained for, such as text rendering.
FOCUS: Efficient Keyframe Selection for Long Video Understanding
Oct 31, 2025Multimodal large language models (MLLMs) represent images and video frames as visual tokens. Scaling from single images to hour-long videos, however, inflates the token budget far beyond practical limits. Popular pipelines therefore either uniformly subsample or apply keyframe selection with retrieval-style scoring using smaller vision-language models. However, these keyframe selection methods still rely on pre-filtering before selection to reduce the inference cost and can miss the most informative moments. We propose FOCUS, Frame-Optimistic Confidence Upper-bound Selection, a training-free, model-agnostic keyframe selection module that selects query-relevant frames under a strict token budget. FOCUS formulates keyframe selection as a combinatorial pure-exploration (CPE) problem in multi-armed bandits: it treats short temporal clips as arms, and uses empirical means and Bernstein confidence radius to identify informative regions while preserving exploration of uncertain areas. The resulting two-stage exploration-exploitation procedure reduces from a sequential policy with theoretical guarantees, first identifying high-value temporal regions, then selecting top-scoring frames within each region On two long-video question-answering benchmarks, FOCUS delivers substantial accuracy improvements while processing less than 2% of video frames. For videos longer than 20 minutes, it achieves an 11.9% gain in accuracy on LongVideoBench, demonstrating its effectiveness as a keyframe selection method and providing a simple and general solution for scalable long-video understanding with MLLMs.
Growing Visual Generative Capacity for Pre-Trained MLLMs
Oct 02, 2025Multimodal large language models (MLLMs) extend the success of language models to visual understanding, and recent efforts have sought to build unified MLLMs that support both understanding and generation. However, constructing such models remains challenging: hybrid approaches combine continuous embeddings with diffusion or flow-based objectives, producing high-quality images but breaking the autoregressive paradigm, while pure autoregressive approaches unify text and image prediction over discrete visual tokens but often face trade-offs between semantic alignment and pixel-level fidelity. In this work, we present Bridge, a pure autoregressive unified MLLM that augments pre-trained visual understanding models with generative ability through a Mixture-of-Transformers architecture, enabling both image understanding and generation within a single next-token prediction framework. To further improve visual generation fidelity, we propose a semantic-to-pixel discrete representation that integrates compact semantic tokens with fine-grained pixel tokens, achieving strong language alignment and precise description of visual details with only a 7.9% increase in sequence length. Extensive experiments across diverse multimodal benchmarks demonstrate that Bridge achieves competitive or superior results in both understanding and generation benchmarks, while requiring less training data and reduced training time compared to prior unified MLLMs.
Mixture of Contexts for Long Video Generation
Aug 28, 2025Long video generation is fundamentally a long context memory problem: models must retain and retrieve salient events across a long range without collapsing or drifting. However, scaling diffusion transformers to generate long-context videos is fundamentally limited by the quadratic cost of self-attention, which makes memory and computation intractable and difficult to optimize for long sequences. We recast long-context video generation as an internal information retrieval task and propose a simple, learnable sparse attention routing module, Mixture of Contexts (MoC), as an effective long-term memory retrieval engine. In MoC, each query dynamically selects a few informative chunks plus mandatory anchors (caption, local windows) to attend to, with causal routing that prevents loop closures. As we scale the data and gradually sparsify the routing, the model allocates compute to salient history, preserving identities, actions, and scenes over minutes of content. Efficiency follows as a byproduct of retrieval (near-linear scaling), which enables practical training and synthesis, and the emergence of memory and consistency at the scale of minutes.
UniAPO: Unified Multimodal Automated Prompt Optimization
Aug 25, 2025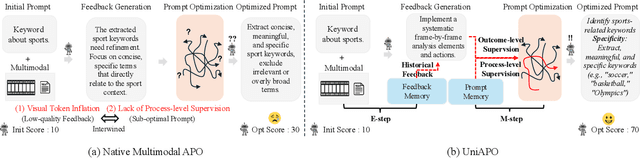
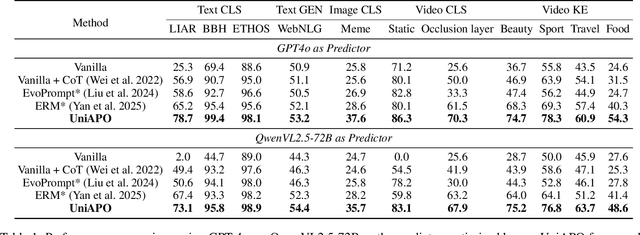
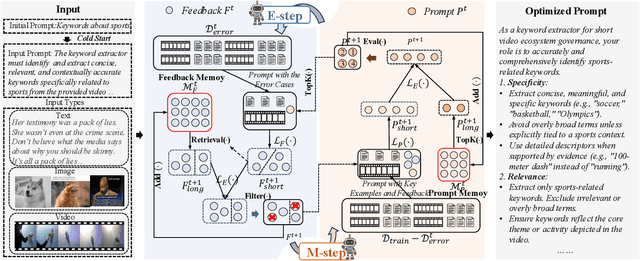
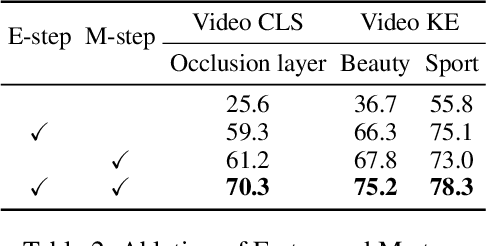
Prompting is fundamental to unlocking the full potential of large language models. To automate and enhance this process, automatic prompt optimization (APO) has been developed, demonstrating effectiveness primarily in text-only input scenarios. However, extending existing APO methods to multimodal tasks, such as video-language generation introduces two core challenges: (i) visual token inflation, where long visual token sequences restrict context capacity and result in insufficient feedback signals; (ii) a lack of process-level supervision, as existing methods focus on outcome-level supervision and overlook intermediate supervision, limiting prompt optimization. We present UniAPO: Unified Multimodal Automated Prompt Optimization, the first framework tailored for multimodal APO. UniAPO adopts an EM-inspired optimization process that decouples feedback modeling and prompt refinement, making the optimization more stable and goal-driven. To further address the aforementioned challenges, we introduce a short-long term memory mechanism: historical feedback mitigates context limitations, while historical prompts provide directional guidance for effective prompt optimization. UniAPO achieves consistent gains across text, image, and video benchmarks, establishing a unified framework for efficient and transferable prompt optimization.
Show-o2: Improved Native Unified Multimodal Models
Jun 18, 2025



This paper presents improved native unified multimodal models, \emph{i.e.,} Show-o2, that leverage autoregressive modeling and flow matching. Built upon a 3D causal variational autoencoder space, unified visual representations are constructed through a dual-path of spatial (-temporal) fusion, enabling scalability across image and video modalities while ensuring effective multimodal understanding and generation. Based on a language model, autoregressive modeling and flow matching are natively applied to the language head and flow head, respectively, to facilitate text token prediction and image/video generation. A two-stage training recipe is designed to effectively learn and scale to larger models. The resulting Show-o2 models demonstrate versatility in handling a wide range of multimodal understanding and generation tasks across diverse modalities, including text, images, and videos. Code and models are released at https://github.com/showlab/Show-o.