 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraHR-100K: Enhancing UHR Image Synthesis with A Large-Scale High-Quality Dataset
Oct 23, 2025

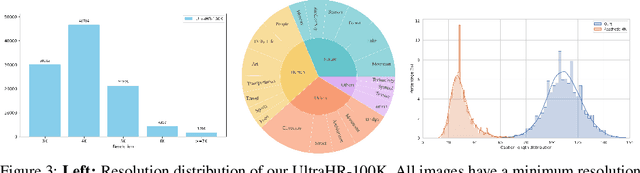
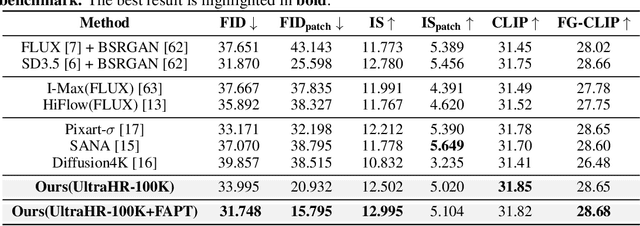
Ultra-high-resolution (UHR) text-to-image (T2I) generation has seen notable progress. However, two key challenges remain : 1) the absence of a large-scale high-quality UHR T2I dataset, and (2) the neglect of tailored training strategies for fine-grained detail synthesis in UHR scenarios. To tackle the first challenge, we introduce \textbf{UltraHR-100K}, a high-quality dataset of 100K UHR images with rich captions, offering diverse content and strong visual fidelity. Each image exceeds 3K resolution and is rigorously curated based on detail richness, content complexity, and aesthetic quality. To tackle the second challenge, we propose a frequency-aware post-training method that enhances fine-detail generation in T2I diffusion models. Specifically, we design (i) \textit{Detail-Oriented Timestep Sampling (DOTS)} to focus learning on detail-critical denoising steps, and (ii) \textit{Soft-Weighting Frequency Regularization (SWFR)}, which leverages Discrete Fourier Transform (DFT) to softly constrain frequency components, encouraging high-frequency detail preservation. Extensive experiments on our proposed UltraHR-eval4K benchmarks demonstrate that our approach significantly improves the fine-grained detail quality and overall fidelity of UHR image generation. The code is available at \href{https://github.com/NJU-PCALab/UltraHR-100k}{here}.
InstanceCap: Improving Text-to-Video Generation via Instance-aware Structured Caption
Dec 12, 2024



Text-to-video generation has evolved rapidly in recent years, delivering remarkable results. Training typically relies on video-caption paired data, which plays a crucial role in enhancing generation performance. However, current video captions often suffer from insufficient details, hallucinations and imprecise motion depiction, affecting the fidelity and consistency of generated videos. In this work, we propose a novel instance-aware structured caption framework, termed InstanceCap, to achieve instance-level and fine-grained video caption for the first time. Based on this scheme, we design an auxiliary models cluster to convert original video into instances to enhance instance fidelity. Video instances are further used to refine dense prompts into structured phrases, achieving concise yet precise descriptions. Furthermore, a 22K InstanceVid dataset is curated for training, and an enhancement pipeline that tailored to InstanceCap structure is proposed for inference. Experimental results demonstrate that our proposed InstanceCap significantly outperform previous models, ensuring high fidelity between captions and videos while reducing hallucinations.
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Jul 02, 2024



Text-to-video (T2V) generation has recently garnered significant attention thanks to the large multi-modality model Sora. However, T2V generation still faces two important challenges: 1) Lacking a precise open sourced high-quality dataset. The previous popular video datasets, e.g. WebVid-10M and Panda-70M, are either with low quality or too large for most research institutions. Therefore, it is challenging but crucial to collect a precise high-quality text-video pairs for T2V generation. 2) Ignoring to fully utilize textual information. Recent T2V methods have focused on vision transformers, using a simple cross attention module for video generation, which falls short of thoroughly extracting semantic information from text prompt. To address these issues, we introduce OpenVid-1M, a precise high-quality dataset with expressive captions. This open-scenario dataset contains over 1 million text-video pairs, facilitating research on T2V generation. Furthermore, we curate 433K 1080p videos from OpenVid-1M to create OpenVidHD-0.4M, advancing high-definition video generation. Additionally, we propose a novel Multi-modal Video Diffusion Transformer (MVDiT) capable of mining both structure information from visual tokens and semantic information from text tokens. Extensive experiments and ablation studies verify the superiority of OpenVid-1M over previous datasets and the effectiveness of our MVDiT.