 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBABE: Biology Arena BEnchmark
Feb 05, 2026The rapid evolution of large language models (LLMs) has expanded their capabilities from basic dialogue to advanced scientific reasoning. However, existing benchmarks in biology often fail to assess a critical skill required of researchers: the ability to integrate experimental results with contextual knowledge to derive meaningful conclusions. To address this gap, we introduce BABE(Biology Arena BEnchmark), a comprehensive benchmark designed to evaluate the experimental reasoning capabilities of biological AI systems. BABE is uniquely constructed from peer-reviewed research papers and real-world biological studies, ensuring that tasks reflect the complexity and interdisciplinary nature of actual scientific inquiry. BABE challenges models to perform causal reasoning and cross-scale inference. Our benchmark provides a robust framework for assessing how well AI systems can reason like practicing scientists, offering a more authentic measure of their potential to contribute to biological research.
VITA-VLA: Efficiently Teaching Vision-Language Models to Act via Action Expert Distillation
Oct 10, 2025Vision-Language Action (VLA) models significantly advance robotic manipulation by leveraging the strong perception capabilities of pretrained vision-language models (VLMs). By integrating action modules into these pretrained models, VLA methods exhibit improved generalization. However, training them from scratch is costly. In this work, we propose a simple yet effective distillation-based framework that equips VLMs with action-execution capability by transferring knowledge from pretrained small action models. Our architecture retains the original VLM structure, adding only an action token and a state encoder to incorporate physical inputs. To distill action knowledge, we adopt a two-stage training strategy. First, we perform lightweight alignment by mapping VLM hidden states into the action space of the small action model, enabling effective reuse of its pretrained action decoder and avoiding expensive pretraining. Second, we selectively fine-tune the language model, state encoder, and action modules, enabling the system to integrate multimodal inputs with precise action generation. Specifically, the action token provides the VLM with a direct handle for predicting future actions, while the state encoder allows the model to incorporate robot dynamics not captured by vision alone. This design yields substantial efficiency gains over training large VLA models from scratch. Compared with previous state-of-the-art methods, our method achieves 97.3% average success rate on LIBERO (11.8% improvement) and 93.5% on LIBERO-LONG (24.5% improvement). In real-world experiments across five manipulation tasks, our method consistently outperforms the teacher model, achieving 82.0% success rate (17% improvement), which demonstrate that action distillation effectively enables VLMs to generate precise actions while substantially reducing training costs.
BaseReward: A Strong Baseline for Multimodal Reward Model
Sep 19, 2025



The rapid advancement of Multimodal Large Language Models (MLLMs) has made aligning them with human preferences a critical challenge. Reward Models (RMs) are a core technology for achieving this goal, but a systematic guide for building state-of-the-art Multimodal Reward Models (MRMs) is currently lacking in both academia and industry. Through exhaustive experimental analysis, this paper aims to provide a clear ``recipe'' for constructing high-performance MRMs. We systematically investigate every crucial component in the MRM development pipeline, including \textit{reward modeling paradigms} (e.g., Naive-RM, Critic-based RM, and Generative RM), \textit{reward head architecture}, \textit{training strategies}, \textit{data curation} (covering over ten multimodal and text-only preference datasets), \textit{backbone model} and \textit{model scale}, and \textit{ensemble methods}. Based on these experimental insights, we introduce \textbf{BaseReward}, a powerful and efficient baseline for multimodal reward modeling. BaseReward adopts a simple yet effective architecture, built upon a {Qwen2.5-VL} backbone, featuring an optimized two-layer reward head, and is trained on a carefully curated mixture of high-quality multimodal and text-only preference data. Our results show that BaseReward establishes a new SOTA on major benchmarks such as MM-RLHF-Reward Bench, VL-Reward Bench, and Multimodal Reward Bench, outperforming previous models. Furthermore, to validate its practical utility beyond static benchmarks, we integrate BaseReward into a real-world reinforcement learning pipeline, successfully enhancing an MLLM's performance across various perception, reasoning, and conversational tasks. This work not only delivers a top-tier MRM but, more importantly, provides the community with a clear, empirically-backed guide for developing robust reward models for the next generation of MLLMs.
Zooming from Context to Cue: Hierarchical Preference Optimization for Multi-Image MLLMs
May 28, 2025Multi-modal Large Language Models (MLLMs) excel at single-image tasks but struggle with multi-image understanding due to cross-modal misalignment, leading to hallucinations (context omission, conflation, and misinterpretation). Existing methods using Direct Preference Optimization (DPO) constrain optimization to a solitary image reference within the input sequence, neglecting holistic context modeling. We propose Context-to-Cue Direct Preference Optimization (CcDPO), a multi-level preference optimization framework that enhances per-image perception in multi-image settings by zooming into visual clues -- from sequential context to local details. It features: (i) Context-Level Optimization : Re-evaluates cognitive biases underlying MLLMs' multi-image context comprehension and integrates a spectrum of low-cost global sequence preferences for bias mitigation. (ii) Needle-Level Optimization : Directs attention to fine-grained visual details through region-targeted visual prompts and multimodal preference supervision. To support scalable optimization, we also construct MultiScope-42k, an automatically generated dataset with high-quality multi-level preference pairs. Experiments show that CcDPO significantly reduces hallucinations and yields consistent performance gains across general single- and multi-image tasks.
MME-Reasoning: A Comprehensive Benchmark for Logical Reasoning in MLLMs
May 27, 2025Logical reasoning is a fundamental aspect of human intelligence and an essential capability for multimodal large language models (MLLMs). Despite the significant advancement in multimodal reasoning, existing benchmarks fail to comprehensively evaluate their reasoning abilities due to the lack of explicit categorization for logical reasoning types and an unclear understanding of reasoning. To address these issues, we introduce MME-Reasoning, a comprehensive benchmark designed to evaluate the reasoning ability of MLLMs, which covers all three types of reasoning (i.e., inductive, deductive, and abductive) in its questions. We carefully curate the data to ensure that each question effectively evaluates reasoning ability rather than perceptual skills or knowledge breadth, and extend the evaluation protocols to cover the evaluation of diverse questions. Our evaluation reveals substantial limitations of state-of-the-art MLLMs when subjected to holistic assessments of logical reasoning capabilities. Even the most advanced MLLMs show limited performance in comprehensive logical reasoning, with notable performance imbalances across reasoning types. In addition, we conducted an in-depth analysis of approaches such as ``thinking mode'' and Rule-based RL, which are commonly believed to enhance reasoning abilities. These findings highlight the critical limitations and performance imbalances of current MLLMs in diverse logical reasoning scenarios, providing comprehensive and systematic insights into the understanding and evaluation of reasoning capabilities.
MME-VideoOCR: Evaluating OCR-Based Capabilities of Multimodal LLMs in Video Scenarios
May 27, 2025Multimodal Large Language Models (MLLMs) have achieved considerable accuracy in Optical Character Recognition (OCR) from static images. However, their efficacy in video OCR is significantly diminished due to factors such as motion blur, temporal variations, and visual effects inherent in video content. To provide clearer guidance for training practical MLLMs, we introduce the MME-VideoOCR benchmark, which encompasses a comprehensive range of video OCR application scenarios. MME-VideoOCR features 10 task categories comprising 25 individual tasks and spans 44 diverse scenarios. These tasks extend beyond text recognition to incorporate deeper comprehension and reasoning of textual content within videos. The benchmark consists of 1,464 videos with varying resolutions, aspect ratios, and durations, along with 2,000 meticulously curated, manually annotated question-answer pairs. We evaluate 18 state-of-the-art MLLMs on MME-VideoOCR, revealing that even the best-performing model (Gemini-2.5 Pro) achieves an accuracy of only 73.7%. Fine-grained analysis indicates that while existing MLLMs demonstrate strong performance on tasks where relevant texts are contained within a single or few frames, they exhibit limited capability in effectively handling tasks that demand holistic video comprehension. These limitations are especially evident in scenarios that require spatio-temporal reasoning, cross-frame information integration, or resistance to language prior bias. Our findings also highlight the importance of high-resolution visual input and sufficient temporal coverage for reliable OCR in dynamic video scenarios.
VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model
May 06, 2025With the growing requirement for natural human-computer interaction, speech-based systems receive increasing attention as speech is one of the most common forms of daily communication. However, the existing speech models still experience high latency when generating the first audio token during streaming, which poses a significant bottleneck for deployment. To address this issue, we propose VITA-Audio, an end-to-end large speech model with fast audio-text token generation. Specifically, we introduce a lightweight Multiple Cross-modal Token Prediction (MCTP) module that efficiently generates multiple audio tokens within a single model forward pass, which not only accelerates the inference but also significantly reduces the latency for generating the first audio in streaming scenarios. In addition, a four-stage progressive training strategy is explored to achieve model acceleration with minimal loss of speech quality. To our knowledge, VITA-Audio is the first multi-modal large language model capable of generating audio output during the first forward pass, enabling real-time conversational capabilities with minimal latency. VITA-Audio is fully reproducible and is trained on open-source data only. Experimental results demonstrate that our model achieves an inference speedup of 3~5x at the 7B parameter scale, but also significantly outperforms open-source models of similar model size on multiple benchmarks for automatic speech recognition (ASR), text-to-speech (TTS), and spoken question answering (SQA) tasks.
R1-Reward: Training Multimodal Reward Model Through Stable Reinforcement Learning
May 05, 2025Multimodal Reward Models (MRMs) play a crucial role in enhancing the performance of Multimodal Large Language Models (MLLMs). While recent advancements have primarily focused on improving the model structure and training data of MRMs, there has been limited exploration into the effectiveness of long-term reasoning capabilities for reward modeling and how to activate these capabilities in MRMs. In this paper, we explore how Reinforcement Learning (RL) can be used to improve reward modeling. Specifically, we reformulate the reward modeling problem as a rule-based RL task. However, we observe that directly applying existing RL algorithms, such as Reinforce++, to reward modeling often leads to training instability or even collapse due to the inherent limitations of these algorithms. To address this issue, we propose the StableReinforce algorithm, which refines the training loss, advantage estimation strategy, and reward design of existing RL methods. These refinements result in more stable training dynamics and superior performance. To facilitate MRM training, we collect 200K preference data from diverse datasets. Our reward model, R1-Reward, trained using the StableReinforce algorithm on this dataset, significantly improves performance on multimodal reward modeling benchmarks. Compared to previous SOTA models, R1-Reward achieves a $8.4\%$ improvement on the VL Reward-Bench and a $14.3\%$ improvement on the Multimodal Reward Bench. Moreover, with more inference compute, R1-Reward's performance is further enhanced, highlighting the potential of RL algorithms in optimizing MRMs.
MME-Unify: A Comprehensive Benchmark for Unified Multimodal Understanding and Generation Models
Apr 07, 2025Existing MLLM benchmarks face significant challenges in evaluating Unified MLLMs (U-MLLMs) due to: 1) lack of standardized benchmarks for traditional tasks, leading to inconsistent comparisons; 2) absence of benchmarks for mixed-modality generation, which fails to assess multimodal reasoning capabilities. We present a comprehensive evaluation framework designed to systematically assess U-MLLMs. Our benchmark includes: Standardized Traditional Task Evaluation. We sample from 12 datasets, covering 10 tasks with 30 subtasks, ensuring consistent and fair comparisons across studies." 2. Unified Task Assessment. We introduce five novel tasks testing multimodal reasoning, including image editing, commonsense QA with image generation, and geometric reasoning. 3. Comprehensive Model Benchmarking. We evaluate 12 leading U-MLLMs, such as Janus-Pro, EMU3, VILA-U, and Gemini2-flash, alongside specialized understanding (e.g., Claude-3.5-Sonnet) and generation models (e.g., DALL-E-3). Our findings reveal substantial performance gaps in existing U-MLLMs, highlighting the need for more robust models capable of handling mixed-modality tasks effectively. The code and evaluation data can be found in https://mme-unify.github.io/.
Aligning Multimodal LLM with Human Preference: A Survey
Mar 18, 2025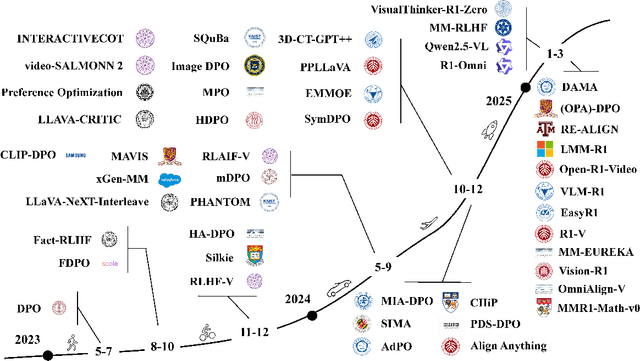
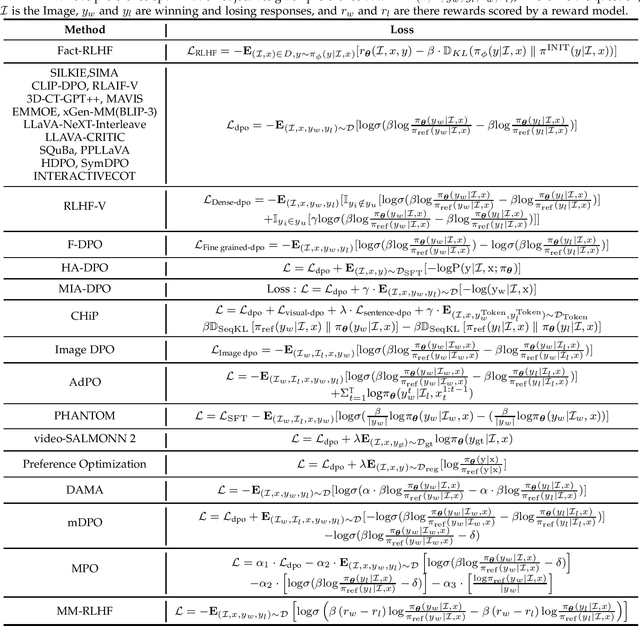
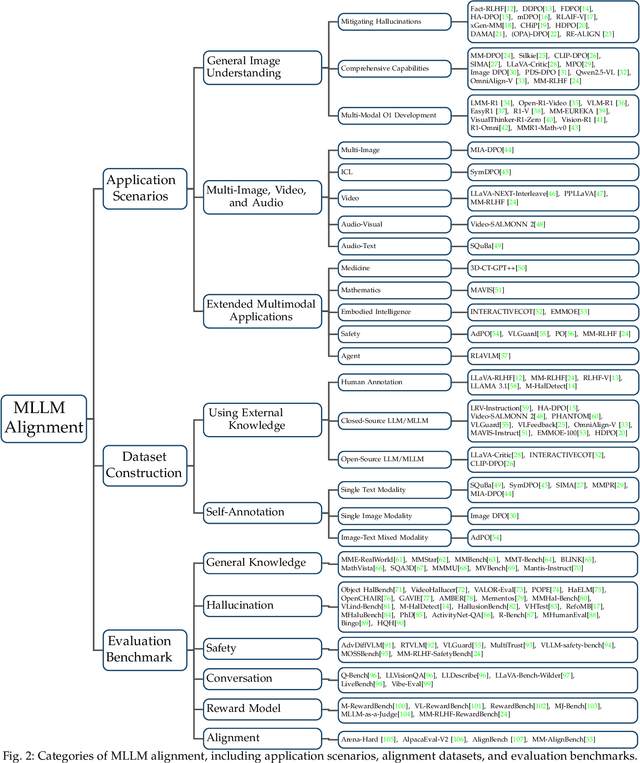
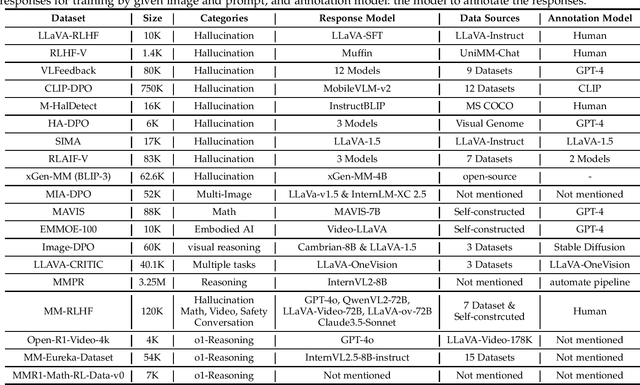
Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.