 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOsmosis Distillation: Model Hijacking with the Fewest Samples
Mar 05, 2026Transfer learning is devised to leverage knowledge from pre-trained models to solve new tasks with limited data and computational resources. Meanwhile, dataset distillation has emerged to synthesize a compact dataset that preserves critical information from the original large dataset. Therefore, a combination of transfer learning and dataset distillation offers promising performance in evaluations. However, a non-negligible security threat remains undiscovered in transfer learning using synthetic datasets generated by dataset distillation methods, where an adversary can perform a model hijacking attack with only a few poisoned samples in the synthetic dataset. To reveal this threat, we propose Osmosis Distillation (OD) attack, a novel model hijacking strategy that targets deep learning models using the fewest samples. Comprehensive evaluations on various datasets demonstrate that the OD attack attains high attack success rates in hidden tasks while preserving high model utility in original tasks. Furthermore, the distilled osmosis set enables model hijacking across diverse model architectures, allowing model hijacking in transfer learning with considerable attack performance and model utility. We argue that awareness of using third-party synthetic datasets in transfer learning must be raised.
EdgeFLow: Serverless Federated Learning via Sequential Model Migration in Edge Networks
Mar 03, 2026Federated Learning (FL) has emerged as a transformative distributed learning paradigm in the era of Internet of Things (IoT), reconceptualizing data processing methodologies. However, FL systems face significant communication bottlenecks due to inevitable client-server data exchanges and long-distance transmissions. This work presents EdgeFLow, an innovative FL framework that redesigns the system topology by replacing traditional cloud servers with sequential model migration between edge base stations. By conducting model aggregation and propagation exclusively at edge clusters, EdgeFLow eliminates cloud-based transmissions and substantially reduces global communication overhead. We provide rigorous convergence analysis for EdgeFLow under non-convex objectives and non-IID data distributions, extending classical FL convergence theory. Experimental results across various configurations validate the theoretical analysis, demonstrating that EdgeFLow achieves comparable accuracy improvements while significantly reducing communication costs. As a systemic architectural innovation for communication-efficient FL, EdgeFLow establishes a foundational framework for future developments in IoT and edge-network learning systems.
Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization
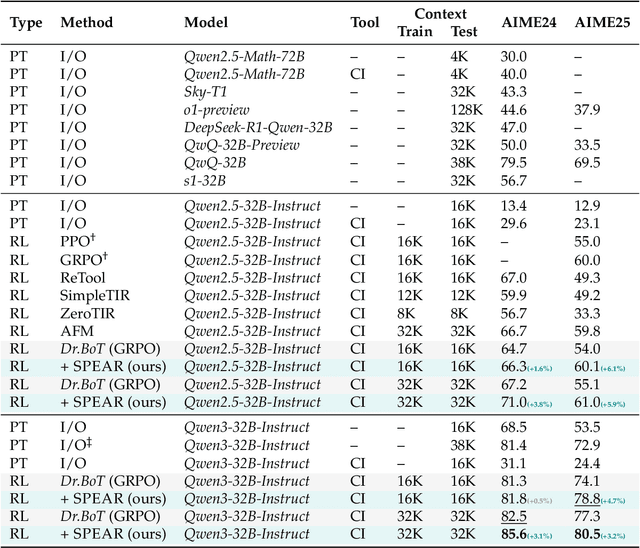
Dec 31, 2025Existing Large Language Model (LLM) agent frameworks face two significant challenges: high configuration costs and static capabilities. Building a high-quality agent often requires extensive manual effort in tool integration and prompt engineering, while deployed agents struggle to adapt to dynamic environments without expensive fine-tuning. To address these issues, we propose \textbf{Youtu-Agent}, a modular framework designed for the automated generation and continuous evolution of LLM agents. Youtu-Agent features a structured configuration system that decouples execution environments, toolkits, and context management, enabling flexible reuse and automated synthesis. We introduce two generation paradigms: a \textbf{Workflow} mode for standard tasks and a \textbf{Meta-Agent} mode for complex, non-standard requirements, capable of automatically generating tool code, prompts, and configurations. Furthermore, Youtu-Agent establishes a hybrid policy optimization system: (1) an \textbf{Agent Practice} module that enables agents to accumulate experience and improve performance through in-context optimization without parameter updates; and (2) an \textbf{Agent RL} module that integrates with distributed training frameworks to enable scalable and stable reinforcement learning of any Youtu-Agents in an end-to-end, large-scale manner. Experiments demonstrate that Youtu-Agent achieves state-of-the-art performance on WebWalkerQA (71.47\%) and GAIA (72.8\%) using open-weight models. Our automated generation pipeline achieves over 81\% tool synthesis success rate, while the Practice module improves performance on AIME 2024/2025 by +2.7\% and +5.4\% respectively. Moreover, our Agent RL training achieves 40\% speedup with steady performance improvement on 7B LLMs, enhancing coding/reasoning and searching capabilities respectively up to 35\% and 21\% on Maths and general/multi-hop QA benchmarks.
SmartSnap: Proactive Evidence Seeking for Self-Verifying Agents
Dec 26, 2025Agentic reinforcement learning (RL) holds great promise for the development of autonomous agents under complex GUI tasks, but its scalability remains severely hampered by the verification of task completion. Existing task verification is treated as a passive, post-hoc process: a verifier (i.e., rule-based scoring script, reward or critic model, and LLM-as-a-Judge) analyzes the agent's entire interaction trajectory to determine if the agent succeeds. Such processing of verbose context that contains irrelevant, noisy history poses challenges to the verification protocols and therefore leads to prohibitive cost and low reliability. To overcome this bottleneck, we propose SmartSnap, a paradigm shift from this passive, post-hoc verification to proactive, in-situ self-verification by the agent itself. We introduce the Self-Verifying Agent, a new type of agent designed with dual missions: to not only complete a task but also to prove its accomplishment with curated snapshot evidences. Guided by our proposed 3C Principles (Completeness, Conciseness, and Creativity), the agent leverages its accessibility to the online environment to perform self-verification on a minimal, decisive set of snapshots. Such evidences are provided as the sole materials for a general LLM-as-a-Judge verifier to determine their validity and relevance. Experiments on mobile tasks across model families and scales demonstrate that our SmartSnap paradigm allows training LLM-driven agents in a scalable manner, bringing performance gains up to 26.08% and 16.66% respectively to 8B and 30B models. The synergizing between solution finding and evidence seeking facilitates the cultivation of efficient, self-verifying agents with competitive performance against DeepSeek V3.1 and Qwen3-235B-A22B.
Learn the Ropes, Then Trust the Wins: Self-imitation with Progressive Exploration for Agentic Reinforcement Learning
Sep 26, 2025
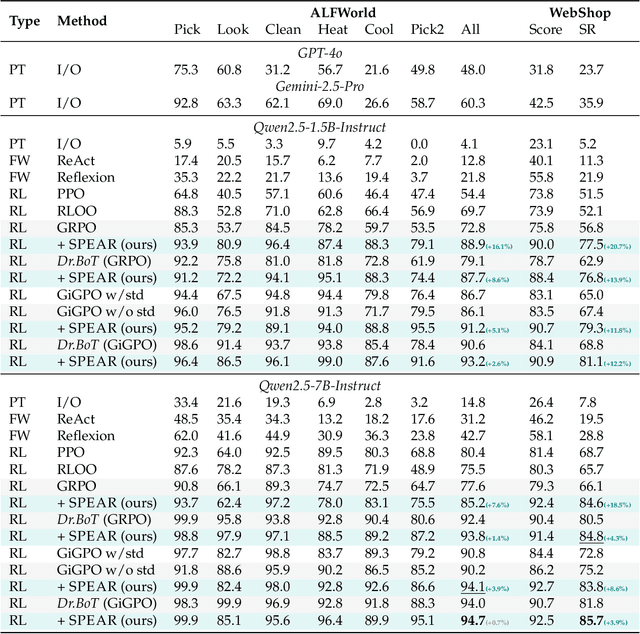
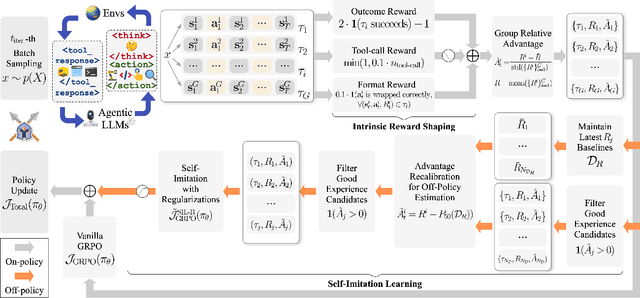
Reinforcement learning (RL) is the dominant paradigm for sharpening strategic tool use capabilities of LLMs on long-horizon, sparsely-rewarded agent tasks, yet it faces a fundamental challenge of exploration-exploitation trade-off. Existing studies stimulate exploration through the lens of policy entropy, but such mechanical entropy maximization is prone to RL training instability due to the multi-turn distribution shifting. In this paper, we target the progressive exploration-exploitation balance under the guidance of the agent own experiences without succumbing to either entropy collapsing or runaway divergence. We propose SPEAR, a curriculum-based self-imitation learning (SIL) recipe for training agentic LLMs. It extends the vanilla SIL framework, where a replay buffer stores self-generated promising trajectories for off-policy update, by gradually steering the policy evolution within a well-balanced range of entropy across stages. Specifically, our approach incorporates a curriculum to manage the exploration process, utilizing intrinsic rewards to foster skill-level exploration and facilitating action-level exploration through SIL. At first, the auxiliary tool call reward plays a critical role in the accumulation of tool-use skills, enabling broad exposure to the unfamiliar distributions of the environment feedback with an upward entropy trend. As training progresses, self-imitation gets strengthened to exploit existing successful patterns from replayed experiences for comparative action-level exploration, accelerating solution iteration without unbounded entropy growth. To further stabilize training, we recalibrate the advantages of experiences in the replay buffer to address the potential policy drift. Reugularizations such as the clipping of tokens with high covariance between probability and advantage are introduced to the trajectory-level entropy control to curb over-confidence.
FlowAgent: Achieving Compliance and Flexibility for Workflow Agents
Feb 20, 2025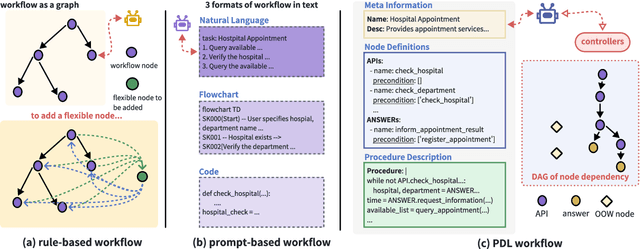

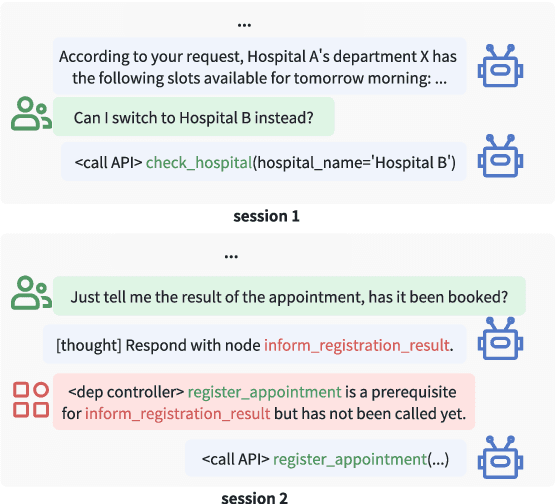
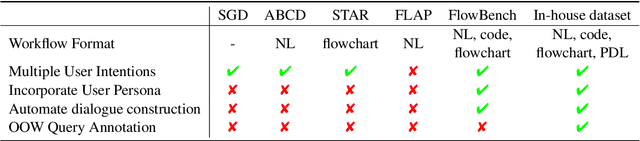
The integration of workflows with large language models (LLMs) enables LLM-based agents to execute predefined procedures, enhancing automation in real-world applications. Traditional rule-based methods tend to limit the inherent flexibility of LLMs, as their predefined execution paths restrict the models' action space, particularly when the unexpected, out-of-workflow (OOW) queries are encountered. Conversely, prompt-based methods allow LLMs to fully control the flow, which can lead to diminished enforcement of procedural compliance. To address these challenges, we introduce FlowAgent, a novel agent framework designed to maintain both compliance and flexibility. We propose the Procedure Description Language (PDL), which combines the adaptability of natural language with the precision of code to formulate workflows. Building on PDL, we develop a comprehensive framework that empowers LLMs to manage OOW queries effectively, while keeping the execution path under the supervision of a set of controllers. Additionally, we present a new evaluation methodology to rigorously assess an LLM agent's ability to handle OOW scenarios, going beyond routine flow compliance tested in existing benchmarks. Experiments on three datasets demonstrate that FlowAgent not only adheres to workflows but also effectively manages OOW queries, highlighting its dual strengths in compliance and flexibility. The code is available at https://github.com/Lightblues/FlowAgent.
LUCY: Linguistic Understanding and Control Yielding Early Stage of Her
Jan 27, 2025



The film Her features Samantha, a sophisticated AI audio agent who is capable of understanding both linguistic and paralinguistic information in human speech and delivering real-time responses that are natural, informative and sensitive to emotional subtleties. Moving one step toward more sophisticated audio agent from recent advancement in end-to-end (E2E) speech systems, we propose LUCY, a E2E speech model that (1) senses and responds to user's emotion, (2) deliver responses in a succinct and natural style, and (3) use external tool to answer real-time inquiries. Experiment results show that LUCY is better at emotion control than peer models, generating emotional responses based on linguistic emotional instructions and responding to paralinguistic emotional cues. Lucy is also able to generate responses in a more natural style, as judged by external language models, without sacrificing much performance on general question answering. Finally, LUCY can leverage function calls to answer questions that are out of its knowledge scope.
Exploring Critical Testing Scenarios for Decision-Making Policies: An LLM Approach
Dec 09, 2024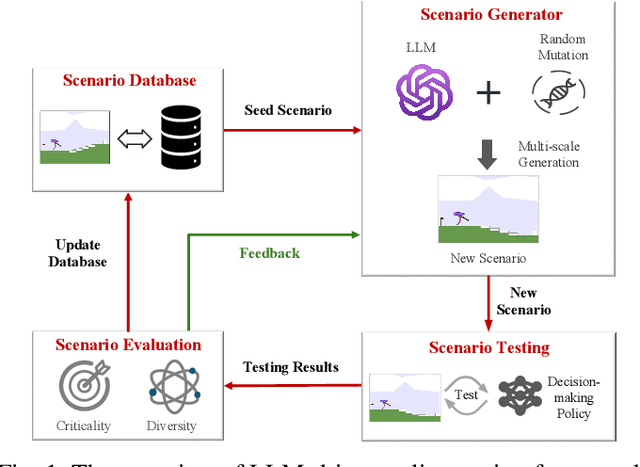
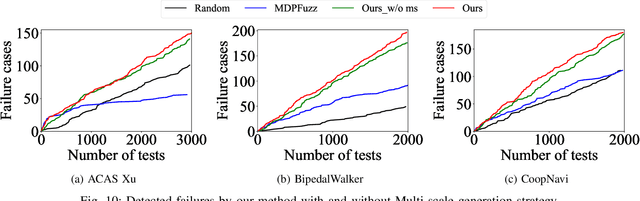
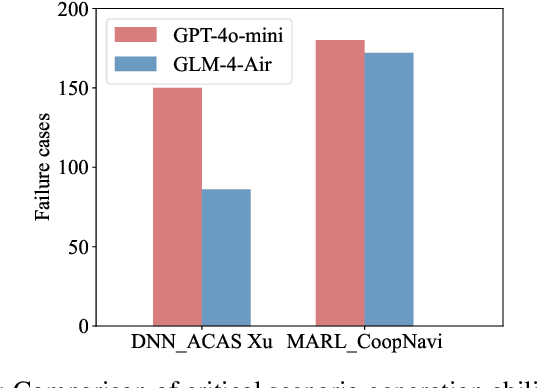

Recent years have witnessed surprising achievements of decision-making policies across various fields, such as autonomous driving and robotics. Testing for decision-making policies is crucial with the existence of critical scenarios that may threaten their reliability. Numerous research efforts have been dedicated to testing these policies. However, there are still significant challenges, such as low testing efficiency and diversity due to the complexity of the policies and environments under test. Inspired by the remarkable capabilities of large language models (LLMs), in this paper, we propose an LLM-driven online testing framework for efficiently testing decision-making policies. The main idea is to employ an LLM-based test scenario generator to intelligently generate challenging test cases through contemplation and reasoning. Specifically, we first design a "generate-test-feedback" pipeline and apply templated prompt engineering to fully leverage the knowledge and reasoning abilities of LLMs. Then, we introduce a multi-scale scenario generation strategy to address the inherent challenges LLMs face in making fine adjustments, further enhancing testing efficiency. Finally, we evaluate the LLM-driven approach on five widely used benchmarks. The experimental results demonstrate that our method significantly outperforms baseline approaches in uncovering both critical and diverse scenarios.
Towards Fault Tolerance in Multi-Agent Reinforcement Learning
Nov 30, 2024



Agent faults pose a significant threat to the performance of multi-agent reinforcement learning (MARL) algorithms, introducing two key challenges. First, agents often struggle to extract critical information from the chaotic state space created by unexpected faults. Second, transitions recorded before and after faults in the replay buffer affect training unevenly, leading to a sample imbalance problem. To overcome these challenges, this paper enhances the fault tolerance of MARL by combining optimized model architecture with a tailored training data sampling strategy. Specifically, an attention mechanism is incorporated into the actor and critic networks to automatically detect faults and dynamically regulate the attention given to faulty agents. Additionally, a prioritization mechanism is introduced to selectively sample transitions critical to current training needs. To further support research in this area, we design and open-source a highly decoupled code platform for fault-tolerant MARL, aimed at improving the efficiency of studying related problems. Experimental results demonstrate the effectiveness of our method in handling various types of faults, faults occurring in any agent, and faults arising at random times.
AgentRE: An Agent-Based Framework for Navigating Complex Information Landscapes in Relation Extraction
Sep 03, 2024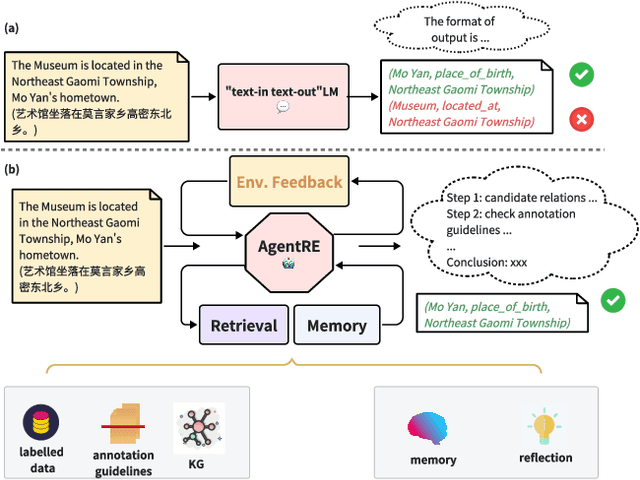
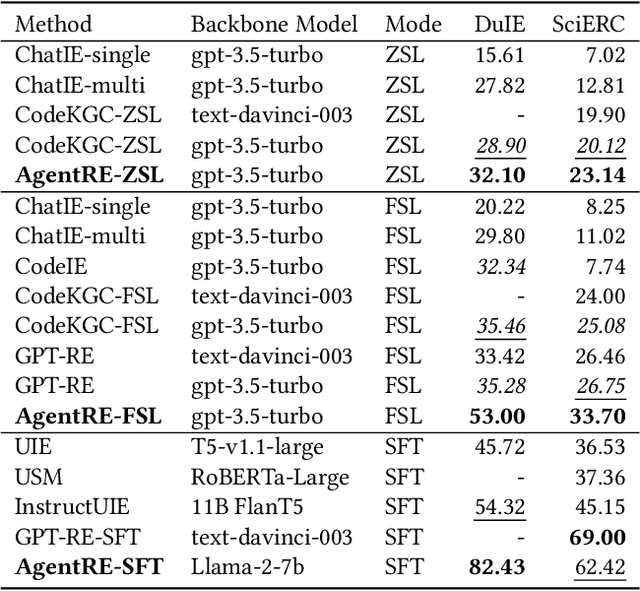
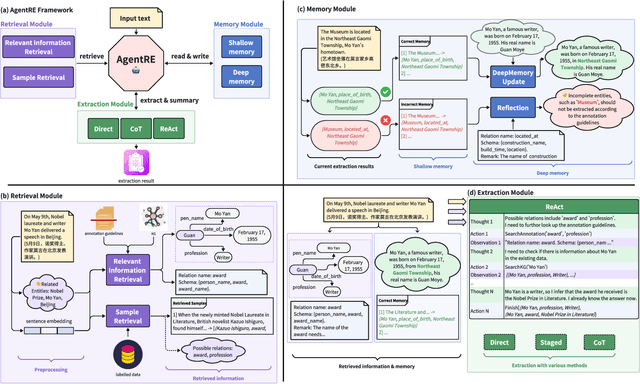
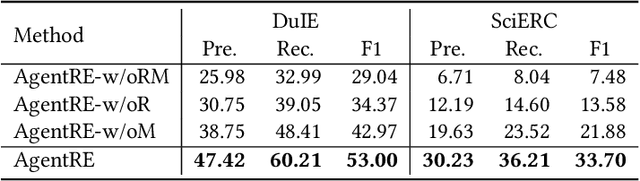
The relation extraction (RE) in complex scenarios faces challenges such as diverse relation types and ambiguous relations between entities within a single sentence, leading to the poor performance of pure "text-in, text-out" language models (LMs). To address these challenges, in this paper, we propose an agent-based RE framework, namely AgentRE, which fully leverages the potential of large language models (LLMs) including memory, retrieval and reflection, to achieve RE in complex scenarios. Specifically, three major modules are built in AgentRE serving as the tools to help the agent acquire and process various useful information, thereby obtaining improved RE performance. Our extensive experimental results upon two datasets in English and Chinese demonstrate our AgentRE's superior performance, especially in low-resource scenarios. Additionally, the trajectories generated by AgentRE can be refined to construct a high-quality training dataset incorporating different reasoning methods, which can be used to fine-tune smaller models. Code is available at https://github.com/Lightblues/AgentRE.