 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Modeling and Control of Emergent Behaviors in Robot Swarms
Jun 01, 2026Robot swarms can exhibit coherent collective behaviors through local perception, limited communication and decentralized decision-making, yet modeling and controlling such emergence remains challenging when behaviors unfold over multiple phases. Here we introduce PhySwarm, a physics-informed micro--macro framework that represents multi-stage swarm emergence as physically constrained density-field evolution coupled to executable robot motion. At the macroscopic level, a multi-phase advection--diffusion--reaction model (Macro-ADR) describes phase-dependent swarm-density evolution through directed transport, diffusion-based spatial regulation and behavioral phase transitions. At the microscopic level, an equivalent deterministic motion model (Micro-EDM) realizes these mechanisms through potential-field advection, density-gradient compensation and rate- or event-gated phase switching. A neural-physics controller (NPC) maps local observations and temporal memory to bounded physical parameters, and is trained with a reinforcement learning--PINN objective that combines task rewards with macro-scale density residuals and micro-scale motion-consistency constraints. In several proof-of-concept swarm missions -- including trail-guided foraging, formation-reconfigurable navigation and role-adaptive search and rescue -- we demonstrate that PhySwarm can generate distinct multi-stage emergent behaviors within a unified physics-informed modeling framework. The learned density fields and physical parameters provide interpretable evidence of how advection, diffusion and reaction jointly regulate multi-stage swarm organization. These results establish a physics-informed route for learning, interpreting and controlling emergent behaviors in robot swarms.
VisMMOE: Exploiting Visual-Expert Affinity for Efficient Visual-Language MoE Offloading
May 07, 2026Large-scale vision-language mixture-of-experts (VL-MoE) models provide strong multimodal capability, but efficient deployment on memory-constrained platforms remains difficult. Existing MoE offloading systems are largely designed for text-centric workloads and become much less effective for visual-heavy inputs, where large numbers of visual tokens induce broader and less predictable expert accesses. We present VisMMoE, a VL-MoE offloading system built on a single systems insight: pruning redundant visual tokens can improve offloading not only by reducing computation, but also by reshaping expert demand. We refer to this effect as \textit{visual-expert affinity}: token pruning makes expert accesses more concentrated within layers and more stable across layers, producing a smaller and more predictable expert working set. Guided by this insight, VisMMoE combines affinity-aware token compression, lookahead expert prediction, and cache/pipeline orchestration to improve expert locality and prefetch effectiveness under tight memory budgets. We implement VisMMoE on multiple frameworks and evaluate it on representative VL-MoE models and benchmarks. VisMMoE improves end-to-end inference performance by up to 2.68x and 1.61x, respectively, over strong baselines for today's VL-MoE deployments while maintaining competitive accuracy.
LiveFact: A Dynamic, Time-Aware Benchmark for LLM-Driven Fake News Detection
Apr 06, 2026The rapid development of Large Language Models (LLMs) has transformed fake news detection and fact-checking tasks from simple classification to complex reasoning. However, evaluation frameworks have not kept pace. Current benchmarks are static, making them vulnerable to benchmark data contamination (BDC) and ineffective at assessing reasoning under temporal uncertainty. To address this, we introduce LiveFact a continuously updated benchmark that simulates the real-world "fog of war" in misinformation detection. LiveFact uses dynamic, temporal evidence sets to evaluate models on their ability to reason with evolving, incomplete information rather than on memorized knowledge. We propose a dual-mode evaluation: Classification Mode for final verification and Inference Mode for evidence-based reasoning, along with a component to monitor BDC explicitly. Tests with 22 LLMs show that open-source Mixture-of-Experts models, such as Qwen3-235B-A22B, now match or outperform proprietary state-of-the-art systems. More importantly, our analysis finds a significant "reasoning gap." Capable models exhibit epistemic humility by recognizing unverifiable claims in early data slices-an aspect traditional static benchmarks overlook. LiveFact sets a sustainable standard for evaluating robust, temporally aware AI verification.
DCR: Quantifying Data Contamination in LLMs Evaluation
Jul 15, 2025The rapid advancement of large language models (LLMs) has heightened concerns about benchmark data contamination (BDC), where models inadvertently memorize evaluation data, inflating performance metrics and undermining genuine generalization assessment. This paper introduces the Data Contamination Risk (DCR) framework, a lightweight, interpretable pipeline designed to detect and quantify BDC across four granular levels: semantic, informational, data, and label. By synthesizing contamination scores via a fuzzy inference system, DCR produces a unified DCR Factor that adjusts raw accuracy to reflect contamination-aware performance. Validated on 9 LLMs (0.5B-72B) across sentiment analysis, fake news detection, and arithmetic reasoning tasks, the DCR framework reliably diagnoses contamination severity and with accuracy adjusted using the DCR Factor to within 4% average error across the three benchmarks compared to the uncontaminated baseline. Emphasizing computational efficiency and transparency, DCR provides a practical tool for integrating contamination assessment into routine evaluations, fostering fairer comparisons and enhancing the credibility of LLM benchmarking practices.
Scalable Complexity Control Facilitates Reasoning Ability of LLMs
May 29, 2025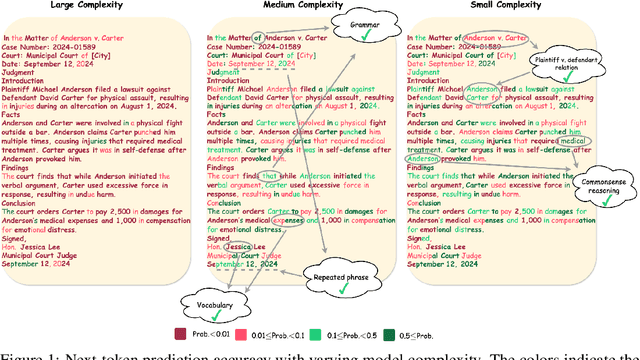
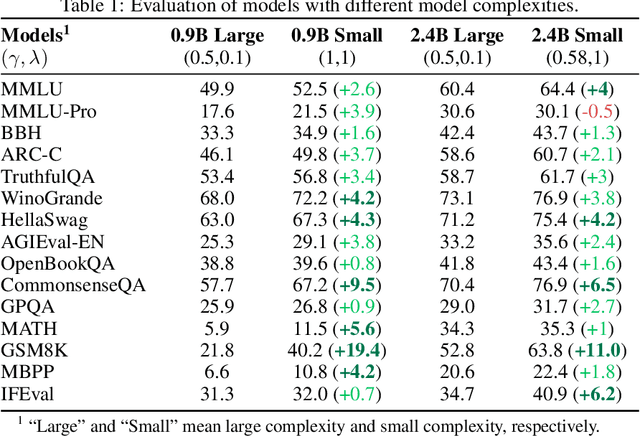
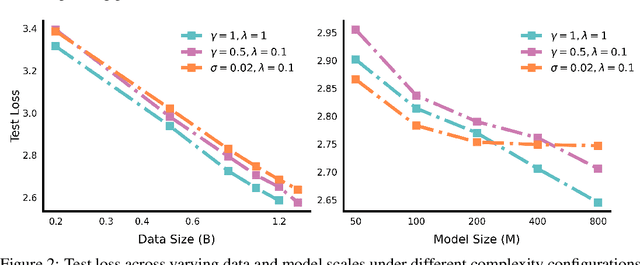
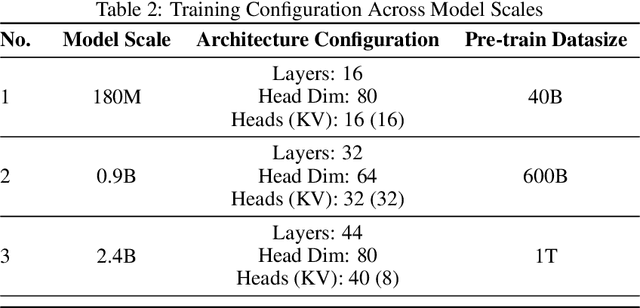
The reasoning ability of large language models (LLMs) has been rapidly advancing in recent years, attracting interest in more fundamental approaches that can reliably enhance their generalizability. This work demonstrates that model complexity control, conveniently implementable by adjusting the initialization rate and weight decay coefficient, improves the scaling law of LLMs consistently over varying model sizes and data sizes. This gain is further illustrated by comparing the benchmark performance of 2.4B models pretrained on 1T tokens with different complexity hyperparameters. Instead of fixing the initialization std, we found that a constant initialization rate (the exponent of std) enables the scaling law to descend faster in both model and data sizes. These results indicate that complexity control is a promising direction for the continual advancement of LLMs.
PreP-OCR: A Complete Pipeline for Document Image Restoration and Enhanced OCR Accuracy
May 28, 2025This paper introduces PreP-OCR, a two-stage pipeline that combines document image restoration with semantic-aware post-OCR correction to enhance both visual clarity and textual consistency, thereby improving text extraction from degraded historical documents. First, we synthesize document-image pairs from plaintext, rendering them with diverse fonts and layouts and then applying a randomly ordered set of degradation operations. An image restoration model is trained on this synthetic data, using multi-directional patch extraction and fusion to process large images. Second, a ByT5 post-OCR model, fine-tuned on synthetic historical text pairs, addresses remaining OCR errors. Detailed experiments on 13,831 pages of real historical documents in English, French, and Spanish show that the PreP-OCR pipeline reduces character error rates by 63.9-70.3% compared to OCR on raw images. Our pipeline demonstrates the potential of integrating image restoration with linguistic error correction for digitizing historical archives.
SCJD: Sparse Correlation and Joint Distillation for Efficient 3D Human Pose Estimation
Mar 18, 2025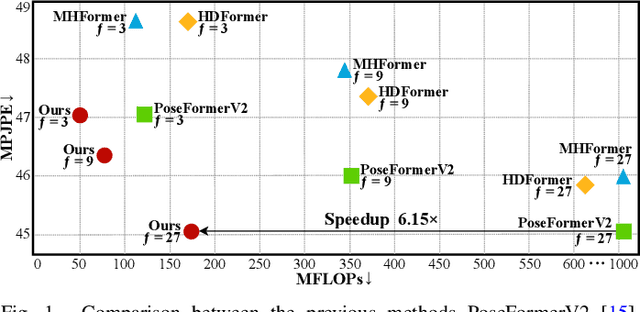
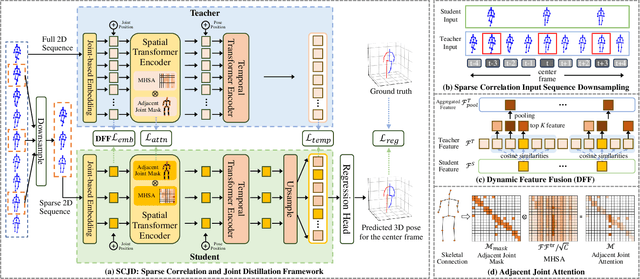
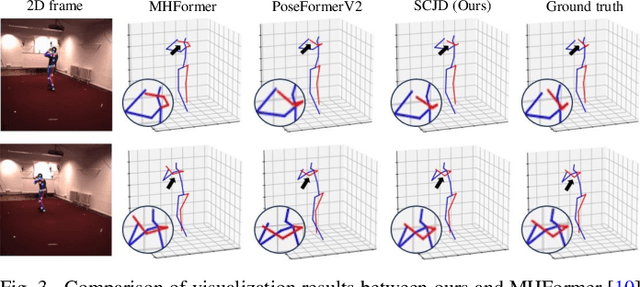
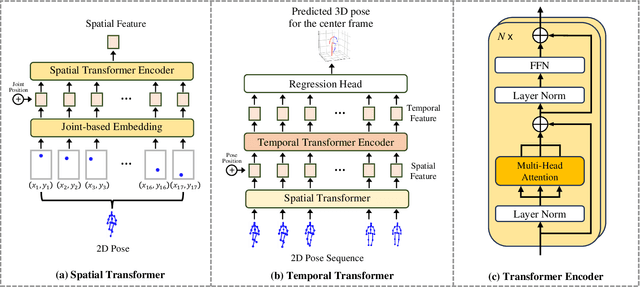
Existing 3D Human Pose Estimation (HPE) methods achieve high accuracy but suffer from computational overhead and slow inference, while knowledge distillation methods fail to address spatial relationships between joints and temporal correlations in multi-frame inputs. In this paper, we propose Sparse Correlation and Joint Distillation (SCJD), a novel framework that balances efficiency and accuracy for 3D HPE. SCJD introduces Sparse Correlation Input Sequence Downsampling to reduce redundancy in student network inputs while preserving inter-frame correlations. For effective knowledge transfer, we propose Dynamic Joint Spatial Attention Distillation, which includes Dynamic Joint Embedding Distillation to enhance the student's feature representation using the teacher's multi-frame context feature, and Adjacent Joint Attention Distillation to improve the student network's focus on adjacent joint relationships for better spatial understanding. Additionally, Temporal Consistency Distillation aligns the temporal correlations between teacher and student networks through upsampling and global supervision. Extensive experiments demonstrate that SCJD achieves state-of-the-art performance. Code is available at https://github.com/wileychan/SCJD.
Rotation-Adaptive Point Cloud Domain Generalization via Intricate Orientation Learning
Feb 04, 2025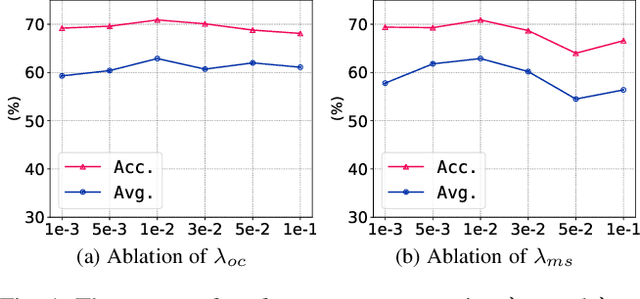



The vulnerability of 3D point cloud analysis to unpredictable rotations poses an open yet challenging problem: orientation-aware 3D domain generalization. Cross-domain robustness and adaptability of 3D representations are crucial but not easily achieved through rotation augmentation. Motivated by the inherent advantages of intricate orientations in enhancing generalizability, we propose an innovative rotation-adaptive domain generalization framework for 3D point cloud analysis. Our approach aims to alleviate orientational shifts by leveraging intricate samples in an iterative learning process. Specifically, we identify the most challenging rotation for each point cloud and construct an intricate orientation set by optimizing intricate orientations. Subsequently, we employ an orientation-aware contrastive learning framework that incorporates an orientation consistency loss and a margin separation loss, enabling effective learning of categorically discriminative and generalizable features with rotation consistency. Extensive experiments and ablations conducted on 3D cross-domain benchmarks firmly establish the state-of-the-art performance of our proposed approach in the context of orientation-aware 3D domain generalization.
Dr. Tongue: Sign-Oriented Multi-label Detection for Remote Tongue Diagnosis
Jan 06, 2025Tongue diagnosis is a vital tool in Western and Traditional Chinese Medicine, providing key insights into a patient's health by analyzing tongue attributes. The COVID-19 pandemic has heightened the need for accurate remote medical assessments, emphasizing the importance of precise tongue attribute recognition via telehealth. To address this, we propose a Sign-Oriented multi-label Attributes Detection framework. Our approach begins with an adaptive tongue feature extraction module that standardizes tongue images and mitigates environmental factors. This is followed by a Sign-oriented Network (SignNet) that identifies specific tongue attributes, emulating the diagnostic process of experienced practitioners and enabling comprehensive health evaluations. To validate our methodology, we developed an extensive tongue image dataset specifically designed for telemedicine. Unlike existing datasets, ours is tailored for remote diagnosis, with a comprehensive set of attribute labels. This dataset will be openly available, providing a valuable resource for research. Initial tests have shown improved accuracy in detecting various tongue attributes, highlighting our framework's potential as an essential tool for remote medical assessments.
Subgoal-based Hierarchical Reinforcement Learning for Multi-Agent Collaboration
Aug 21, 2024Recent advancements in reinforcement learning have made significant impacts across various domains, yet they often struggle in complex multi-agent environments due to issues like algorithm instability, low sampling efficiency, and the challenges of exploration and dimensionality explosion. Hierarchical reinforcement learning (HRL) offers a structured approach to decompose complex tasks into simpler sub-tasks, which is promising for multi-agent settings. This paper advances the field by introducing a hierarchical architecture that autonomously generates effective subgoals without explicit constraints, enhancing both flexibility and stability in training. We propose a dynamic goal generation strategy that adapts based on environmental changes. This method significantly improves the adaptability and sample efficiency of the learning process. Furthermore, we address the critical issue of credit assignment in multi-agent systems by synergizing our hierarchical architecture with a modified QMIX network, thus improving overall strategy coordination and efficiency. Comparative experiments with mainstream reinforcement learning algorithms demonstrate the superior convergence speed and performance of our approach in both single-agent and multi-agent environments, confirming its effectiveness and flexibility in complex scenarios. Our code is open-sourced at: \url{https://github.com/SICC-Group/GMAH}.