 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Complexity Control Facilitates Reasoning Ability of LLMs
May 29, 2025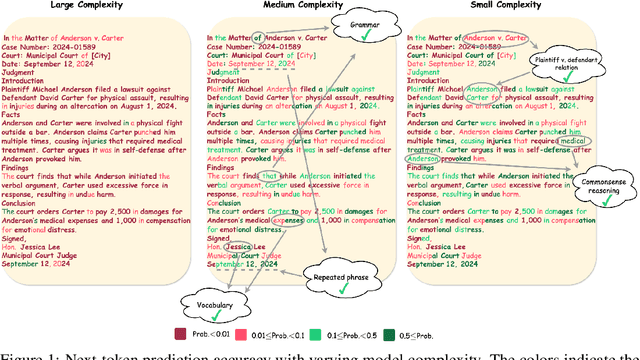
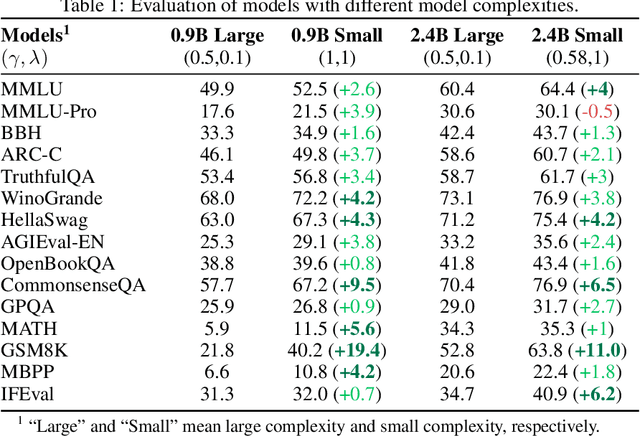
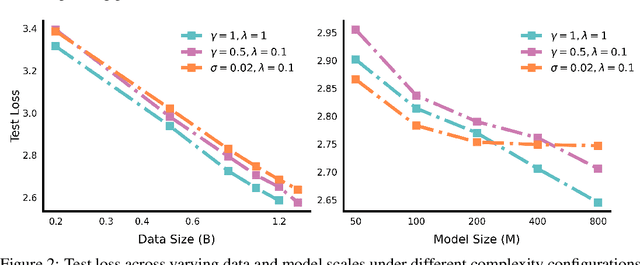
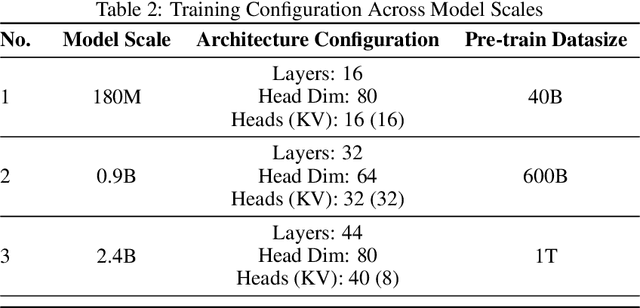
The reasoning ability of large language models (LLMs) has been rapidly advancing in recent years, attracting interest in more fundamental approaches that can reliably enhance their generalizability. This work demonstrates that model complexity control, conveniently implementable by adjusting the initialization rate and weight decay coefficient, improves the scaling law of LLMs consistently over varying model sizes and data sizes. This gain is further illustrated by comparing the benchmark performance of 2.4B models pretrained on 1T tokens with different complexity hyperparameters. Instead of fixing the initialization std, we found that a constant initialization rate (the exponent of std) enables the scaling law to descend faster in both model and data sizes. These results indicate that complexity control is a promising direction for the continual advancement of LLMs.
An Analysis for Reasoning Bias of Language Models with Small Initialization
Feb 05, 2025Transformer-based Large Language Models (LLMs) have revolutionized Natural Language Processing by demonstrating exceptional performance across diverse tasks. This study investigates the impact of the parameter initialization scale on the training behavior and task preferences of LLMs. We discover that smaller initialization scales encourage models to favor reasoning tasks, whereas larger initialization scales lead to a preference for memorization tasks. We validate this reasoning bias via real datasets and meticulously designed anchor functions. Further analysis of initial training dynamics suggests that specific model components, particularly the embedding space and self-attention mechanisms, play pivotal roles in shaping these learning biases. We provide a theoretical framework from the perspective of model training dynamics to explain these phenomena. Additionally, experiments on real-world language tasks corroborate our theoretical insights. This work enhances our understanding of how initialization strategies influence LLM performance on reasoning tasks and offers valuable guidelines for training models.
Anchor function: a type of benchmark functions for studying language models
Jan 16, 2024Understanding transformer-based language models is becoming increasingly crucial, particularly as they play pivotal roles in advancing towards artificial general intelligence. However, language model research faces significant challenges, especially for academic research groups with constrained resources. These challenges include complex data structures, unknown target functions, high computational costs and memory requirements, and a lack of interpretability in the inference process, etc. Drawing a parallel to the use of simple models in scientific research, we propose the concept of an anchor function. This is a type of benchmark function designed for studying language models in learning tasks that follow an "anchor-key" pattern. By utilizing the concept of an anchor function, we can construct a series of functions to simulate various language tasks. The anchor function plays a role analogous to that of mice in diabetes research, particularly suitable for academic research. We demonstrate the utility of the anchor function with an example, revealing two basic operations by attention structures in language models: shifting tokens and broadcasting one token from one position to many positions. These operations are also commonly observed in large language models. The anchor function framework, therefore, opens up a series of valuable and accessible research questions for further exploration, especially for theoretical study.
Ophtha-LLaMA2: A Large Language Model for Ophthalmology
Dec 08, 2023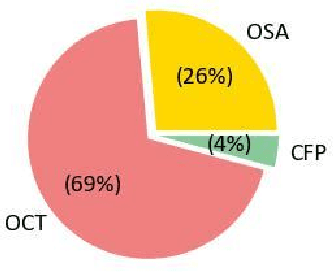

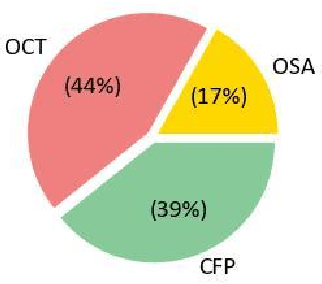
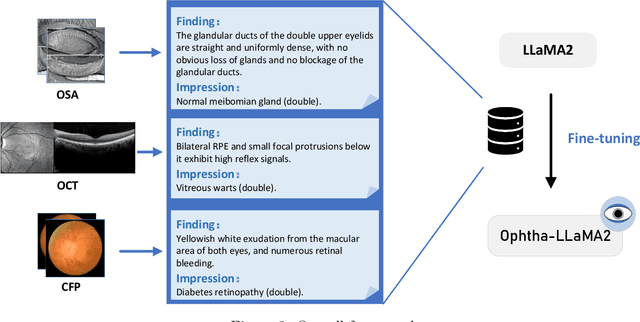
In recent years, pre-trained large language models (LLMs) have achieved tremendous success in the field of Natural Language Processing (NLP). Prior studies have primarily focused on general and generic domains, with relatively less research on specialized LLMs in the medical field. The specialization and high accuracy requirements for diagnosis in the medical field, as well as the challenges in collecting large-scale data, have constrained the application and development of LLMs in medical scenarios. In the field of ophthalmology, clinical diagnosis mainly relies on doctors' interpretation of reports and making diagnostic decisions. In order to take advantage of LLMs to provide decision support for doctors, we collected three modalities of ophthalmic report data and fine-tuned the LLaMA2 model, successfully constructing an LLM termed the "Ophtha-LLaMA2" specifically tailored for ophthalmic disease diagnosis. Inference test results show that even with a smaller fine-tuning dataset, Ophtha-LLaMA2 performs significantly better in ophthalmic diagnosis compared to other LLMs. It demonstrates that the Ophtha-LLaMA2 exhibits satisfying accuracy and efficiency in ophthalmic disease diagnosis, making it a valuable tool for ophthalmologists to provide improved diagnostic support for patients. This research provides a useful reference for the application of LLMs in the field of ophthalmology, while showcasing the immense potential and prospects in this domain.
Instruction-ViT: Multi-Modal Prompts for Instruction Learning in ViT
Apr 29, 2023Prompts have been proven to play a crucial role in large language models, and in recent years, vision models have also been using prompts to improve scalability for multiple downstream tasks. In this paper, we focus on adapting prompt design based on instruction tuning into a visual transformer model for image classification which we called Instruction-ViT. The key idea is to implement multi-modal prompts (text or image prompt) related to category information to guide the fine-tuning of the model. Based on the experiments of several image captionining tasks, the performance and domain adaptability were improved. Our work provided an innovative strategy to fuse multi-modal prompts with better performance and faster adaptability for visual classification models.
ChatABL: Abductive Learning via Natural Language Interaction with ChatGPT
Apr 21, 2023Large language models (LLMs) such as ChatGPT have recently demonstrated significant potential in mathematical abilities, providing valuable reasoning paradigm consistent with human natural language. However, LLMs currently have difficulty in bridging perception, language understanding and reasoning capabilities due to incompatibility of the underlying information flow among them, making it challenging to accomplish tasks autonomously. On the other hand, abductive learning (ABL) frameworks for integrating the two abilities of perception and reasoning has seen significant success in inverse decipherment of incomplete facts, but it is limited by the lack of semantic understanding of logical reasoning rules and the dependence on complicated domain knowledge representation. This paper presents a novel method (ChatABL) for integrating LLMs into the ABL framework, aiming at unifying the three abilities in a more user-friendly and understandable manner. The proposed method uses the strengths of LLMs' understanding and logical reasoning to correct the incomplete logical facts for optimizing the performance of perceptual module, by summarizing and reorganizing reasoning rules represented in natural language format. Similarly, perceptual module provides necessary reasoning examples for LLMs in natural language format. The variable-length handwritten equation deciphering task, an abstract expression of the Mayan calendar decoding, is used as a testbed to demonstrate that ChatABL has reasoning ability beyond most existing state-of-the-art methods, which has been well supported by comparative studies. To our best knowledge, the proposed ChatABL is the first attempt to explore a new pattern for further approaching human-level cognitive ability via natural language interaction with ChatGPT.
Deep Image Prior for Sparse-sampling Photoacoustic Microscopy
Oct 15, 2020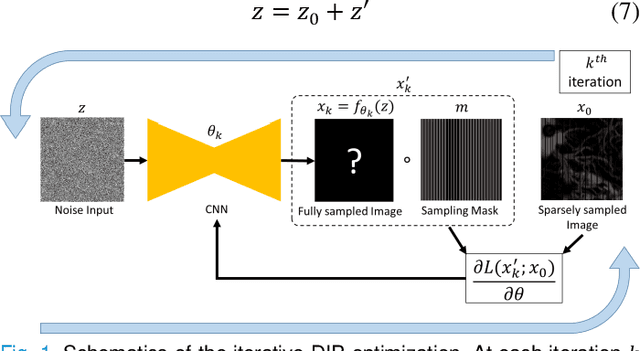
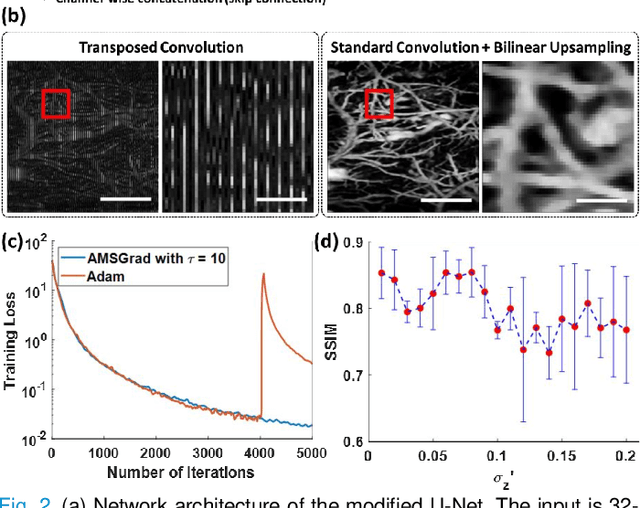
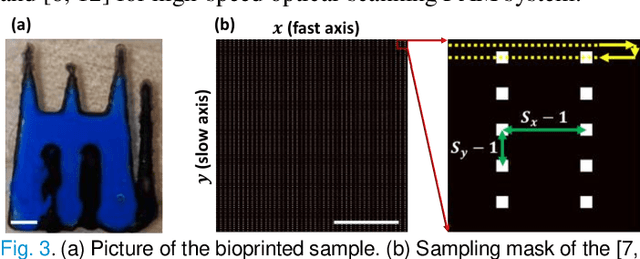
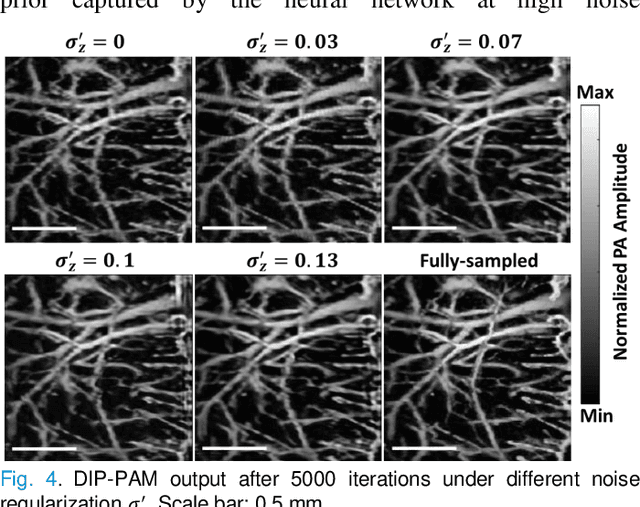
Photoacoustic microscopy (PAM) is an emerging method for imaging both structural and functional information without the need for exogenous contrast agents. However, state-of-the-art PAM faces a tradeoff between imaging speed and spatial sampling density within the same field-of-view (FOV). Limited by the pulsed laser's repetition rate, the imaging speed is inversely proportional to the total number of effective pixels. To cover the same FOV in a shorter amount of time with the same PAM hardware, there is currently no other option than to decrease spatial sampling density (i.e., sparse sampling). Deep learning methods have recently been used to improve sparsely sampled PAM images; however, these methods often require time-consuming pre-training and a large training dataset that has fully sampled, co-registered ground truth. In this paper, we propose using a method known as "deep image prior" to improve the image quality of sparsely sampled PAM images. The network does not need prior learning or fully sampled ground truth, making its implementation more flexible and much quicker. Our results show promising improvement in PA vasculature images with as few as 2% of the effective pixels. Our deep image prior approach produces results that outperform interpolation methods and can be readily translated to other high-speed, sparse-sampling imaging modalities.
Reconstructing undersampled photoacoustic microscopy images using deep learning
May 30, 2020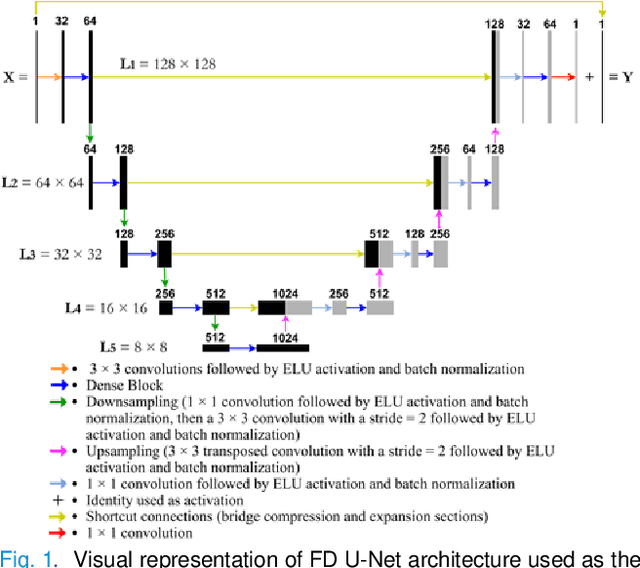
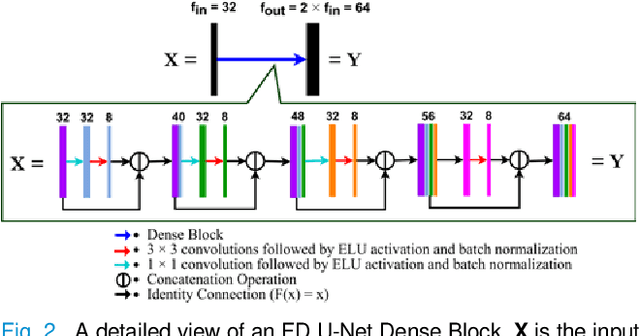
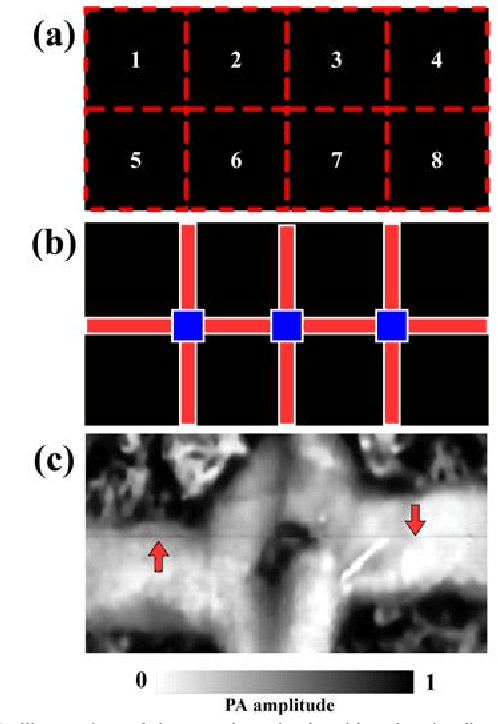
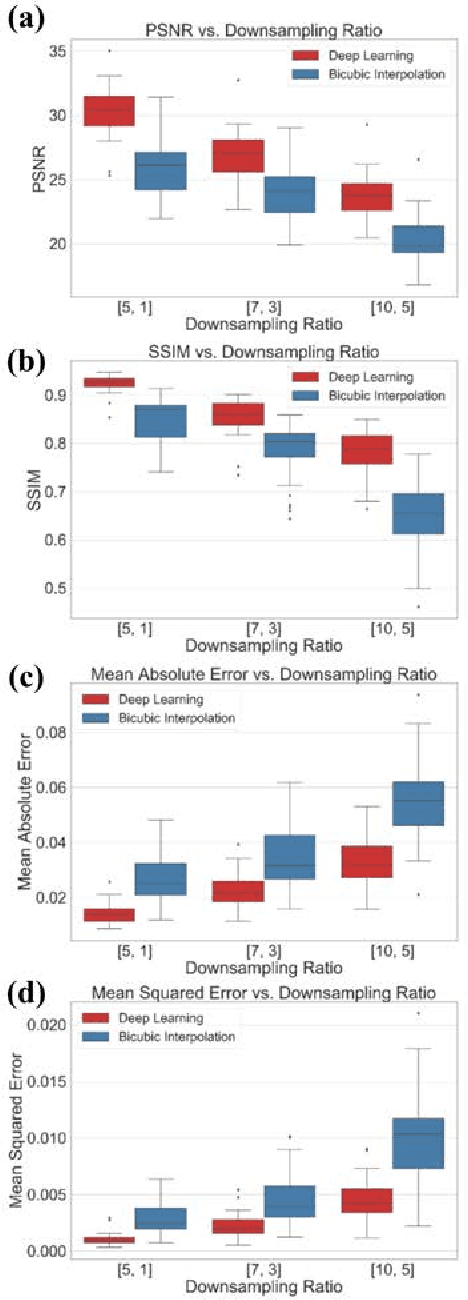
One primary technical challenge in photoacoustic microscopy (PAM) is the necessary compromise between spatial resolution and imaging speed. In this study, we propose a novel application of deep learning principles to reconstruct undersampled PAM images and transcend the trade-off between spatial resolution and imaging speed. We compared various convolutional neural network (CNN) architectures, and selected a fully dense U-net (FD U-net) model that produced the best results. To mimic various undersampling conditions in practice, we artificially downsampled fully-sampled PAM images of mouse brain vasculature at different ratios. This allowed us to not only definitively establish the ground truth, but also train and test our deep learning model at various imaging conditions. Our results and numerical analysis have collectively demonstrated the robust performance of our model to reconstruct PAM images with as few as 2% of the original pixels, which may effectively shorten the imaging time without substantially sacrificing the image quality.