 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatRadio-Valuer: A Chat Large Language Model for Generalizable Radiology Report Generation Based on Multi-institution and Multi-system Data
Oct 10, 2023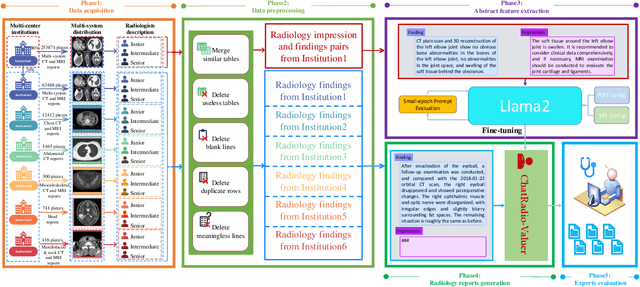
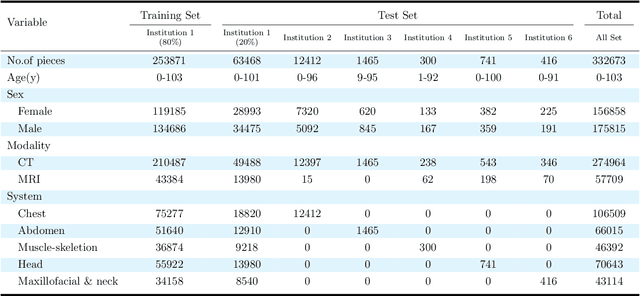
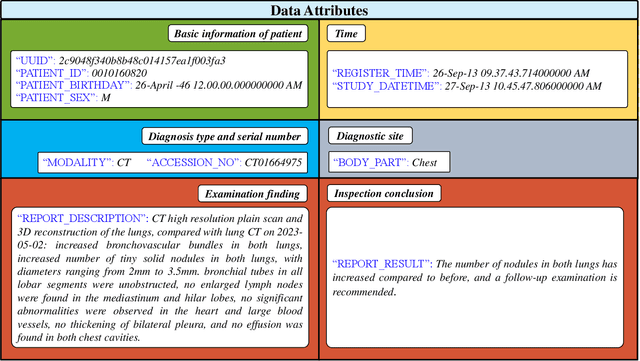
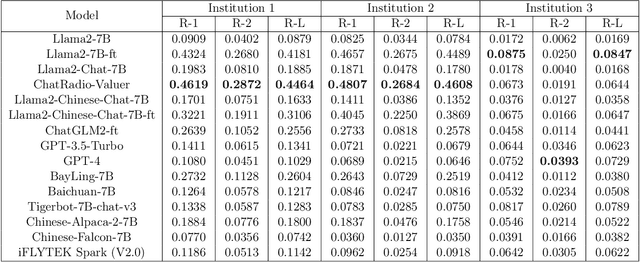
Radiology report generation, as a key step in medical image analysis, is critical to the quantitative analysis of clinically informed decision-making levels. However, complex and diverse radiology reports with cross-source heterogeneity pose a huge generalizability challenge to the current methods under massive data volume, mainly because the style and normativity of radiology reports are obviously distinctive among institutions, body regions inspected and radiologists. Recently, the advent of large language models (LLM) offers great potential for recognizing signs of health conditions. To resolve the above problem, we collaborate with the Second Xiangya Hospital in China and propose ChatRadio-Valuer based on the LLM, a tailored model for automatic radiology report generation that learns generalizable representations and provides a basis pattern for model adaptation in sophisticated analysts' cases. Specifically, ChatRadio-Valuer is trained based on the radiology reports from a single institution by means of supervised fine-tuning, and then adapted to disease diagnosis tasks for human multi-system evaluation (i.e., chest, abdomen, muscle-skeleton, head, and maxillofacial $\&$ neck) from six different institutions in clinical-level events. The clinical dataset utilized in this study encompasses a remarkable total of \textbf{332,673} observations. From the comprehensive results on engineering indicators, clinical efficacy and deployment cost metrics, it can be shown that ChatRadio-Valuer consistently outperforms state-of-the-art models, especially ChatGPT (GPT-3.5-Turbo) and GPT-4 et al., in terms of the diseases diagnosis from radiology reports. ChatRadio-Valuer provides an effective avenue to boost model generalization performance and alleviate the annotation workload of experts to enable the promotion of clinical AI applications in radiology reports.
Chat2Brain: A Method for Mapping Open-Ended Semantic Queries to Brain Activation Maps
Sep 10, 2023Over decades, neuroscience has accumulated a wealth of research results in the text modality that can be used to explore cognitive processes. Meta-analysis is a typical method that successfully establishes a link from text queries to brain activation maps using these research results, but it still relies on an ideal query environment. In practical applications, text queries used for meta-analyses may encounter issues such as semantic redundancy and ambiguity, resulting in an inaccurate mapping to brain images. On the other hand, large language models (LLMs) like ChatGPT have shown great potential in tasks such as context understanding and reasoning, displaying a high degree of consistency with human natural language. Hence, LLMs could improve the connection between text modality and neuroscience, resolving existing challenges of meta-analyses. In this study, we propose a method called Chat2Brain that combines LLMs to basic text-2-image model, known as Text2Brain, to map open-ended semantic queries to brain activation maps in data-scarce and complex query environments. By utilizing the understanding and reasoning capabilities of LLMs, the performance of the mapping model is optimized by transferring text queries to semantic queries. We demonstrate that Chat2Brain can synthesize anatomically plausible neural activation patterns for more complex tasks of text queries.
Evaluating Large Language Models for Radiology Natural Language Processing
Jul 27, 2023
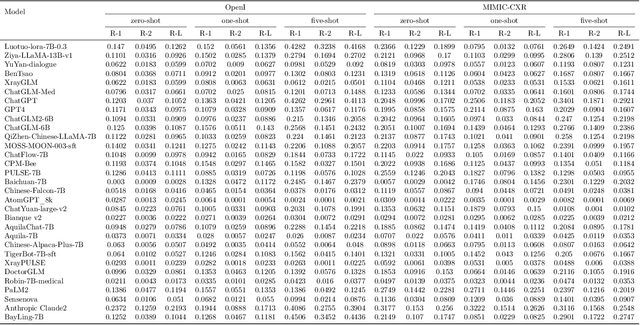
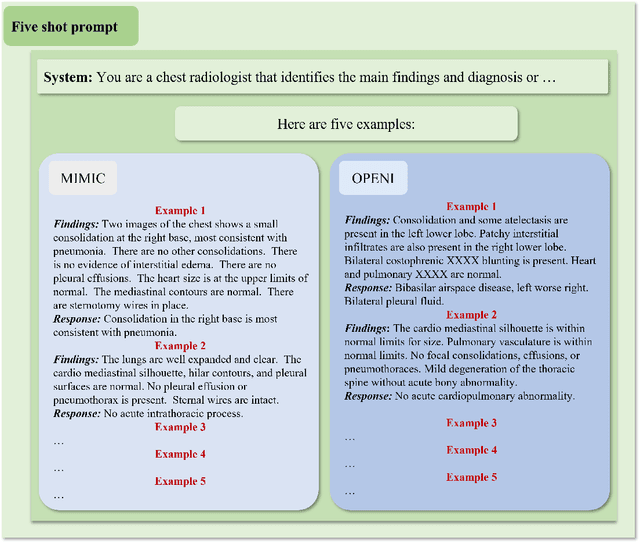
The rise of large language models (LLMs) has marked a pivotal shift in the field of natural language processing (NLP). LLMs have revolutionized a multitude of domains, and they have made a significant impact in the medical field. Large language models are now more abundant than ever, and many of these models exhibit bilingual capabilities, proficient in both English and Chinese. However, a comprehensive evaluation of these models remains to be conducted. This lack of assessment is especially apparent within the context of radiology NLP. This study seeks to bridge this gap by critically evaluating thirty two LLMs in interpreting radiology reports, a crucial component of radiology NLP. Specifically, the ability to derive impressions from radiologic findings is assessed. The outcomes of this evaluation provide key insights into the performance, strengths, and weaknesses of these LLMs, informing their practical applications within the medical domain.
ImpressionGPT: An Iterative Optimizing Framework for Radiology Report Summarization with ChatGPT
May 03, 2023The 'Impression' section of a radiology report is a critical basis for communication between radiologists and other physicians, and it is typically written by radiologists based on the 'Findings' section. However, writing numerous impressions can be laborious and error-prone for radiologists. Although recent studies have achieved promising results in automatic impression generation using large-scale medical text data for pre-training and fine-tuning pre-trained language models, such models often require substantial amounts of medical text data and have poor generalization performance. While large language models (LLMs) like ChatGPT have shown strong generalization capabilities and performance, their performance in specific domains, such as radiology, remains under-investigated and potentially limited. To address this limitation, we propose ImpressionGPT, which leverages the in-context learning capability of LLMs by constructing dynamic contexts using domain-specific, individualized data. This dynamic prompt approach enables the model to learn contextual knowledge from semantically similar examples from existing data. Additionally, we design an iterative optimization algorithm that performs automatic evaluation on the generated impression results and composes the corresponding instruction prompts to further optimize the model. The proposed ImpressionGPT model achieves state-of-the-art performance on both MIMIC-CXR and OpenI datasets without requiring additional training data or fine-tuning the LLMs. This work presents a paradigm for localizing LLMs that can be applied in a wide range of similar application scenarios, bridging the gap between general-purpose LLMs and the specific language processing needs of various domains.
ChatABL: Abductive Learning via Natural Language Interaction with ChatGPT
Apr 21, 2023Large language models (LLMs) such as ChatGPT have recently demonstrated significant potential in mathematical abilities, providing valuable reasoning paradigm consistent with human natural language. However, LLMs currently have difficulty in bridging perception, language understanding and reasoning capabilities due to incompatibility of the underlying information flow among them, making it challenging to accomplish tasks autonomously. On the other hand, abductive learning (ABL) frameworks for integrating the two abilities of perception and reasoning has seen significant success in inverse decipherment of incomplete facts, but it is limited by the lack of semantic understanding of logical reasoning rules and the dependence on complicated domain knowledge representation. This paper presents a novel method (ChatABL) for integrating LLMs into the ABL framework, aiming at unifying the three abilities in a more user-friendly and understandable manner. The proposed method uses the strengths of LLMs' understanding and logical reasoning to correct the incomplete logical facts for optimizing the performance of perceptual module, by summarizing and reorganizing reasoning rules represented in natural language format. Similarly, perceptual module provides necessary reasoning examples for LLMs in natural language format. The variable-length handwritten equation deciphering task, an abstract expression of the Mayan calendar decoding, is used as a testbed to demonstrate that ChatABL has reasoning ability beyond most existing state-of-the-art methods, which has been well supported by comparative studies. To our best knowledge, the proposed ChatABL is the first attempt to explore a new pattern for further approaching human-level cognitive ability via natural language interaction with ChatGPT.