 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
Jan 18, 2026Deep Research Agents (DRAs) generate citation-rich reports via multi-step search and synthesis, yet existing benchmarks mainly target text-only settings or short-form multimodal QA, missing end-to-end multimodal evidence use. We introduce MMDeepResearch-Bench (MMDR-Bench), a benchmark of 140 expert-crafted tasks across 21 domains, where each task provides an image-text bundle to evaluate multimodal understanding and citation-grounded report generation. Compared to prior setups, MMDR-Bench emphasizes report-style synthesis with explicit evidence use, where models must connect visual artifacts to sourced claims and maintain consistency across narrative, citations, and visual references. We further propose a unified, interpretable evaluation pipeline: Formula-LLM Adaptive Evaluation (FLAE) for report quality, Trustworthy Retrieval-Aligned Citation Evaluation (TRACE) for citation-grounded evidence alignment, and Multimodal Support-Aligned Integrity Check (MOSAIC) for text-visual integrity, each producing fine-grained signals that support error diagnosis beyond a single overall score. Experiments across 25 state-of-the-art models reveal systematic trade-offs between generation quality, citation discipline, and multimodal grounding, highlighting that strong prose alone does not guarantee faithful evidence use and that multimodal integrity remains a key bottleneck for deep research agents.
Efficient Edge LLMs Deployment via HessianAware Quantization and CPU GPU Collaborative
Aug 10, 2025With the breakthrough progress of large language models (LLMs) in natural language processing and multimodal tasks, efficiently deploying them on resource-constrained edge devices has become a critical challenge. The Mixture of Experts (MoE) architecture enhances model capacity through sparse activation, but faces two major difficulties in practical deployment: (1) The presence of numerous outliers in activation distributions leads to severe degradation in quantization accuracy for both activations and weights, significantly impairing inference performance; (2) Under limited memory, efficient offloading and collaborative inference of expert modules struggle to balance latency and throughput. To address these issues, this paper proposes an efficient MoE edge deployment scheme based on Hessian-Aware Quantization (HAQ) and CPU-GPU collaborative inference. First, by introducing smoothed Hessian matrix quantization, we achieve joint 8-bit quantization of activations and weights, which significantly alleviates the accuracy loss caused by outliers while ensuring efficient implementation on mainstream hardware. Second, we design an expert-level collaborative offloading and inference mechanism, which, combined with expert activation path statistics, enables efficient deployment and scheduling of expert modules between CPU and GPU, greatly reducing memory footprint and inference latency. Extensive experiments validate the effectiveness of our method on mainstream large models such as the OPT series and Mixtral 8*7B: on datasets like Wikitext2 and C4, the inference accuracy of the low-bit quantized model approaches that of the full-precision model, while GPU memory usage is reduced by about 60%, and inference latency is significantly improved.
FedPaI: Achieving Extreme Sparsity in Federated Learning via Pruning at Initialization
Apr 01, 2025Federated Learning (FL) enables distributed training on edge devices but faces significant challenges due to resource constraints in edge environments, impacting both communication and computational efficiency. Existing iterative pruning techniques improve communication efficiency but are limited by their centralized design, which struggles with FL's decentralized and data-imbalanced nature, resulting in suboptimal sparsity levels. To address these issues, we propose FedPaI, a novel efficient FL framework that leverages Pruning at Initialization (PaI) to achieve extreme sparsity. FedPaI identifies optimal sparse connections at an early stage, maximizing model capacity and significantly reducing communication and computation overhead by fixing sparsity patterns at the start of training. To adapt to diverse hardware and software environments, FedPaI supports both structured and unstructured pruning. Additionally, we introduce personalized client-side pruning mechanisms for improved learning capacity and sparsity-aware server-side aggregation for enhanced efficiency. Experimental results demonstrate that FedPaI consistently outperforms existing efficient FL that applies conventional iterative pruning with significant leading in efficiency and model accuracy. For the first time, our proposed FedPaI achieves an extreme sparsity level of up to 98% without compromising the model accuracy compared to unpruned baselines, even under challenging non-IID settings. By employing our FedPaI with joint optimization of model learning capacity and sparsity, FL applications can benefit from faster convergence and accelerate the training by 6.4 to 7.9 times.
Enabling Weak Client Participation via On-device Knowledge Distillation in Heterogenous Federated Learning
Mar 14, 2025Online Knowledge Distillation (KD) is recently highlighted to train large models in Federated Learning (FL) environments. Many existing studies adopt the logit ensemble method to perform KD on the server side. However, they often assume that unlabeled data collected at the edge is centralized on the server. Moreover, the logit ensemble method personalizes local models, which can degrade the quality of soft targets, especially when data is highly non-IID. To address these critical limitations,we propose a novel on-device KD-based heterogeneous FL method. Our approach leverages a small auxiliary model to learn from labeled local data. Subsequently, a subset of clients with strong system resources transfers knowledge to a large model through on-device KD using their unlabeled data. Our extensive experiments demonstrate that our on-device KD-based heterogeneous FL method effectively utilizes the system resources of all edge devices as well as the unlabeled data, resulting in higher accuracy compared to SOTA KD-based FL methods.
Experience-replay Innovative Dynamics
Jan 21, 2025



Despite its groundbreaking success, multi-agent reinforcement learning (MARL) still suffers from instability and nonstationarity. Replicator dynamics, the most well-known model from evolutionary game theory (EGT), provide a theoretical framework for the convergence of the trajectories to Nash equilibria and, as a result, have been used to ensure formal guarantees for MARL algorithms in stable game settings. However, they exhibit the opposite behavior in other settings, which poses the problem of finding alternatives to ensure convergence. In contrast, innovative dynamics, such as the Brown-von Neumann-Nash (BNN) or Smith, result in periodic trajectories with the potential to approximate Nash equilibria. Yet, no MARL algorithms based on these dynamics have been proposed. In response to this challenge, we develop a novel experience replay-based MARL algorithm that incorporates revision protocols as tunable hyperparameters. We demonstrate, by appropriately adjusting the revision protocols, that the behavior of our algorithm mirrors the trajectories resulting from these dynamics. Importantly, our contribution provides a framework capable of extending the theoretical guarantees of MARL algorithms beyond replicator dynamics. Finally, we corroborate our theoretical findings with empirical results.
Towards Next-Generation Medical Agent: How o1 is Reshaping Decision-Making in Medical Scenarios
Nov 16, 2024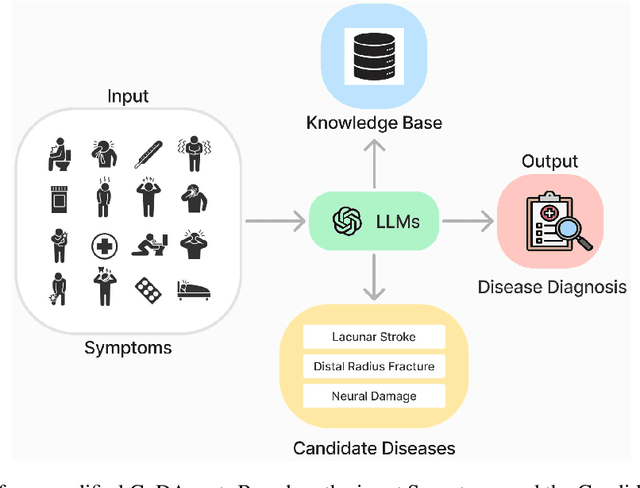


Artificial Intelligence (AI) has become essential in modern healthcare, with large language models (LLMs) offering promising advances in clinical decision-making. Traditional model-based approaches, including those leveraging in-context demonstrations and those with specialized medical fine-tuning, have demonstrated strong performance in medical language processing but struggle with real-time adaptability, multi-step reasoning, and handling complex medical tasks. Agent-based AI systems address these limitations by incorporating reasoning traces, tool selection based on context, knowledge retrieval, and both short- and long-term memory. These additional features enable the medical AI agent to handle complex medical scenarios where decision-making should be built on real-time interaction with the environment. Therefore, unlike conventional model-based approaches that treat medical queries as isolated questions, medical AI agents approach them as complex tasks and behave more like human doctors. In this paper, we study the choice of the backbone LLM for medical AI agents, which is the foundation for the agent's overall reasoning and action generation. In particular, we consider the emergent o1 model and examine its impact on agents' reasoning, tool-use adaptability, and real-time information retrieval across diverse clinical scenarios, including high-stakes settings such as intensive care units (ICUs). Our findings demonstrate o1's ability to enhance diagnostic accuracy and consistency, paving the way for smarter, more responsive AI tools that support better patient outcomes and decision-making efficacy in clinical practice.
Legal Evalutions and Challenges of Large Language Models
Nov 15, 2024



In this paper, we review legal testing methods based on Large Language Models (LLMs), using the OPENAI o1 model as a case study to evaluate the performance of large models in applying legal provisions. We compare current state-of-the-art LLMs, including open-source, closed-source, and legal-specific models trained specifically for the legal domain. Systematic tests are conducted on English and Chinese legal cases, and the results are analyzed in depth. Through systematic testing of legal cases from common law systems and China, this paper explores the strengths and weaknesses of LLMs in understanding and applying legal texts, reasoning through legal issues, and predicting judgments. The experimental results highlight both the potential and limitations of LLMs in legal applications, particularly in terms of challenges related to the interpretation of legal language and the accuracy of legal reasoning. Finally, the paper provides a comprehensive analysis of the advantages and disadvantages of various types of models, offering valuable insights and references for the future application of AI in the legal field.
3D-CT-GPT: Generating 3D Radiology Reports through Integration of Large Vision-Language Models
Sep 28, 2024



Medical image analysis is crucial in modern radiological diagnostics, especially given the exponential growth in medical imaging data. The demand for automated report generation systems has become increasingly urgent. While prior research has mainly focused on using machine learning and multimodal language models for 2D medical images, the generation of reports for 3D medical images has been less explored due to data scarcity and computational complexities. This paper introduces 3D-CT-GPT, a Visual Question Answering (VQA)-based medical visual language model specifically designed for generating radiology reports from 3D CT scans, particularly chest CTs. Extensive experiments on both public and private datasets demonstrate that 3D-CT-GPT significantly outperforms existing methods in terms of report accuracy and quality. Although current methods are few, including the partially open-source CT2Rep and the open-source M3D, we ensured fair comparison through appropriate data conversion and evaluation methodologies. Experimental results indicate that 3D-CT-GPT enhances diagnostic accuracy and report coherence, establishing itself as a robust solution for clinical radiology report generation. Future work will focus on expanding the dataset and further optimizing the model to enhance its performance and applicability.
HARP: Human-Assisted Regrouping with Permutation Invariant Critic for Multi-Agent Reinforcement Learning
Sep 18, 2024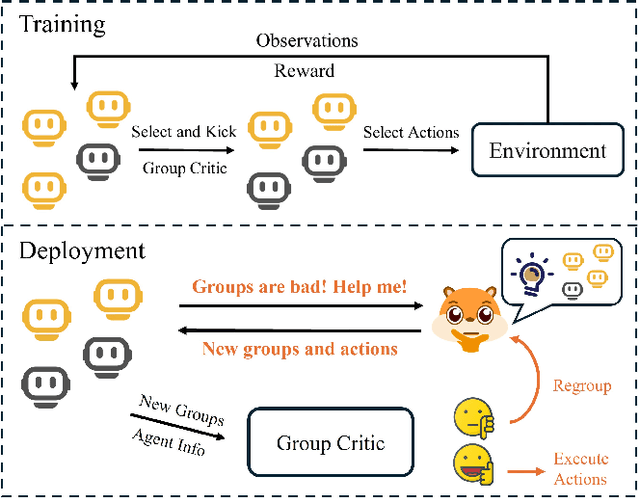
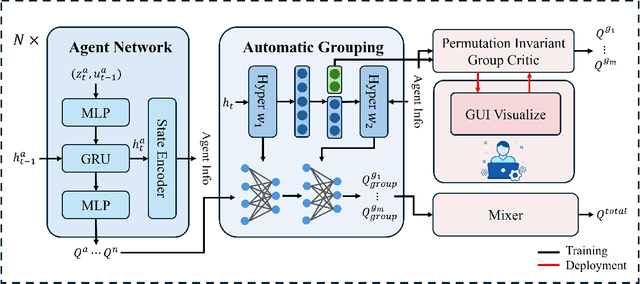
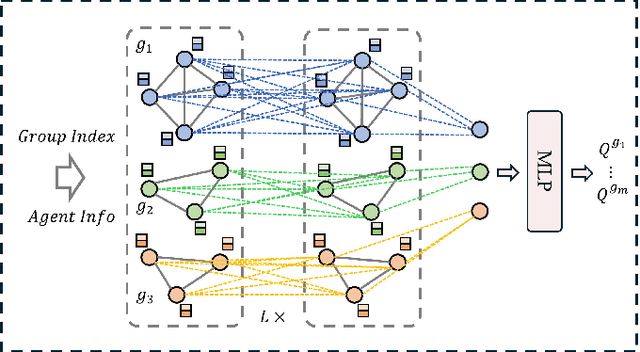

Human-in-the-loop reinforcement learning integrates human expertise to accelerate agent learning and provide critical guidance and feedback in complex fields. However, many existing approaches focus on single-agent tasks and require continuous human involvement during the training process, significantly increasing the human workload and limiting scalability. In this paper, we propose HARP (Human-Assisted Regrouping with Permutation Invariant Critic), a multi-agent reinforcement learning framework designed for group-oriented tasks. HARP integrates automatic agent regrouping with strategic human assistance during deployment, enabling and allowing non-experts to offer effective guidance with minimal intervention. During training, agents dynamically adjust their groupings to optimize collaborative task completion. When deployed, they actively seek human assistance and utilize the Permutation Invariant Group Critic to evaluate and refine human-proposed groupings, allowing non-expert users to contribute valuable suggestions. In multiple collaboration scenarios, our approach is able to leverage limited guidance from non-experts and enhance performance. The project can be found at https://github.com/huawen-hu/HARP.
Identifying Influential nodes in Brain Networks via Self-Supervised Graph-Transformer
Sep 17, 2024


Studying influential nodes (I-nodes) in brain networks is of great significance in the field of brain imaging. Most existing studies consider brain connectivity hubs as I-nodes. However, this approach relies heavily on prior knowledge from graph theory, which may overlook the intrinsic characteristics of the brain network, especially when its architecture is not fully understood. In contrast, self-supervised deep learning can learn meaningful representations directly from the data. This approach enables the exploration of I-nodes for brain networks, which is also lacking in current studies. This paper proposes a Self-Supervised Graph Reconstruction framework based on Graph-Transformer (SSGR-GT) to identify I-nodes, which has three main characteristics. First, as a self-supervised model, SSGR-GT extracts the importance of brain nodes to the reconstruction. Second, SSGR-GT uses Graph-Transformer, which is well-suited for extracting features from brain graphs, combining both local and global characteristics. Third, multimodal analysis of I-nodes uses graph-based fusion technology, combining functional and structural brain information. The I-nodes we obtained are distributed in critical areas such as the superior frontal lobe, lateral parietal lobe, and lateral occipital lobe, with a total of 56 identified across different experiments. These I-nodes are involved in more brain networks than other regions, have longer fiber connections, and occupy more central positions in structural connectivity. They also exhibit strong connectivity and high node efficiency in both functional and structural networks. Furthermore, there is a significant overlap between the I-nodes and both the structural and functional rich-club. These findings enhance our understanding of the I-nodes within the brain network, and provide new insights for future research in further understanding the brain working mechanisms.