 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiased Local SGD for Efficient Deep Learning on Heterogeneous Systems
Aug 12, 2025Most large-scale neural network training methods assume homogeneous parallel computing resources. For example, synchronous SGD with data parallelism, the most widely used parallel training strategy, incurs significant synchronization overhead when workers process their assigned data at different speeds. Consequently, in systems with heterogeneous compute resources, users often rely solely on the fastest components, such as GPUs, for training. In this work, we explore how to effectively use heterogeneous resources for neural network training. We propose a system-aware local stochastic gradient descent (local SGD) method that allocates workloads to each compute resource in proportion to its compute capacity. To make better use of slower resources such as CPUs, we intentionally introduce bias into data sampling and model aggregation. Our study shows that well-controlled bias can significantly accelerate local SGD in heterogeneous environments, achieving comparable or even higher accuracy than synchronous SGD with data-parallelism within the same time budget. This fundamental parallelization strategy can be readily extended to diverse heterogeneous environments, including cloud platforms and multi-node high-performance computing clusters.
Enabling Weak Client Participation via On-device Knowledge Distillation in Heterogenous Federated Learning
Mar 14, 2025Online Knowledge Distillation (KD) is recently highlighted to train large models in Federated Learning (FL) environments. Many existing studies adopt the logit ensemble method to perform KD on the server side. However, they often assume that unlabeled data collected at the edge is centralized on the server. Moreover, the logit ensemble method personalizes local models, which can degrade the quality of soft targets, especially when data is highly non-IID. To address these critical limitations,we propose a novel on-device KD-based heterogeneous FL method. Our approach leverages a small auxiliary model to learn from labeled local data. Subsequently, a subset of clients with strong system resources transfers knowledge to a large model through on-device KD using their unlabeled data. Our extensive experiments demonstrate that our on-device KD-based heterogeneous FL method effectively utilizes the system resources of all edge devices as well as the unlabeled data, resulting in higher accuracy compared to SOTA KD-based FL methods.
Asynchronous Sharpness-Aware Minimization For Fast and Accurate Deep Learning
Mar 14, 2025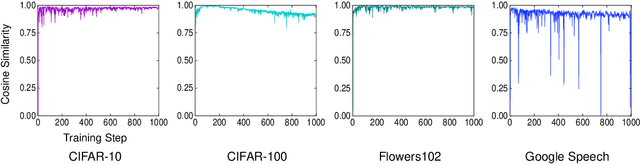
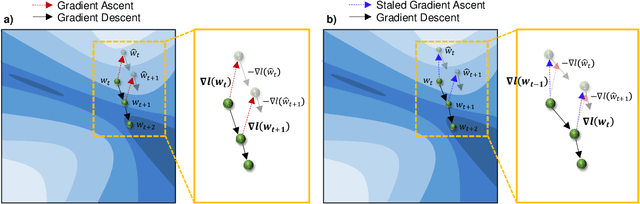
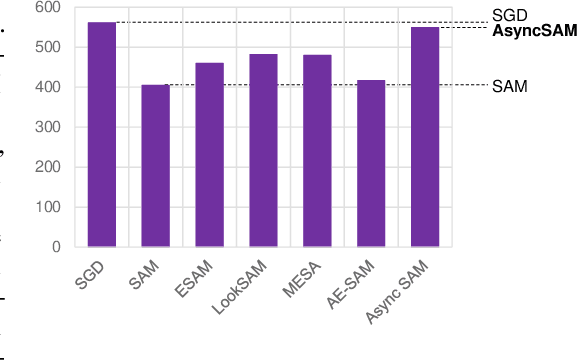
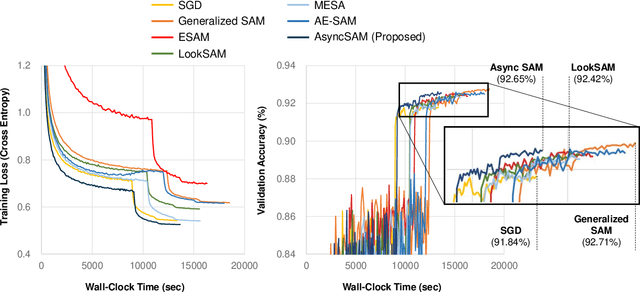
Sharpness-Aware Minimization (SAM) is an optimization method that improves generalization performance of machine learning models. Despite its superior generalization, SAM has not been actively used in real-world applications due to its expensive computational cost. In this work, we propose a novel asynchronous-parallel SAM which achieves nearly the same gradient norm penalizing effect like the original SAM while breaking the data dependency between the model perturbation and the model update. The proposed asynchronous SAM can even entirely hide the model perturbation time by adjusting the batch size for the model perturbation in a system-aware manner. Thus, the proposed method enables to fully utilize heterogeneous system resources such as CPUs and GPUs. Our extensive experiments well demonstrate the practical benefits of the proposed asynchronous approach. E.g., the asynchronous SAM achieves comparable Vision Transformer fine-tuning accuracy (CIFAR-100) as the original SAM while having almost the same training time as SGD.