 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Sharpness-Aware Minimization For Fast and Accurate Deep Learning
Paper and Code
Mar 14, 2025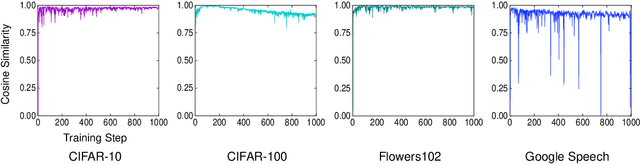
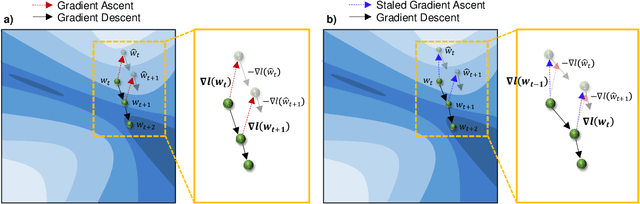
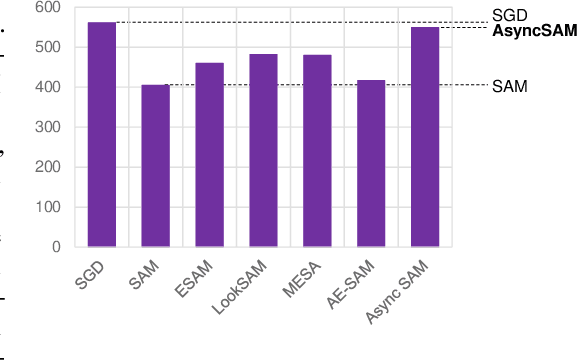
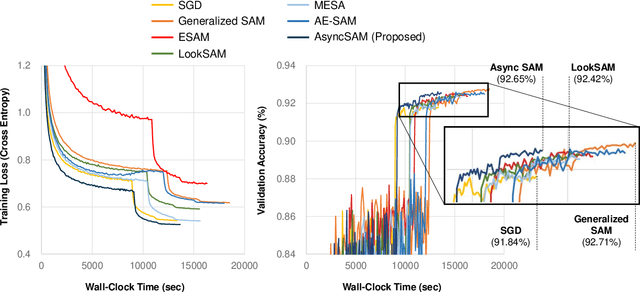
Sharpness-Aware Minimization (SAM) is an optimization method that improves generalization performance of machine learning models. Despite its superior generalization, SAM has not been actively used in real-world applications due to its expensive computational cost. In this work, we propose a novel asynchronous-parallel SAM which achieves nearly the same gradient norm penalizing effect like the original SAM while breaking the data dependency between the model perturbation and the model update. The proposed asynchronous SAM can even entirely hide the model perturbation time by adjusting the batch size for the model perturbation in a system-aware manner. Thus, the proposed method enables to fully utilize heterogeneous system resources such as CPUs and GPUs. Our extensive experiments well demonstrate the practical benefits of the proposed asynchronous approach. E.g., the asynchronous SAM achieves comparable Vision Transformer fine-tuning accuracy (CIFAR-100) as the original SAM while having almost the same training time as SGD.