 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaping Zero-Shot Coordination via State Blocking
May 12, 2026Zero-shot coordination (ZSC) aims to enable agents to cooperate with independently trained partners without prior interaction, a key requirement for real-world multi-agent systems and human-AI collaboration. Existing approaches have largely emphasized increasing partner diversity during training, yet such strategies often fall short of achieving reliable generalization to unseen partners. We introduce State-Blocked Coordination (SBC), a simple yet effective framework that improves ZSC by inducing diverse interaction scenarios without direct environment modification. Specifically, SBC generates a family of virtual environments through state blocking, allowing agents to experience a wide range of suboptimal partner policies. Across multiple benchmarks, SBC demonstrates superior performance in zero-shot coordination, including strong generalization to human partners.
Retaining Suboptimal Actions to Follow Shifting Optima in Multi-Agent Reinforcement Learning
Feb 19, 2026Value decomposition is a core approach for cooperative multi-agent reinforcement learning (MARL). However, existing methods still rely on a single optimal action and struggle to adapt when the underlying value function shifts during training, often converging to suboptimal policies. To address this limitation, we propose Successive Sub-value Q-learning (S2Q), which learns multiple sub-value functions to retain alternative high-value actions. Incorporating these sub-value functions into a Softmax-based behavior policy, S2Q encourages persistent exploration and enables $Q^{\text{tot}}$ to adjust quickly to the changing optima. Experiments on challenging MARL benchmarks confirm that S2Q consistently outperforms various MARL algorithms, demonstrating improved adaptability and overall performance. Our code is available at https://github.com/hyeon1996/S2Q.
Clutt3R-Seg: Sparse-view 3D Instance Segmentation for Language-grounded Grasping in Cluttered Scenes
Feb 12, 2026Reliable 3D instance segmentation is fundamental to language-grounded robotic manipulation. Its critical application lies in cluttered environments, where occlusions, limited viewpoints, and noisy masks degrade perception. To address these challenges, we present Clutt3R-Seg, a zero-shot pipeline for robust 3D instance segmentation for language-grounded grasping in cluttered scenes. Our key idea is to introduce a hierarchical instance tree of semantic cues. Unlike prior approaches that attempt to refine noisy masks, our method leverages them as informative cues: through cross-view grouping and conditional substitution, the tree suppresses over- and under-segmentation, yielding view-consistent masks and robust 3D instances. Each instance is enriched with open-vocabulary semantic embeddings, enabling accurate target selection from natural language instructions. To handle scene changes during multi-stage tasks, we further introduce a consistency-aware update that preserves instance correspondences from only a single post-interaction image, allowing efficient adaptation without rescanning. Clutt3R-Seg is evaluated on both synthetic and real-world datasets, and validated on a real robot. Across all settings, it consistently outperforms state-of-the-art baselines in cluttered and sparse-view scenarios. Even on the most challenging heavy-clutter sequences, Clutt3R-Seg achieves an AP@25 of 61.66, over 2.2x higher than baselines, and with only four input views it surpasses MaskClustering with eight views by more than 2x. The code is available at: https://github.com/jeonghonoh/clutt3r-seg.
A.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Weight Variance Amplifier Improves Accuracy in High-Sparsity One-Shot Pruning
Nov 18, 2025



Deep neural networks achieve outstanding performance in visual recognition tasks, yet their large number of parameters makes them less practical for real-world applications. Recently, one-shot pruning has emerged as an effective strategy for reducing model size without additional training. However, models trained with standard objective functions often suffer a significant drop in accuracy after aggressive pruning. Some existing pruning-robust optimizers, such as SAM, and CrAM, mitigate this accuracy drop by guiding the model toward flatter regions of the parameter space, but they inevitably incur non-negligible additional computations. We propose a Variance Amplifying Regularizer (VAR) that deliberately increases the variance of model parameters during training. Our study reveals an intriguing finding that parameters with higher variance exhibit greater pruning robustness. VAR exploits this property by promoting such variance in the weight distribution, thereby mitigating the adverse effects of pruning. We further provide a theoretical analysis of its convergence behavior, supported by extensive empirical results demonstrating the superior pruning robustness of VAR.
Dynamic Rank Adjustment for Accurate and Efficient Neural Network Training
Aug 13, 2025Low-rank training methods reduce the number of trainable parameters by re-parameterizing the weights with matrix decompositions (e.g., singular value decomposition). However, enforcing a fixed low-rank structure caps the rank of the weight matrices and can hinder the model's ability to learn complex patterns. Furthermore, the effective rank of the model's weights tends to decline during training, and this drop is accelerated when the model is reparameterized into a low-rank structure. In this study, we argue that strategically interleaving full-rank training epochs within low-rank training epochs can effectively restore the rank of the model's weights. Based on our findings, we propose a general dynamic-rank training framework that is readily applicable to a wide range of neural-network tasks. We first describe how to adjust the rank of weight matrix to alleviate the inevitable rank collapse that arises during training, and then present extensive empirical results that validate our claims and demonstrate the efficacy of the proposed framework. Our empirical study shows that the proposed method achieves almost the same computational cost as SVD-based low-rank training while achieving a comparable accuracy to full-rank training across various benchmarks.
Biased Local SGD for Efficient Deep Learning on Heterogeneous Systems
Aug 12, 2025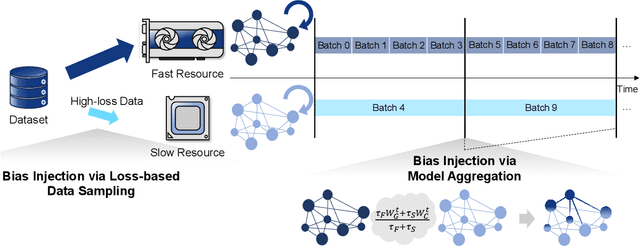
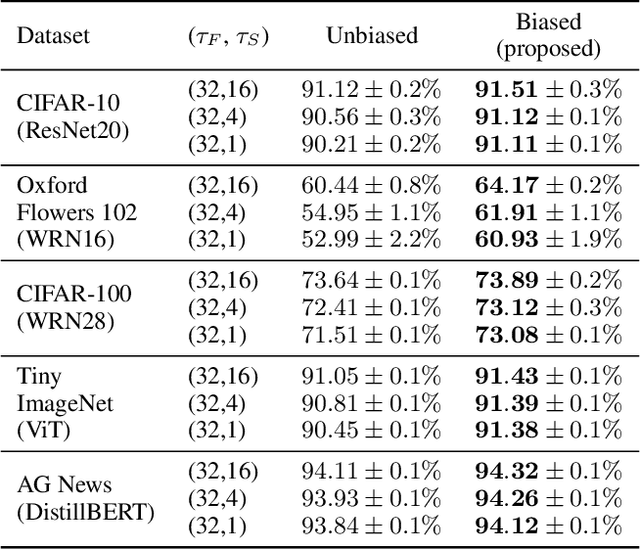
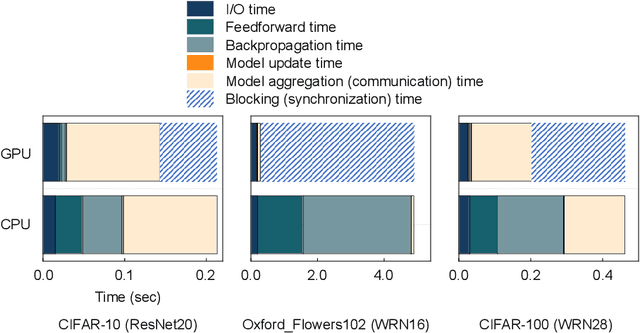
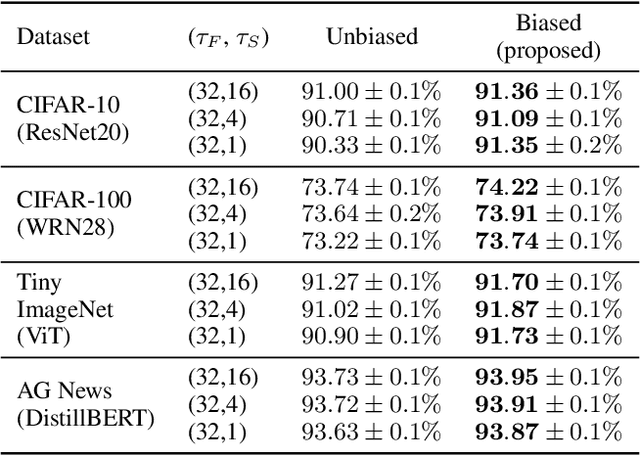
Most large-scale neural network training methods assume homogeneous parallel computing resources. For example, synchronous SGD with data parallelism, the most widely used parallel training strategy, incurs significant synchronization overhead when workers process their assigned data at different speeds. Consequently, in systems with heterogeneous compute resources, users often rely solely on the fastest components, such as GPUs, for training. In this work, we explore how to effectively use heterogeneous resources for neural network training. We propose a system-aware local stochastic gradient descent (local SGD) method that allocates workloads to each compute resource in proportion to its compute capacity. To make better use of slower resources such as CPUs, we intentionally introduce bias into data sampling and model aggregation. Our study shows that well-controlled bias can significantly accelerate local SGD in heterogeneous environments, achieving comparable or even higher accuracy than synchronous SGD with data-parallelism within the same time budget. This fundamental parallelization strategy can be readily extended to diverse heterogeneous environments, including cloud platforms and multi-node high-performance computing clusters.
Center of Gravity-Guided Focusing Influence Mechanism for Multi-Agent Reinforcement Learning
Jun 24, 2025



Cooperative multi-agent reinforcement learning (MARL) under sparse rewards presents a fundamental challenge due to limited exploration and insufficient coordinated attention among agents. In this work, we propose the Focusing Influence Mechanism (FIM), a novel framework that enhances cooperation by directing agent influence toward task-critical elements, referred to as Center of Gravity (CoG) state dimensions, inspired by Clausewitz's military theory. FIM consists of three core components: (1) identifying CoG state dimensions based on their stability under agent behavior, (2) designing counterfactual intrinsic rewards to promote meaningful influence on these dimensions, and (3) encouraging persistent and synchronized focus through eligibility-trace-based credit accumulation. These mechanisms enable agents to induce more targeted and effective state transitions, facilitating robust cooperation even in extremely sparse reward settings. Empirical evaluations across diverse MARL benchmarks demonstrate that the proposed FIM significantly improves cooperative performance compared to baselines.
Layer-wise Adaptive Gradient Norm Penalizing Method for Efficient and Accurate Deep Learning
Mar 18, 2025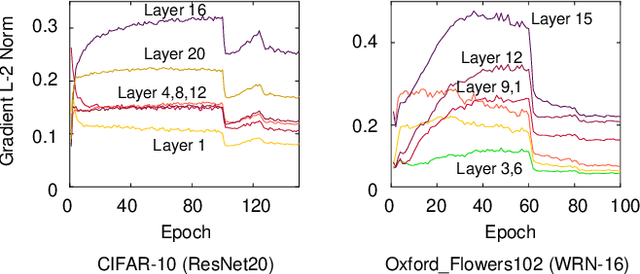

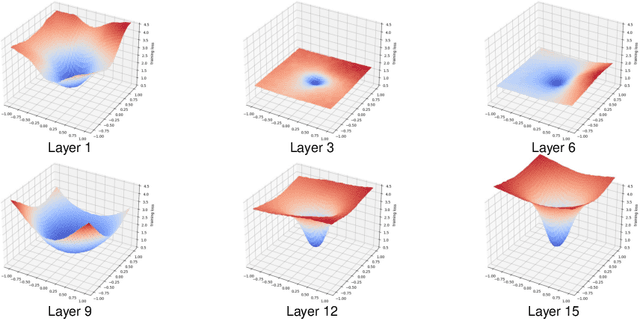

Sharpness-aware minimization (SAM) is known to improve the generalization performance of neural networks. However, it is not widely used in real-world applications yet due to its expensive model perturbation cost. A few variants of SAM have been proposed to tackle such an issue, but they commonly do not alleviate the cost noticeably. In this paper, we propose a lightweight layer-wise gradient norm penalizing method that tackles the expensive computational cost of SAM while maintaining its superior generalization performance. Our study empirically proves that the gradient norm of the whole model can be effectively suppressed by penalizing the gradient norm of only a few critical layers. We also theoretically show that such a partial model perturbation does not harm the convergence rate of SAM, allowing them to be safely adapted in real-world applications. To demonstrate the efficacy of the proposed method, we perform extensive experiments comparing the proposed method to mini-batch SGD and the conventional SAM using representative computer vision and language modeling benchmarks.
Layer-wise Update Aggregation with Recycling for Communication-Efficient Federated Learning
Mar 14, 2025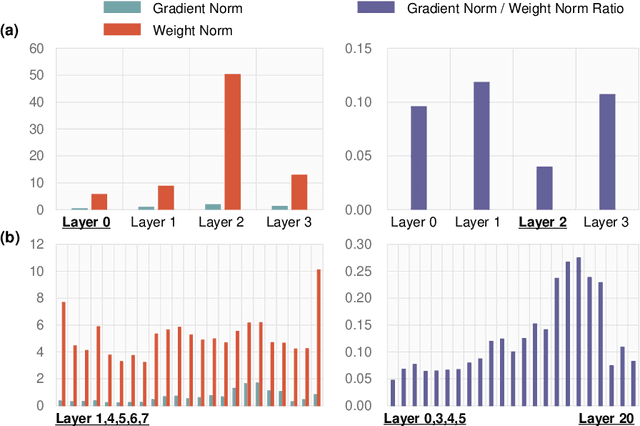

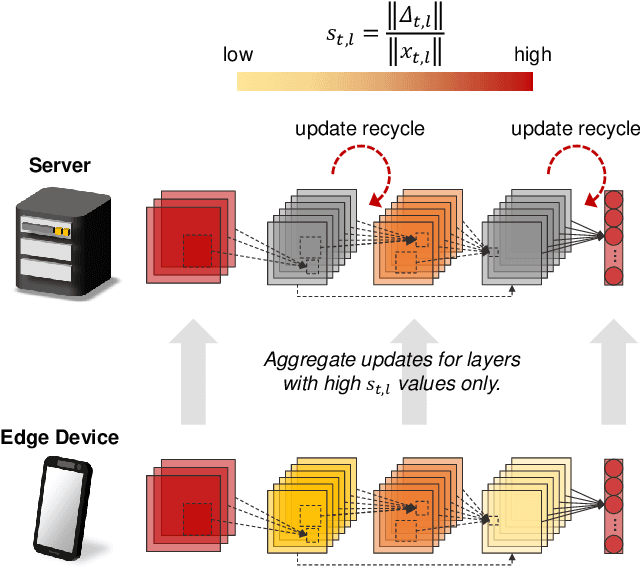
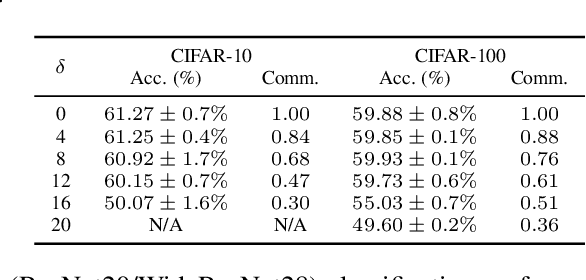
Expensive communication cost is a common performance bottleneck in Federated Learning (FL), which makes it less appealing in real-world applications. Many communication-efficient FL methods focus on discarding a part of model updates mostly based on gradient magnitude. In this study, we find that recycling previous updates, rather than simply dropping them, more effectively reduces the communication cost while maintaining FL performance. We propose FedLUAR, a Layer-wise Update Aggregation with Recycling scheme for communication-efficient FL. We first define a useful metric that quantifies the extent to which the aggregated gradients influences the model parameter values in each layer. FedLUAR selects a few layers based on the metric and recycles their previous updates on the server side. Our extensive empirical study demonstrates that the update recycling scheme significantly reduces the communication cost while maintaining model accuracy. For example, our method achieves nearly the same AG News accuracy as FedAvg, while reducing the communication cost to just 17%.