 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHair-Trigger Alignment: Black-Box Evaluation Cannot Guarantee Post-Update Alignment
Jan 29, 2026Large Language Models (LLMs) are rarely static and are frequently updated in practice. A growing body of alignment research has shown that models initially deemed "aligned" can exhibit misaligned behavior after fine-tuning, such as forgetting jailbreak safety features or re-surfacing knowledge that was intended to be forgotten. These works typically assume that the initial model is aligned based on static black-box evaluation, i.e., the absence of undesired responses to a fixed set of queries. In contrast, we formalize model alignment in both the static and post-update settings and uncover a fundamental limitation of black-box evaluation. We theoretically show that, due to overparameterization, static alignment provides no guarantee of post-update alignment for any update dataset. Moreover, we prove that static black-box probing cannot distinguish a model that is genuinely post-update robust from one that conceals an arbitrary amount of adversarial behavior which can be activated by even a single benign gradient update. We further validate these findings empirically in LLMs across three core alignment domains: privacy, jailbreak safety, and behavioral honesty. We demonstrate the existence of LLMs that pass all standard black-box alignment tests, yet become severely misaligned after a single benign update. Finally, we show that the capacity to hide such latent adversarial behavior increases with model scale, confirming our theoretical prediction that post-update misalignment grows with the number of parameters. Together, our results highlight the inadequacy of static evaluation protocols and emphasize the urgent need for post-update-robust alignment evaluation.
Clustering and Median Aggregation Improve Differentially Private Inference
Jun 05, 2025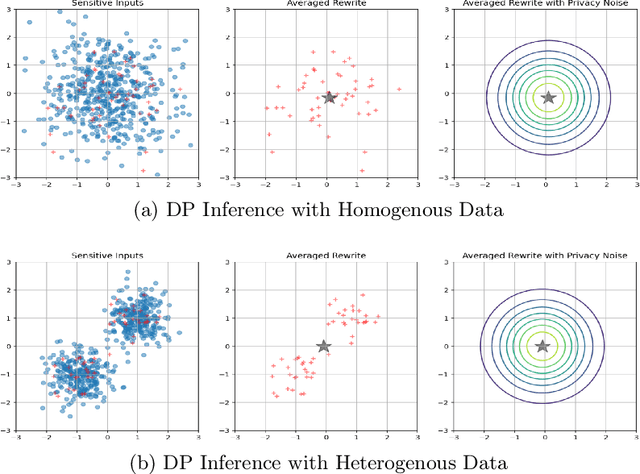

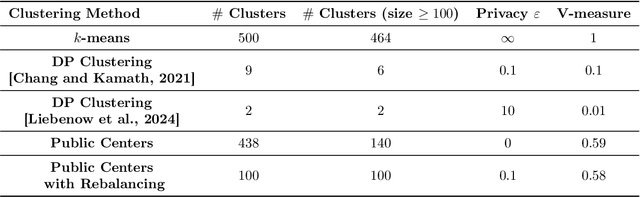
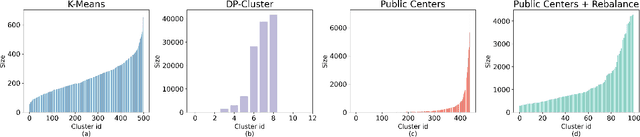
Differentially private (DP) language model inference is an approach for generating private synthetic text. A sensitive input example is used to prompt an off-the-shelf large language model (LLM) to produce a similar example. Multiple examples can be aggregated together to formally satisfy the DP guarantee. Prior work creates inference batches by sampling sensitive inputs uniformly at random. We show that uniform sampling degrades the quality of privately generated text, especially when the sensitive examples concern heterogeneous topics. We remedy this problem by clustering the input data before selecting inference batches. Next, we observe that clustering also leads to more similar next-token predictions across inferences. We use this insight to introduce a new algorithm that aggregates next token statistics by privately computing medians instead of averages. This approach leverages the fact that the median has decreased local sensitivity when next token predictions are similar, allowing us to state a data-dependent and ex-post DP guarantee about the privacy properties of this algorithm. Finally, we demonstrate improvements in terms of representativeness metrics (e.g., MAUVE) as well as downstream task performance. We show that our method produces high-quality synthetic data at significantly lower privacy cost than a previous state-of-the-art method.
FALCON: An ML Framework for Fully Automated Layout-Constrained Analog Circuit Design
May 28, 2025Designing analog circuits from performance specifications is a complex, multi-stage process encompassing topology selection, parameter inference, and layout feasibility. We introduce FALCON, a unified machine learning framework that enables fully automated, specification-driven analog circuit synthesis through topology selection and layout-constrained optimization. Given a target performance, FALCON first selects an appropriate circuit topology using a performance-driven classifier guided by human design heuristics. Next, it employs a custom, edge-centric graph neural network trained to map circuit topology and parameters to performance, enabling gradient-based parameter inference through the learned forward model. This inference is guided by a differentiable layout cost, derived from analytical equations capturing parasitic and frequency-dependent effects, and constrained by design rules. We train and evaluate FALCON on a large-scale custom dataset of 1M analog mm-wave circuits, generated and simulated using Cadence Spectre across 20 expert-designed topologies. Through this evaluation, FALCON demonstrates >99\% accuracy in topology inference, <10\% relative error in performance prediction, and efficient layout-aware design that completes in under 1 second per instance. Together, these results position FALCON as a practical and extensible foundation model for end-to-end analog circuit design automation.
Toward Super Agent System with Hybrid AI Routers
Apr 11, 2025AI Agents powered by Large Language Models are transforming the world through enormous applications. A super agent has the potential to fulfill diverse user needs, such as summarization, coding, and research, by accurately understanding user intent and leveraging the appropriate tools to solve tasks. However, to make such an agent viable for real-world deployment and accessible at scale, significant optimizations are required to ensure high efficiency and low cost. This paper presents a design of the Super Agent System. Upon receiving a user prompt, the system first detects the intent of the user, then routes the request to specialized task agents with the necessary tools or automatically generates agentic workflows. In practice, most applications directly serve as AI assistants on edge devices such as phones and robots. As different language models vary in capability and cloud-based models often entail high computational costs, latency, and privacy concerns, we then explore the hybrid mode where the router dynamically selects between local and cloud models based on task complexity. Finally, we introduce the blueprint of an on-device super agent enhanced with cloud. With advances in multi-modality models and edge hardware, we envision that most computations can be handled locally, with cloud collaboration only as needed. Such architecture paves the way for super agents to be seamlessly integrated into everyday life in the near future.
Enabling Weak Client Participation via On-device Knowledge Distillation in Heterogenous Federated Learning
Mar 14, 2025Online Knowledge Distillation (KD) is recently highlighted to train large models in Federated Learning (FL) environments. Many existing studies adopt the logit ensemble method to perform KD on the server side. However, they often assume that unlabeled data collected at the edge is centralized on the server. Moreover, the logit ensemble method personalizes local models, which can degrade the quality of soft targets, especially when data is highly non-IID. To address these critical limitations,we propose a novel on-device KD-based heterogeneous FL method. Our approach leverages a small auxiliary model to learn from labeled local data. Subsequently, a subset of clients with strong system resources transfers knowledge to a large model through on-device KD using their unlabeled data. Our extensive experiments demonstrate that our on-device KD-based heterogeneous FL method effectively utilizes the system resources of all edge devices as well as the unlabeled data, resulting in higher accuracy compared to SOTA KD-based FL methods.
Bridging the Safety Gap: A Guardrail Pipeline for Trustworthy LLM Inferences
Feb 12, 2025We present Wildflare GuardRail, a guardrail pipeline designed to enhance the safety and reliability of Large Language Model (LLM) inferences by systematically addressing risks across the entire processing workflow. Wildflare GuardRail integrates several core functional modules, including Safety Detector that identifies unsafe inputs and detects hallucinations in model outputs while generating root-cause explanations, Grounding that contextualizes user queries with information retrieved from vector databases, Customizer that adjusts outputs in real time using lightweight, rule-based wrappers, and Repairer that corrects erroneous LLM outputs using hallucination explanations provided by Safety Detector. Results show that our unsafe content detection model in Safety Detector achieves comparable performance with OpenAI API, though trained on a small dataset constructed with several public datasets. Meanwhile, the lightweight wrappers can address malicious URLs in model outputs in 1.06s per query with 100% accuracy without costly model calls. Moreover, the hallucination fixing model demonstrates effectiveness in reducing hallucinations with an accuracy of 80.7%.
Supervised Learning for Analog and RF Circuit Design: Benchmarks and Comparative Insights
Jan 21, 2025Automating analog and radio-frequency (RF) circuit design using machine learning (ML) significantly reduces the time and effort required for parameter optimization. This study explores supervised ML-based approaches for designing circuit parameters from performance specifications across various circuit types, including homogeneous and heterogeneous designs. By evaluating diverse ML models, from neural networks like transformers to traditional methods like random forests, we identify the best-performing models for each circuit. Our results show that simpler circuits, such as low-noise amplifiers, achieve exceptional accuracy with mean relative errors as low as 0.3% due to their linear parameter-performance relationships. In contrast, complex circuits, like power amplifiers and voltage-controlled oscillators, present challenges due to their non-linear interactions and larger design spaces. For heterogeneous circuits, our approach achieves an 88% reduction in errors with increased training data, with the receiver achieving a mean relative error as low as 0.23%, showcasing the scalability and accuracy of the proposed methodology. Additionally, we provide insights into model strengths, with transformers excelling in capturing non-linear mappings and k-nearest neighbors performing robustly in moderately linear parameter spaces, especially in heterogeneous circuits with larger datasets. This work establishes a foundation for extending ML-driven design automation, enabling more efficient and scalable circuit design workflows.
CryptoMamba: Leveraging State Space Models for Accurate Bitcoin Price Prediction
Jan 02, 2025



Predicting Bitcoin price remains a challenging problem due to the high volatility and complex non-linear dynamics of cryptocurrency markets. Traditional time-series models, such as ARIMA and GARCH, and recurrent neural networks, like LSTMs, have been widely applied to this task but struggle to capture the regime shifts and long-range dependencies inherent in the data. In this work, we propose CryptoMamba, a novel Mamba-based State Space Model (SSM) architecture designed to effectively capture long-range dependencies in financial time-series data. Our experiments show that CryptoMamba not only provides more accurate predictions but also offers enhanced generalizability across different market conditions, surpassing the limitations of previous models. Coupled with trading algorithms for real-world scenarios, CryptoMamba demonstrates its practical utility by translating accurate forecasts into financial outcomes. Our findings signal a huge advantage for SSMs in stock and cryptocurrency price forecasting tasks.
Fox-1 Technical Report
Nov 08, 2024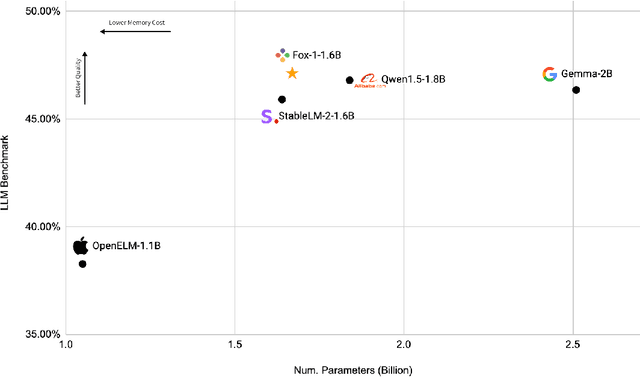

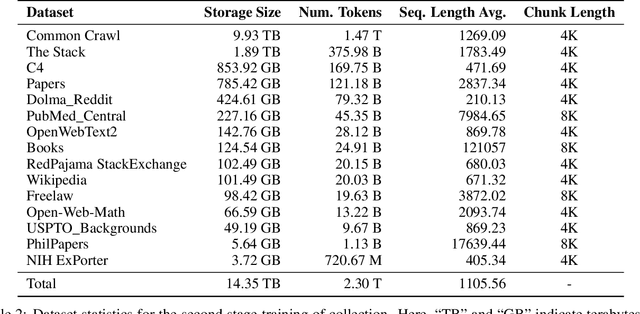
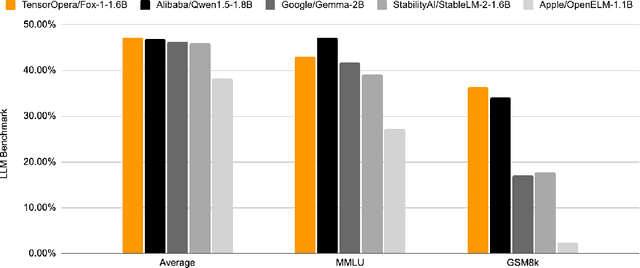
We present Fox-1, a series of small language models (SLMs) consisting of Fox-1-1.6B and Fox-1-1.6B-Instruct-v0.1. These models are pre-trained on 3 trillion tokens of web-scraped document data and fine-tuned with 5 billion tokens of instruction-following and multi-turn conversation data. Aiming to improve the pre-training efficiency, Fox-1-1.6B model introduces a novel 3-stage data curriculum across all the training data with 2K-8K sequence length. In architecture design, Fox-1 features a deeper layer structure, an expanded vocabulary, and utilizes Grouped Query Attention (GQA), offering a performant and efficient architecture compared to other SLMs. Fox-1 achieves better or on-par performance in various benchmarks compared to StableLM-2-1.6B, Gemma-2B, Qwen1.5-1.8B, and OpenELM1.1B, with competitive inference speed and throughput. The model weights have been released under the Apache 2.0 license, where we aim to promote the democratization of LLMs and make them fully accessible to the whole open-source community.
Alopex: A Computational Framework for Enabling On-Device Function Calls with LLMs
Nov 07, 2024



The rapid advancement of Large Language Models (LLMs) has led to their increased integration into mobile devices for personalized assistance, which enables LLMs to call external API functions to enhance their performance. However, challenges such as data scarcity, ineffective question formatting, and catastrophic forgetting hinder the development of on-device LLM agents. To tackle these issues, we propose Alopex, a framework that enables precise on-device function calls using the Fox LLM. Alopex introduces a logic-based method for generating high-quality training data and a novel ``description-question-output'' format for fine-tuning, reducing risks of function information leakage. Additionally, a data mixing strategy is used to mitigate catastrophic forgetting, combining function call data with textbook datasets to enhance performance in various tasks. Experimental results show that Alopex improves function call accuracy and significantly reduces catastrophic forgetting, providing a robust solution for integrating function call capabilities into LLMs without manual intervention.