 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupercharging Federated Intelligence Retrieval
Mar 26, 2026RAG typically assumes centralized access to documents, which breaks down when knowledge is distributed across private data silos. We propose a secure Federated RAG system built using Flower that performs local silo retrieval, while server-side aggregation and text generation run inside an attested, confidential compute environment, enabling confidential remote LLM inference even in the presence of honest-but-curious or compromised servers. We also propose a cascading inference approach that incorporates a non-confidential third-party model (e.g., Amazon Nova) as auxiliary context without weakening confidentiality.
Upgrade or Switch: Do We Need a New Registry Architecture for the Internet of AI Agents?
Jun 13, 2025The emerging Internet of AI Agents challenges existing web infrastructure designed for human-scale, reactive interactions. Unlike traditional web resources, autonomous AI agents initiate actions, maintain persistent state, spawn sub-agents, and negotiate directly with peers: demanding millisecond-level discovery, instant credential revocation, and cryptographic behavioral proofs that exceed current DNS/PKI capabilities. This paper analyzes whether to upgrade existing infrastructure or implement purpose-built registry architectures for autonomous agents. We identify critical failure points: DNS propagation (24-48 hours vs. required milliseconds), certificate revocation unable to scale to trillions of entities, and IPv4/IPv6 addressing inadequate for agent-scale routing. We evaluate three approaches: (1) Upgrade paths, (2) Switch options, (3) Hybrid registries. Drawing parallels to dialup-to-broadband transitions, we find that agent requirements constitute qualitative, and not incremental, changes. While upgrades offer compatibility and faster deployment, clean-slate solutions provide better performance but require longer for adoption. Our analysis suggests hybrid approaches will emerge, with centralized registries for critical agents and federated meshes for specialized use cases.
Alopex: A Computational Framework for Enabling On-Device Function Calls with LLMs
Nov 07, 2024



The rapid advancement of Large Language Models (LLMs) has led to their increased integration into mobile devices for personalized assistance, which enables LLMs to call external API functions to enhance their performance. However, challenges such as data scarcity, ineffective question formatting, and catastrophic forgetting hinder the development of on-device LLM agents. To tackle these issues, we propose Alopex, a framework that enables precise on-device function calls using the Fox LLM. Alopex introduces a logic-based method for generating high-quality training data and a novel ``description-question-output'' format for fine-tuning, reducing risks of function information leakage. Additionally, a data mixing strategy is used to mitigate catastrophic forgetting, combining function call data with textbook datasets to enhance performance in various tasks. Experimental results show that Alopex improves function call accuracy and significantly reduces catastrophic forgetting, providing a robust solution for integrating function call capabilities into LLMs without manual intervention.
PolyRouter: A Multi-LLM Querying System
Aug 26, 2024



With the rapid growth of Large Language Models (LLMs) across various domains, numerous new LLMs have emerged, each possessing domain-specific expertise. This proliferation has highlighted the need for quick, high-quality, and cost-effective LLM query response methods. Yet, no single LLM exists to efficiently balance this trilemma. Some models are powerful but extremely costly, while others are fast and inexpensive but qualitatively inferior. To address this challenge, we present PolyRouter, a non-monolithic LLM querying system that seamlessly integrates various LLM experts into a single query interface and dynamically routes incoming queries to the most high-performant expert based on query's requirements. Through extensive experiments, we demonstrate that when compared to standalone expert models, PolyRouter improves query efficiency by up to 40%, and leads to significant cost reductions of up to 30%, while maintaining or enhancing model performance by up to 10%.
ScaleLLM: A Resource-Frugal LLM Serving Framework by Optimizing End-to-End Efficiency
Jul 23, 2024Large language models (LLMs) have surged in popularity and are extensively used in commercial applications, where the efficiency of model serving is crucial for the user experience. Most current research focuses on optimizing individual sub-procedures, e.g. local inference and communication, however, there is no comprehensive framework that provides a holistic system view for optimizing LLM serving in an end-to-end manner. In this work, we conduct a detailed analysis to identify major bottlenecks that impact end-to-end latency in LLM serving systems. Our analysis reveals that a comprehensive LLM serving endpoint must address a series of efficiency bottlenecks that extend beyond LLM inference. We then propose ScaleLLM, an optimized system for resource-efficient LLM serving. Our extensive experiments reveal that with 64 concurrent requests, ScaleLLM achieves a 4.3x speed up over vLLM and outperforms state-of-the-arts with 1.5x higher throughput.
TorchOpera: A Compound AI System for LLM Safety
Jun 16, 2024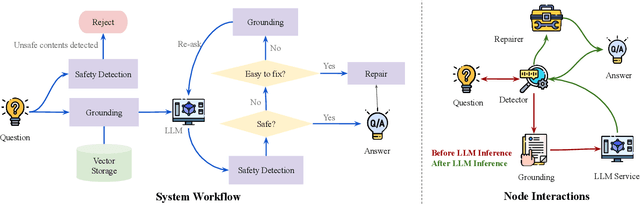



We introduce TorchOpera, a compound AI system for enhancing the safety and quality of prompts and responses for Large Language Models. TorchOpera ensures that all user prompts are safe, contextually grounded, and effectively processed, while enhancing LLM responses to be relevant and high quality. TorchOpera utilizes the vector database for contextual grounding, rule-based wrappers for flexible modifications, and specialized mechanisms for detecting and adjusting unsafe or incorrect content. We also provide a view of the compound AI system to reduce the computational cost. Extensive experiments show that TorchOpera ensures the safety, reliability, and applicability of LLMs in real-world settings while maintaining the efficiency of LLM responses.
MetisFL: An Embarrassingly Parallelized Controller for Scalable & Efficient Federated Learning Workflows
Nov 13, 2023



A Federated Learning (FL) system typically consists of two core processing entities: the federation controller and the learners. The controller is responsible for managing the execution of FL workflows across learners and the learners for training and evaluating federated models over their private datasets. While executing an FL workflow, the FL system has no control over the computational resources or data of the participating learners. Still, it is responsible for other operations, such as model aggregation, task dispatching, and scheduling. These computationally heavy operations generally need to be handled by the federation controller. Even though many FL systems have been recently proposed to facilitate the development of FL workflows, most of these systems overlook the scalability of the controller. To meet this need, we designed and developed a novel FL system called MetisFL, where the federation controller is the first-class citizen. MetisFL re-engineers all the operations conducted by the federation controller to accelerate the training of large-scale FL workflows. By quantitatively comparing MetisFL against other state-of-the-art FL systems, we empirically demonstrate that MetisFL leads to a 10-fold wall-clock time execution boost across a wide range of challenging FL workflows with increasing model sizes and federation sites.
Federated Learning over Harmonized Data Silos
May 15, 2023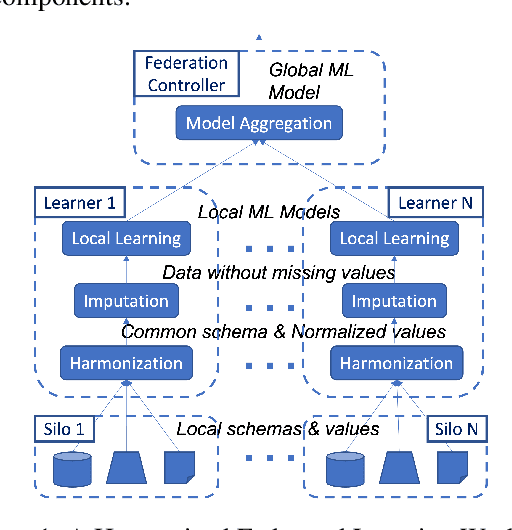



Federated Learning is a distributed machine learning approach that enables geographically distributed data silos to collaboratively learn a joint machine learning model without sharing data. Most of the existing work operates on unstructured data, such as images or text, or on structured data assumed to be consistent across the different sites. However, sites often have different schemata, data formats, data values, and access patterns. The field of data integration has developed many methods to address these challenges, including techniques for data exchange and query rewriting using declarative schema mappings, and for entity linkage. Therefore, we propose an architectural vision for an end-to-end Federated Learning and Integration system, incorporating the critical steps of data harmonization and data imputation, to spur further research on the intersection of data management information systems and machine learning.
Towards Sparsified Federated Neuroimaging Models via Weight Pruning
Aug 24, 2022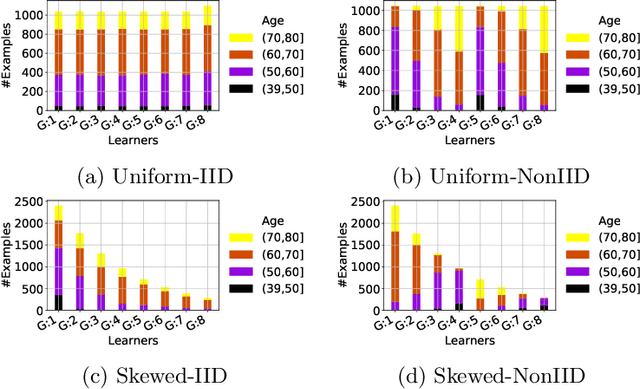
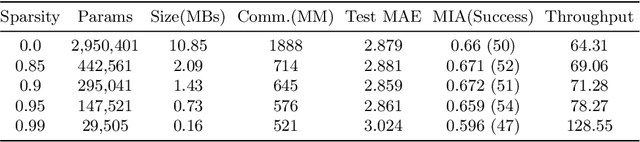
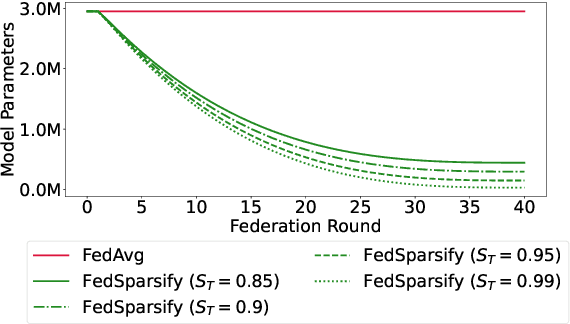
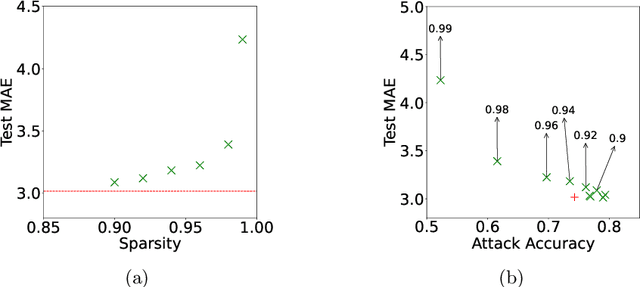
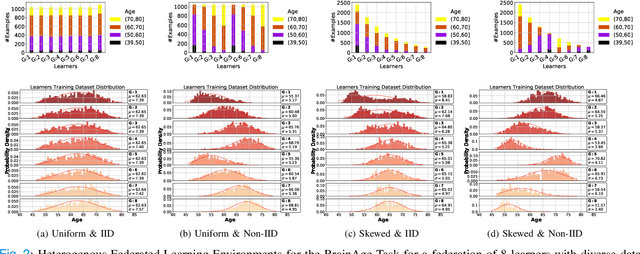
Federated training of large deep neural networks can often be restrictive due to the increasing costs of communicating the updates with increasing model sizes. Various model pruning techniques have been designed in centralized settings to reduce inference times. Combining centralized pruning techniques with federated training seems intuitive for reducing communication costs -- by pruning the model parameters right before the communication step. Moreover, such a progressive model pruning approach during training can also reduce training times/costs. To this end, we propose FedSparsify, which performs model pruning during federated training. In our experiments in centralized and federated settings on the brain age prediction task (estimating a person's age from their brain MRI), we demonstrate that models can be pruned up to 95% sparsity without affecting performance even in challenging federated learning environments with highly heterogeneous data distributions. One surprising benefit of model pruning is improved model privacy. We demonstrate that models with high sparsity are less susceptible to membership inference attacks, a type of privacy attack.
Secure Federated Learning for Neuroimaging
May 11, 2022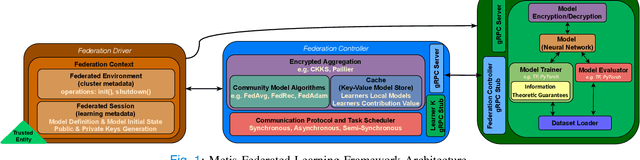
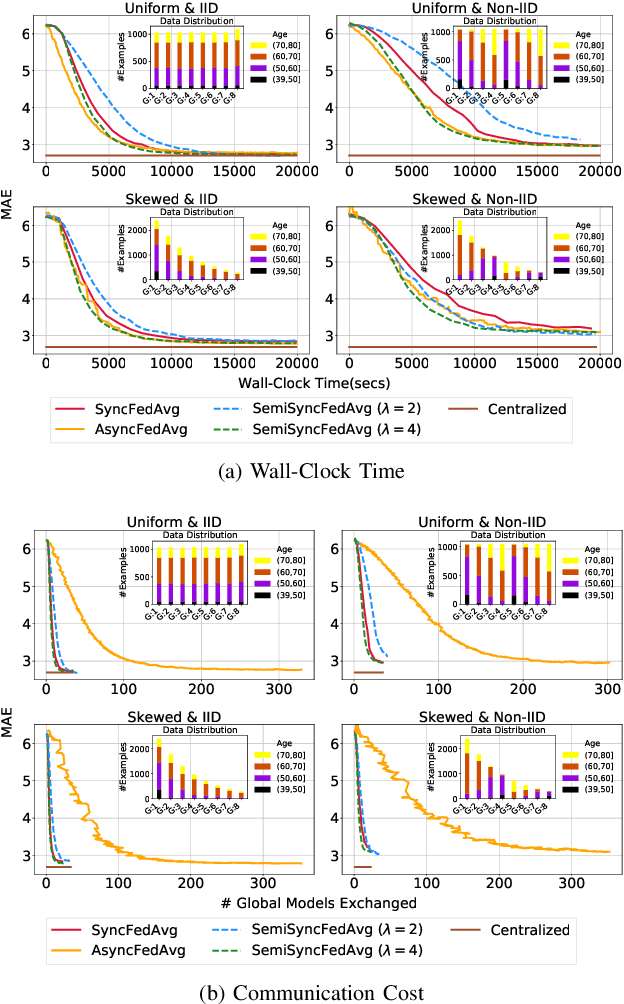
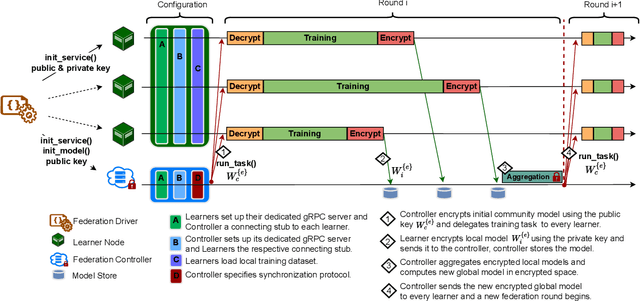
The amount of biomedical data continues to grow rapidly. However, the ability to collect data from multiple sites for joint analysis remains challenging due to security, privacy, and regulatory concerns. We present a Secure Federated Learning architecture, MetisFL, which enables distributed training of neural networks over multiple data sources without sharing data. Each site trains the neural network over its private data for some time, then shares the neural network parameters (i.e., weights, gradients) with a Federation Controller, which in turn aggregates the local models, sends the resulting community model back to each site, and the process repeats. Our architecture provides strong security and privacy. First, sample data never leaves a site. Second, neural parameters are encrypted before transmission and the community model is computed under fully-homomorphic encryption. Finally, we use information-theoretic methods to limit information leakage from the neural model to prevent a curious site from performing membership attacks. We demonstrate this architecture in neuroimaging. Specifically, we investigate training neural models to classify Alzheimer's disease, and estimate Brain Age, from magnetic resonance imaging datasets distributed across multiple sites, including heterogeneous environments where sites have different amounts of data, statistical distributions, and computational capabilities.