 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Define Your Terms" : Enhancing Efficient Offensive Speech Classification with Definition
Feb 05, 2024The propagation of offensive content through social media channels has garnered attention of the research community. Multiple works have proposed various semantically related yet subtle distinct categories of offensive speech. In this work, we explore meta-earning approaches to leverage the diversity of offensive speech corpora to enhance their reliable and efficient detection. We propose a joint embedding architecture that incorporates the input's label and definition for classification via Prototypical Network. Our model achieves at least 75% of the maximal F1-score while using less than 10% of the available training data across 4 datasets. Our experimental findings also provide a case study of training strategies valuable to combat resource scarcity.
Jointly Reparametrized Multi-Layer Adaptation for Efficient and Private Tuning
May 30, 2023

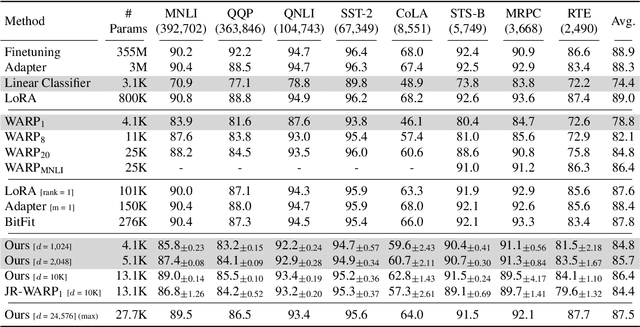
Efficient finetuning of pretrained language transformers is becoming increasingly prevalent for solving natural language processing tasks. While effective, it can still require a large number of tunable parameters. This can be a drawback for low-resource applications and training with differential-privacy constraints, where excessive noise may be introduced during finetuning. To this end, we propose a novel language transformer finetuning strategy that introduces task-specific parameters in multiple transformer layers. These parameters are derived from fixed random projections of a single trainable vector, enabling finetuning with significantly fewer parameters while maintaining performance. We achieve within 5% of full finetuning performance on GLUE tasks with as few as 4,100 parameters per task, outperforming other parameter-efficient finetuning approaches that use a similar number of per-task parameters. Besides, the random projections can be precomputed at inference, avoiding additional computational latency. All these make our method particularly appealing for low-resource applications. Finally, our method achieves the best or comparable utility compared to several recent finetuning methods when training with the same privacy constraints, underscoring its effectiveness and potential real-world impact.
Transferring Models Trained on Natural Images to 3D MRI via Position Encoded Slice Models
Mar 02, 2023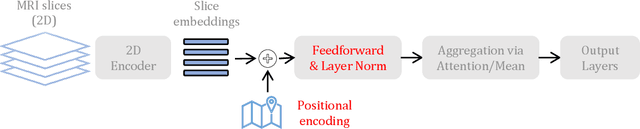
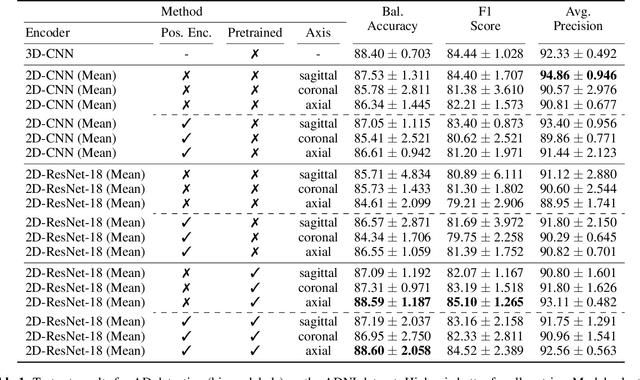
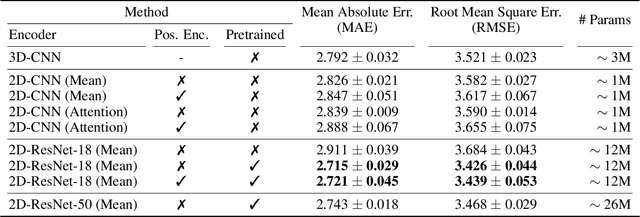
Transfer learning has remarkably improved computer vision. These advances also promise improvements in neuroimaging, where training set sizes are often small. However, various difficulties arise in directly applying models pretrained on natural images to radiologic images, such as MRIs. In particular, a mismatch in the input space (2D images vs. 3D MRIs) restricts the direct transfer of models, often forcing us to consider only a few MRI slices as input. To this end, we leverage the 2D-Slice-CNN architecture of Gupta et al. (2021), which embeds all the MRI slices with 2D encoders (neural networks that take 2D image input) and combines them via permutation-invariant layers. With the insight that the pretrained model can serve as the 2D encoder, we initialize the 2D encoder with ImageNet pretrained weights that outperform those initialized and trained from scratch on two neuroimaging tasks -- brain age prediction on the UK Biobank dataset and Alzheimer's disease detection on the ADNI dataset. Further, we improve the modeling capabilities of 2D-Slice models by incorporating spatial information through position embeddings, which can improve the performance in some cases.
Towards Sparsified Federated Neuroimaging Models via Weight Pruning
Aug 24, 2022
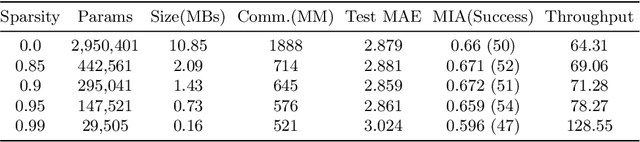
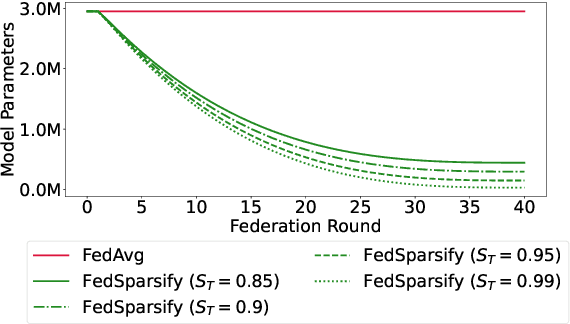
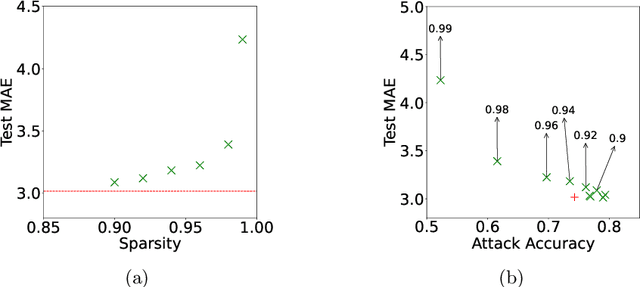
Federated training of large deep neural networks can often be restrictive due to the increasing costs of communicating the updates with increasing model sizes. Various model pruning techniques have been designed in centralized settings to reduce inference times. Combining centralized pruning techniques with federated training seems intuitive for reducing communication costs -- by pruning the model parameters right before the communication step. Moreover, such a progressive model pruning approach during training can also reduce training times/costs. To this end, we propose FedSparsify, which performs model pruning during federated training. In our experiments in centralized and federated settings on the brain age prediction task (estimating a person's age from their brain MRI), we demonstrate that models can be pruned up to 95% sparsity without affecting performance even in challenging federated learning environments with highly heterogeneous data distributions. One surprising benefit of model pruning is improved model privacy. We demonstrate that models with high sparsity are less susceptible to membership inference attacks, a type of privacy attack.
Secure Federated Learning for Neuroimaging
May 11, 2022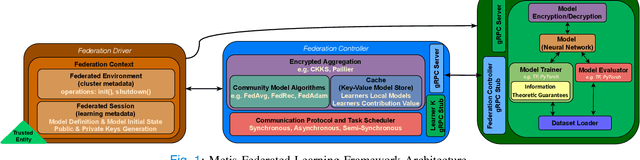
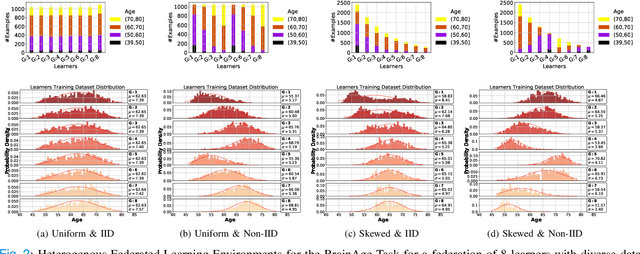
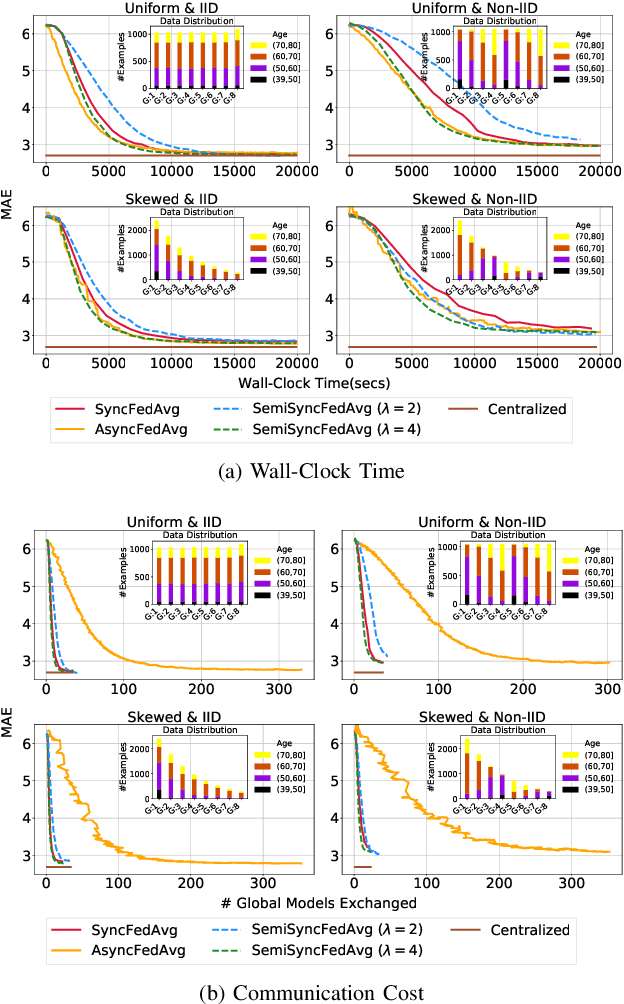
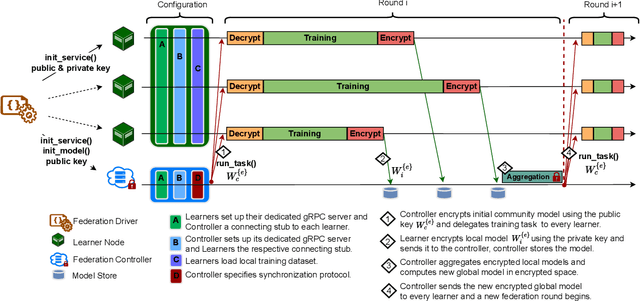
The amount of biomedical data continues to grow rapidly. However, the ability to collect data from multiple sites for joint analysis remains challenging due to security, privacy, and regulatory concerns. We present a Secure Federated Learning architecture, MetisFL, which enables distributed training of neural networks over multiple data sources without sharing data. Each site trains the neural network over its private data for some time, then shares the neural network parameters (i.e., weights, gradients) with a Federation Controller, which in turn aggregates the local models, sends the resulting community model back to each site, and the process repeats. Our architecture provides strong security and privacy. First, sample data never leaves a site. Second, neural parameters are encrypted before transmission and the community model is computed under fully-homomorphic encryption. Finally, we use information-theoretic methods to limit information leakage from the neural model to prevent a curious site from performing membership attacks. We demonstrate this architecture in neuroimaging. Specifically, we investigate training neural models to classify Alzheimer's disease, and estimate Brain Age, from magnetic resonance imaging datasets distributed across multiple sites, including heterogeneous environments where sites have different amounts of data, statistical distributions, and computational capabilities.
Federated Progressive Sparsification (Purge, Merge, Tune)+
Apr 26, 2022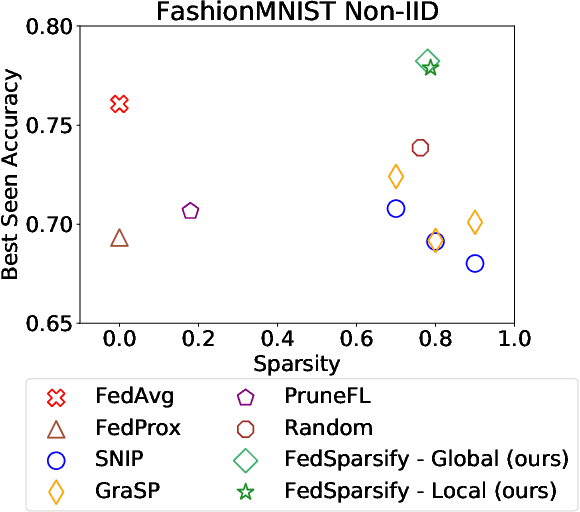
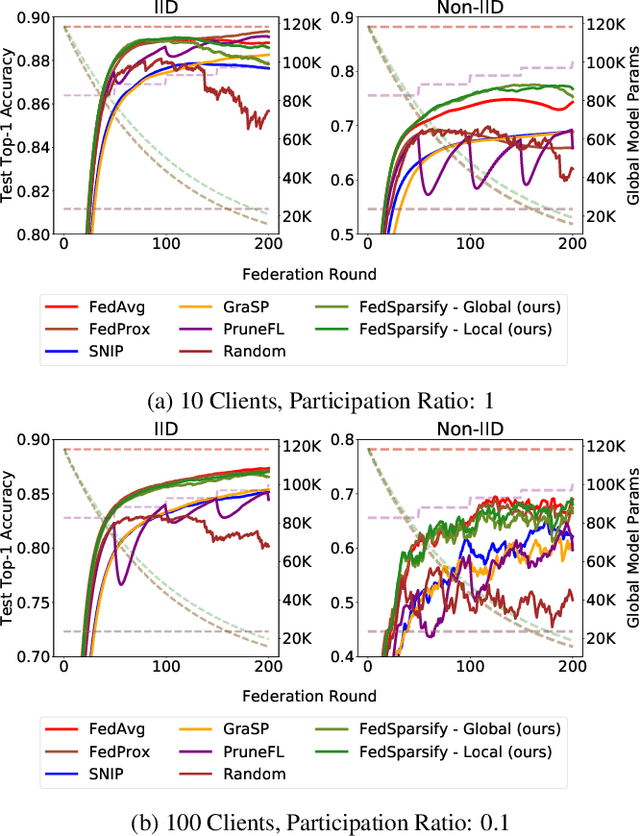
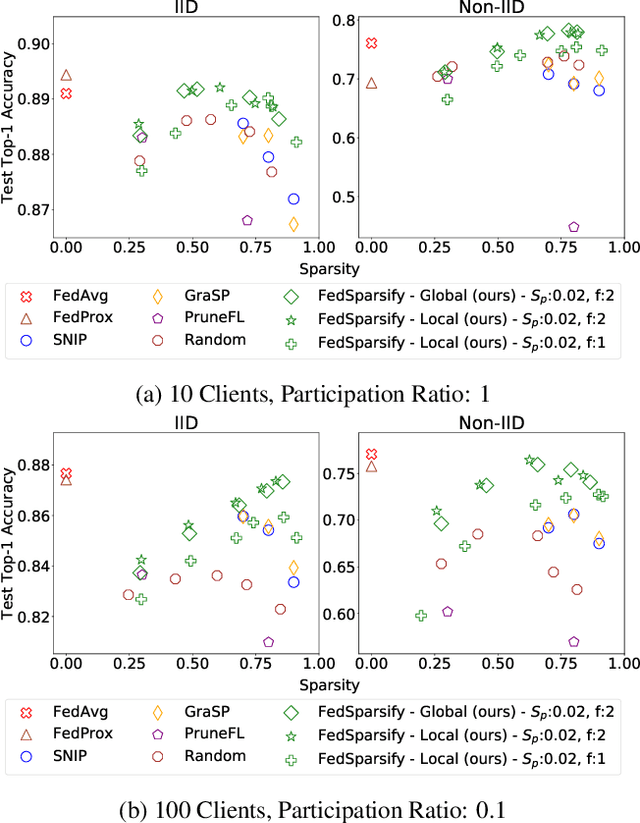
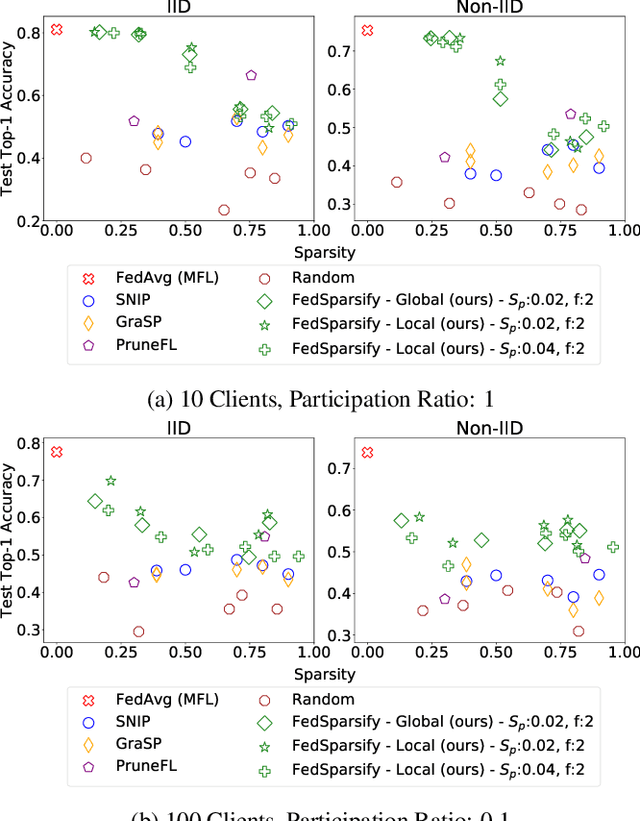
To improve federated training of neural networks, we develop FedSparsify, a sparsification strategy based on progressive weight magnitude pruning. Our method has several benefits. First, since the size of the network becomes increasingly smaller, computation and communication costs during training are reduced. Second, the models are incrementally constrained to a smaller set of parameters, which facilitates alignment/merging of the local models and improved learning performance at high sparsification rates. Third, the final sparsified model is significantly smaller, which improves inference efficiency and optimizes operations latency during encrypted communication. We show experimentally that FedSparsify learns a subnetwork of both high sparsity and learning performance. Our sparse models can reach a tenth of the size of the original model with the same or better accuracy compared to existing pruning and nonpruning baselines.
Mitigating Gender Bias in Distilled Language Models via Counterfactual Role Reversal
Mar 23, 2022

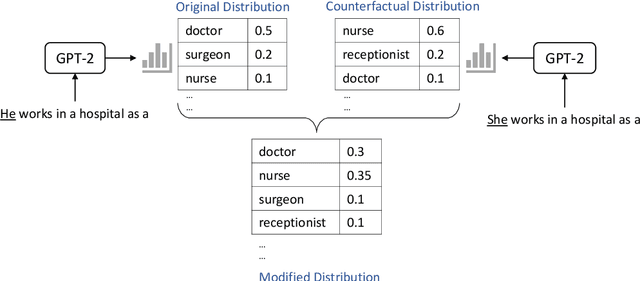
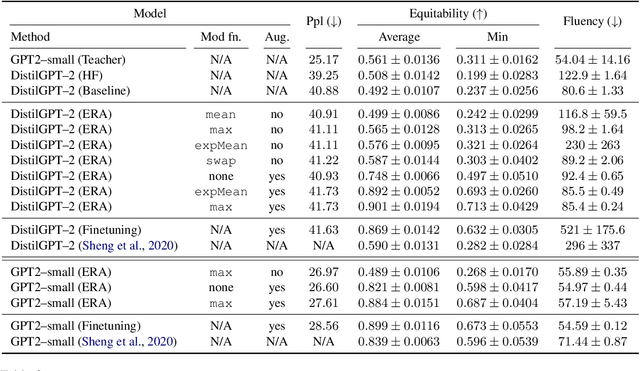
Language models excel at generating coherent text, and model compression techniques such as knowledge distillation have enabled their use in resource-constrained settings. However, these models can be biased in multiple ways, including the unfounded association of male and female genders with gender-neutral professions. Therefore, knowledge distillation without any fairness constraints may preserve or exaggerate the teacher model's biases onto the distilled model. To this end, we present a novel approach to mitigate gender disparity in text generation by learning a fair model during knowledge distillation. We propose two modifications to the base knowledge distillation based on counterfactual role reversal$\unicode{x2014}$modifying teacher probabilities and augmenting the training set. We evaluate gender polarity across professions in open-ended text generated from the resulting distilled and finetuned GPT$\unicode{x2012}$2 models and demonstrate a substantial reduction in gender disparity with only a minor compromise in utility. Finally, we observe that language models that reduce gender polarity in language generation do not improve embedding fairness or downstream classification fairness.
Attributing Fair Decisions with Attention Interventions
Sep 08, 2021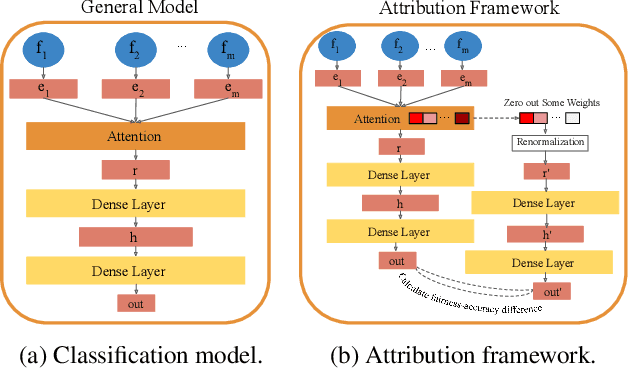

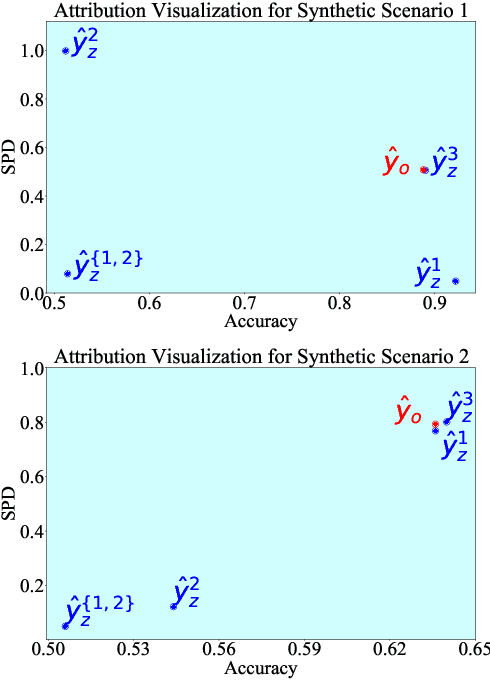

The widespread use of Artificial Intelligence (AI) in consequential domains, such as healthcare and parole decision-making systems, has drawn intense scrutiny on the fairness of these methods. However, ensuring fairness is often insufficient as the rationale for a contentious decision needs to be audited, understood, and defended. We propose that the attention mechanism can be used to ensure fair outcomes while simultaneously providing feature attributions to account for how a decision was made. Toward this goal, we design an attention-based model that can be leveraged as an attribution framework. It can identify features responsible for both performance and fairness of the model through attention interventions and attention weight manipulation. Using this attribution framework, we then design a post-processing bias mitigation strategy and compare it with a suite of baselines. We demonstrate the versatility of our approach by conducting experiments on two distinct data types, tabular and textual.
Secure Neuroimaging Analysis using Federated Learning with Homomorphic Encryption
Aug 07, 2021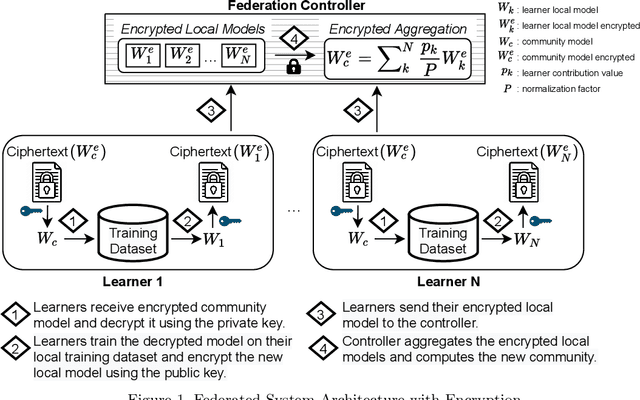
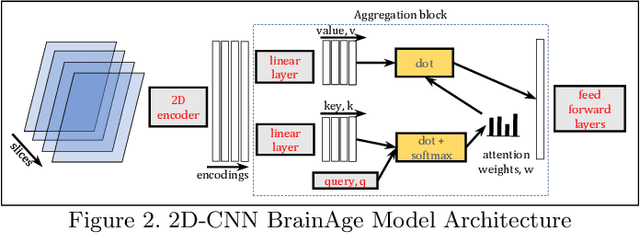
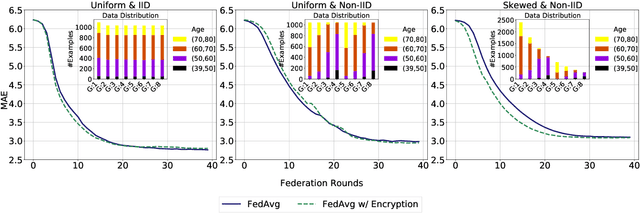
Federated learning (FL) enables distributed computation of machine learning models over various disparate, remote data sources, without requiring to transfer any individual data to a centralized location. This results in an improved generalizability of models and efficient scaling of computation as more sources and larger datasets are added to the federation. Nevertheless, recent membership attacks show that private or sensitive personal data can sometimes be leaked or inferred when model parameters or summary statistics are shared with a central site, requiring improved security solutions. In this work, we propose a framework for secure FL using fully-homomorphic encryption (FHE). Specifically, we use the CKKS construction, an approximate, floating point compatible scheme that benefits from ciphertext packing and rescaling. In our evaluation on large-scale brain MRI datasets, we use our proposed secure FL framework to train a deep learning model to predict a person's age from distributed MRI scans, a common benchmarking task, and demonstrate that there is no degradation in the learning performance between the encrypted and non-encrypted federated models.
Membership Inference Attacks on Deep Regression Models for Neuroimaging
Jun 03, 2021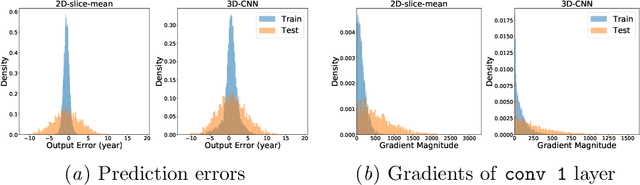


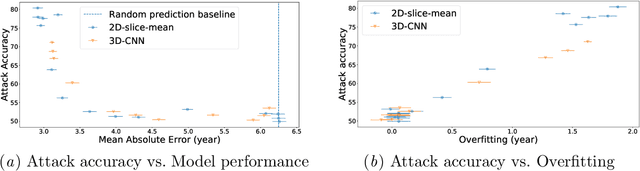
Ensuring the privacy of research participants is vital, even more so in healthcare environments. Deep learning approaches to neuroimaging require large datasets, and this often necessitates sharing data between multiple sites, which is antithetical to the privacy objectives. Federated learning is a commonly proposed solution to this problem. It circumvents the need for data sharing by sharing parameters during the training process. However, we demonstrate that allowing access to parameters may leak private information even if data is never directly shared. In particular, we show that it is possible to infer if a sample was used to train the model given only access to the model prediction (black-box) or access to the model itself (white-box) and some leaked samples from the training data distribution. Such attacks are commonly referred to as Membership Inference attacks. We show realistic Membership Inference attacks on deep learning models trained for 3D neuroimaging tasks in a centralized as well as decentralized setup. We demonstrate feasible attacks on brain age prediction models (deep learning models that predict a person's age from their brain MRI scan). We correctly identified whether an MRI scan was used in model training with a 60% to over 80% success rate depending on model complexity and security assumptions.