 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHawk: Accurate and Fast Privacy-Preserving Machine Learning Using Secure Lookup Table Computation
Mar 26, 2024



Training machine learning models on data from multiple entities without direct data sharing can unlock applications otherwise hindered by business, legal, or ethical constraints. In this work, we design and implement new privacy-preserving machine learning protocols for logistic regression and neural network models. We adopt a two-server model where data owners secret-share their data between two servers that train and evaluate the model on the joint data. A significant source of inefficiency and inaccuracy in existing methods arises from using Yao's garbled circuits to compute non-linear activation functions. We propose new methods for computing non-linear functions based on secret-shared lookup tables, offering both computational efficiency and improved accuracy. Beyond introducing leakage-free techniques, we initiate the exploration of relaxed security measures for privacy-preserving machine learning. Instead of claiming that the servers gain no knowledge during the computation, we contend that while some information is revealed about access patterns to lookup tables, it maintains epsilon-dX-privacy. Leveraging this relaxation significantly reduces the computational resources needed for training. We present new cryptographic protocols tailored to this relaxed security paradigm and define and analyze the leakage. Our evaluations show that our logistic regression protocol is up to 9x faster, and the neural network training is up to 688x faster than SecureML. Notably, our neural network achieves an accuracy of 96.6% on MNIST in 15 epochs, outperforming prior benchmarks that capped at 93.4% using the same architecture.
Secure Federated Learning for Neuroimaging
May 11, 2022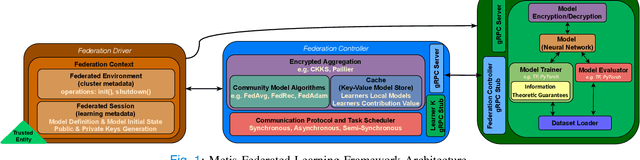
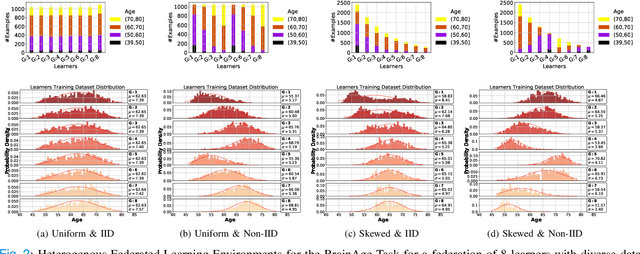
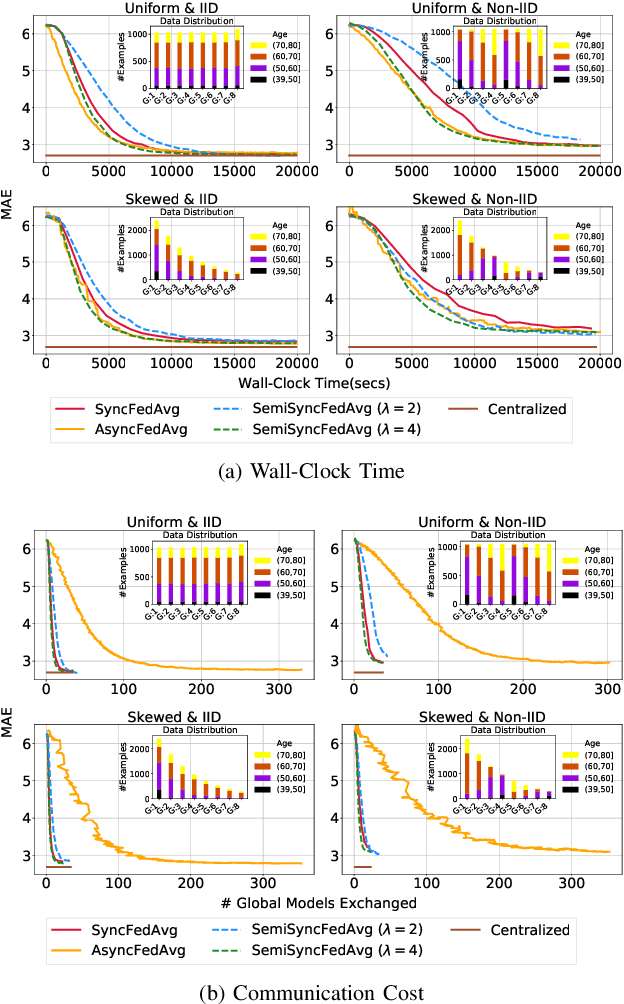
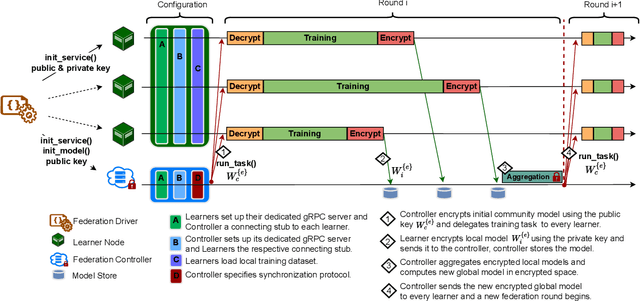
The amount of biomedical data continues to grow rapidly. However, the ability to collect data from multiple sites for joint analysis remains challenging due to security, privacy, and regulatory concerns. We present a Secure Federated Learning architecture, MetisFL, which enables distributed training of neural networks over multiple data sources without sharing data. Each site trains the neural network over its private data for some time, then shares the neural network parameters (i.e., weights, gradients) with a Federation Controller, which in turn aggregates the local models, sends the resulting community model back to each site, and the process repeats. Our architecture provides strong security and privacy. First, sample data never leaves a site. Second, neural parameters are encrypted before transmission and the community model is computed under fully-homomorphic encryption. Finally, we use information-theoretic methods to limit information leakage from the neural model to prevent a curious site from performing membership attacks. We demonstrate this architecture in neuroimaging. Specifically, we investigate training neural models to classify Alzheimer's disease, and estimate Brain Age, from magnetic resonance imaging datasets distributed across multiple sites, including heterogeneous environments where sites have different amounts of data, statistical distributions, and computational capabilities.
Secure Neuroimaging Analysis using Federated Learning with Homomorphic Encryption
Aug 07, 2021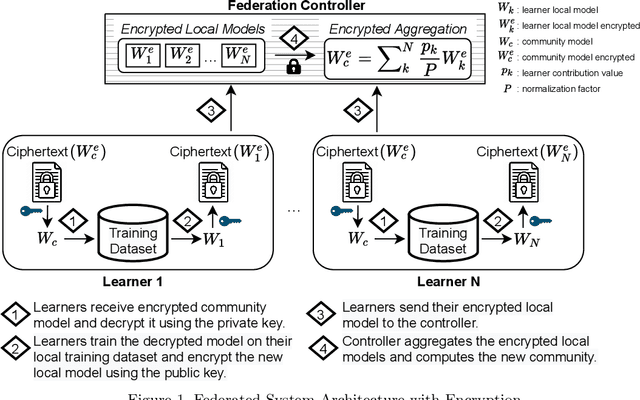
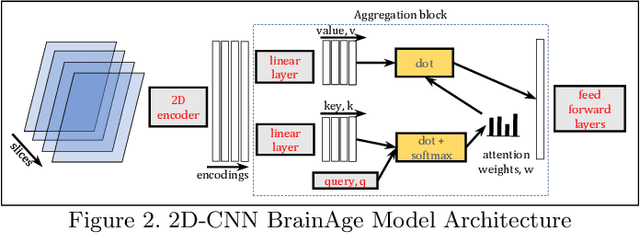
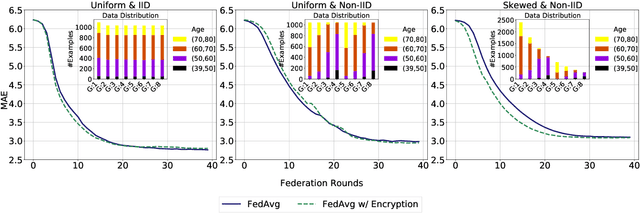
Federated learning (FL) enables distributed computation of machine learning models over various disparate, remote data sources, without requiring to transfer any individual data to a centralized location. This results in an improved generalizability of models and efficient scaling of computation as more sources and larger datasets are added to the federation. Nevertheless, recent membership attacks show that private or sensitive personal data can sometimes be leaked or inferred when model parameters or summary statistics are shared with a central site, requiring improved security solutions. In this work, we propose a framework for secure FL using fully-homomorphic encryption (FHE). Specifically, we use the CKKS construction, an approximate, floating point compatible scheme that benefits from ciphertext packing and rescaling. In our evaluation on large-scale brain MRI datasets, we use our proposed secure FL framework to train a deep learning model to predict a person's age from distributed MRI scans, a common benchmarking task, and demonstrate that there is no degradation in the learning performance between the encrypted and non-encrypted federated models.
Exacerbating Algorithmic Bias through Fairness Attacks
Dec 16, 2020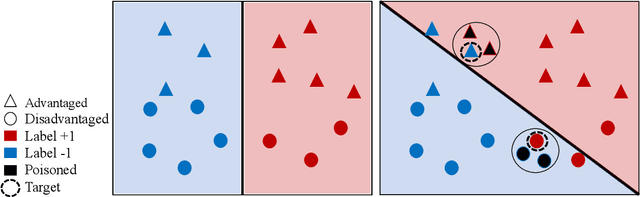
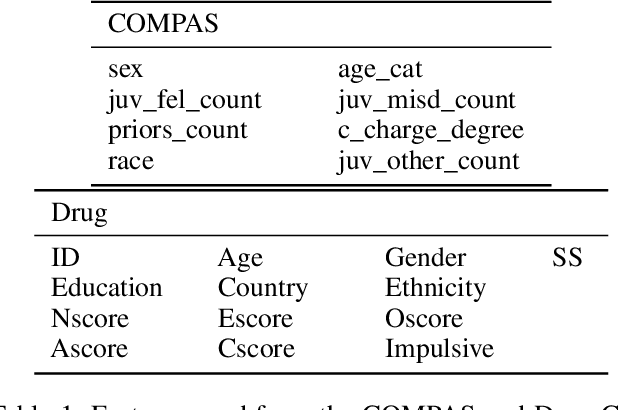
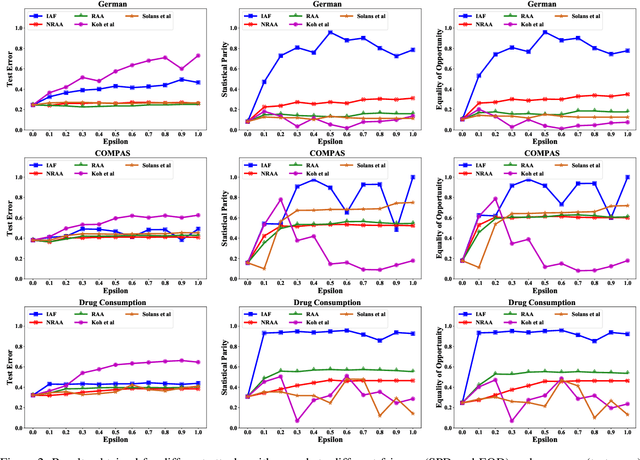
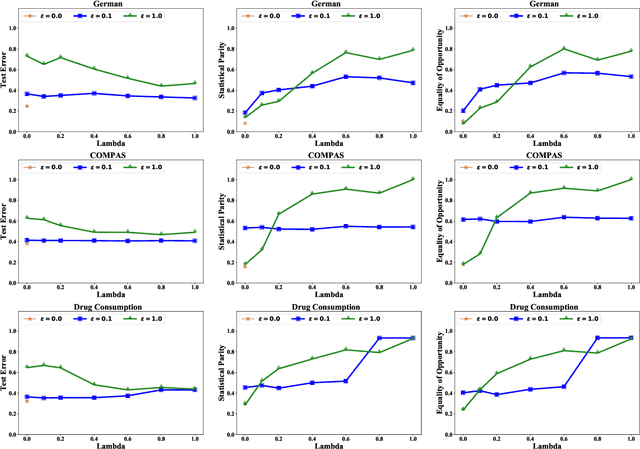
Algorithmic fairness has attracted significant attention in recent years, with many quantitative measures suggested for characterizing the fairness of different machine learning algorithms. Despite this interest, the robustness of those fairness measures with respect to an intentional adversarial attack has not been properly addressed. Indeed, most adversarial machine learning has focused on the impact of malicious attacks on the accuracy of the system, without any regard to the system's fairness. We propose new types of data poisoning attacks where an adversary intentionally targets the fairness of a system. Specifically, we propose two families of attacks that target fairness measures. In the anchoring attack, we skew the decision boundary by placing poisoned points near specific target points to bias the outcome. In the influence attack on fairness, we aim to maximize the covariance between the sensitive attributes and the decision outcome and affect the fairness of the model. We conduct extensive experiments that indicate the effectiveness of our proposed attacks.