 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIG-Bench Extra Hard
Feb 26, 2025Large language models (LLMs) are increasingly deployed in everyday applications, demanding robust general reasoning capabilities and diverse reasoning skillset. However, current LLM reasoning benchmarks predominantly focus on mathematical and coding abilities, leaving a gap in evaluating broader reasoning proficiencies. One particular exception is the BIG-Bench dataset, which has served as a crucial benchmark for evaluating the general reasoning capabilities of LLMs, thanks to its diverse set of challenging tasks that allowed for a comprehensive assessment of general reasoning across various skills within a unified framework. However, recent advances in LLMs have led to saturation on BIG-Bench, and its harder version BIG-Bench Hard (BBH). State-of-the-art models achieve near-perfect scores on many tasks in BBH, thus diminishing its utility. To address this limitation, we introduce BIG-Bench Extra Hard (BBEH), a new benchmark designed to push the boundaries of LLM reasoning evaluation. BBEH replaces each task in BBH with a novel task that probes a similar reasoning capability but exhibits significantly increased difficulty. We evaluate various models on BBEH and observe a (harmonic) average accuracy of 9.8\% for the best general-purpose model and 44.8\% for the best reasoning-specialized model, indicating substantial room for improvement and highlighting the ongoing challenge of achieving robust general reasoning in LLMs. We release BBEH publicly at: https://github.com/google-deepmind/bbeh.
MetisFL: An Embarrassingly Parallelized Controller for Scalable & Efficient Federated Learning Workflows
Nov 13, 2023



A Federated Learning (FL) system typically consists of two core processing entities: the federation controller and the learners. The controller is responsible for managing the execution of FL workflows across learners and the learners for training and evaluating federated models over their private datasets. While executing an FL workflow, the FL system has no control over the computational resources or data of the participating learners. Still, it is responsible for other operations, such as model aggregation, task dispatching, and scheduling. These computationally heavy operations generally need to be handled by the federation controller. Even though many FL systems have been recently proposed to facilitate the development of FL workflows, most of these systems overlook the scalability of the controller. To meet this need, we designed and developed a novel FL system called MetisFL, where the federation controller is the first-class citizen. MetisFL re-engineers all the operations conducted by the federation controller to accelerate the training of large-scale FL workflows. By quantitatively comparing MetisFL against other state-of-the-art FL systems, we empirically demonstrate that MetisFL leads to a 10-fold wall-clock time execution boost across a wide range of challenging FL workflows with increasing model sizes and federation sites.
Secure Federated Learning for Neuroimaging
May 11, 2022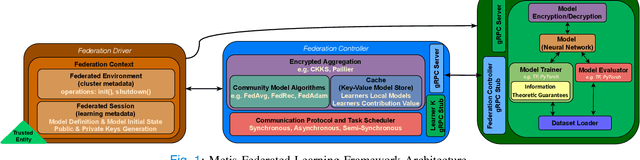
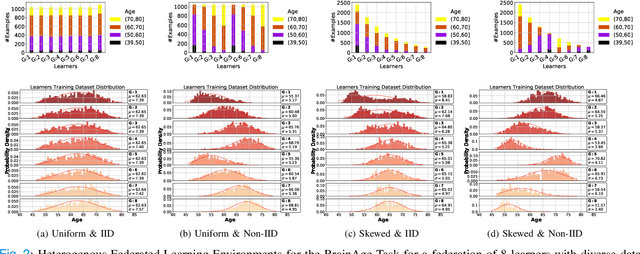
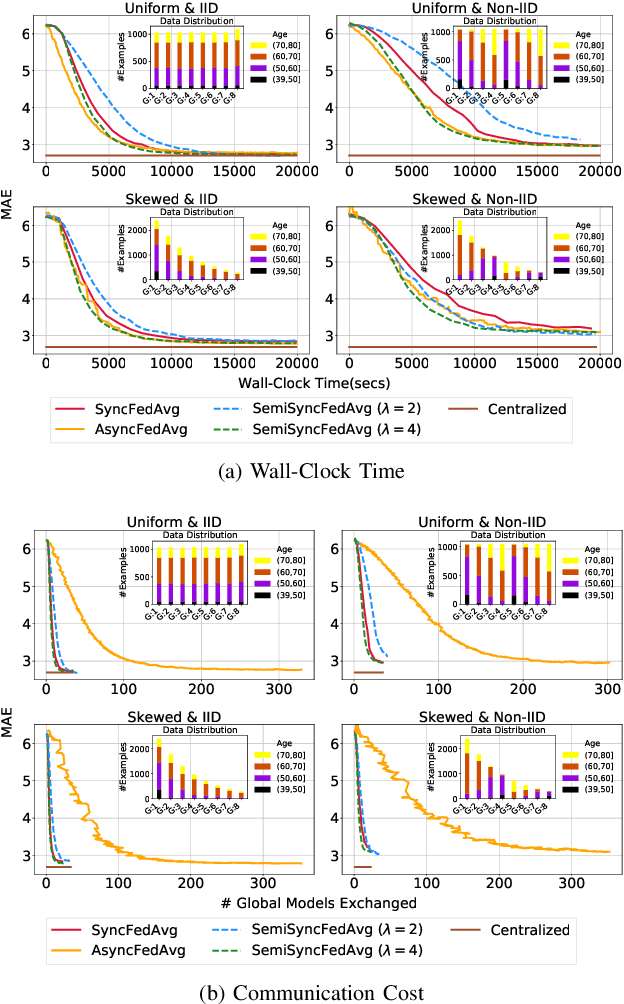
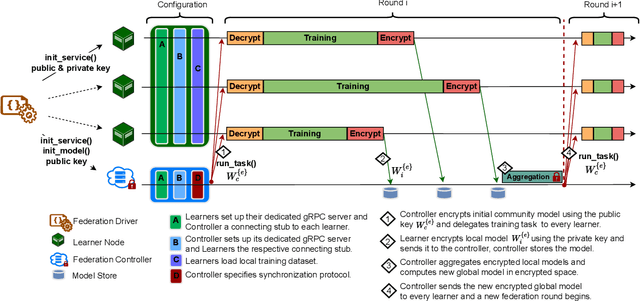
The amount of biomedical data continues to grow rapidly. However, the ability to collect data from multiple sites for joint analysis remains challenging due to security, privacy, and regulatory concerns. We present a Secure Federated Learning architecture, MetisFL, which enables distributed training of neural networks over multiple data sources without sharing data. Each site trains the neural network over its private data for some time, then shares the neural network parameters (i.e., weights, gradients) with a Federation Controller, which in turn aggregates the local models, sends the resulting community model back to each site, and the process repeats. Our architecture provides strong security and privacy. First, sample data never leaves a site. Second, neural parameters are encrypted before transmission and the community model is computed under fully-homomorphic encryption. Finally, we use information-theoretic methods to limit information leakage from the neural model to prevent a curious site from performing membership attacks. We demonstrate this architecture in neuroimaging. Specifically, we investigate training neural models to classify Alzheimer's disease, and estimate Brain Age, from magnetic resonance imaging datasets distributed across multiple sites, including heterogeneous environments where sites have different amounts of data, statistical distributions, and computational capabilities.
Secure Neuroimaging Analysis using Federated Learning with Homomorphic Encryption
Aug 07, 2021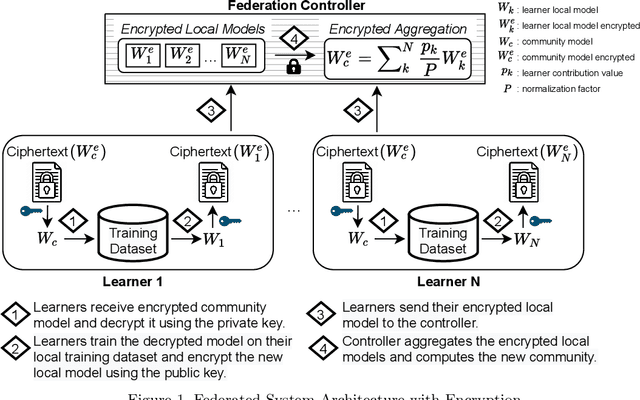
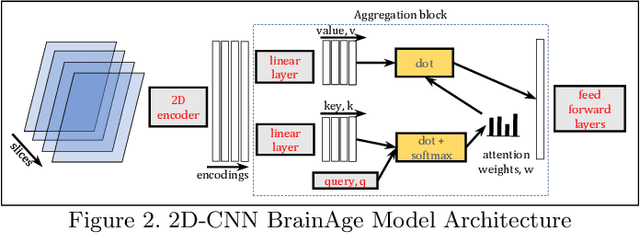
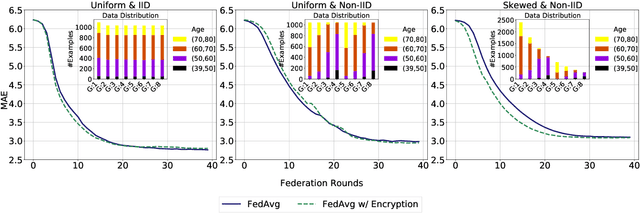
Federated learning (FL) enables distributed computation of machine learning models over various disparate, remote data sources, without requiring to transfer any individual data to a centralized location. This results in an improved generalizability of models and efficient scaling of computation as more sources and larger datasets are added to the federation. Nevertheless, recent membership attacks show that private or sensitive personal data can sometimes be leaked or inferred when model parameters or summary statistics are shared with a central site, requiring improved security solutions. In this work, we propose a framework for secure FL using fully-homomorphic encryption (FHE). Specifically, we use the CKKS construction, an approximate, floating point compatible scheme that benefits from ciphertext packing and rescaling. In our evaluation on large-scale brain MRI datasets, we use our proposed secure FL framework to train a deep learning model to predict a person's age from distributed MRI scans, a common benchmarking task, and demonstrate that there is no degradation in the learning performance between the encrypted and non-encrypted federated models.