 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-free Alignment for Conflicting Objectives
Feb 02, 2026Direct alignment methods are increasingly used to align large language models (LLMs) with human preferences. However, many real-world alignment problems involve multiple conflicting objectives, where naive aggregation of preferences can lead to unstable training and poor trade-offs. In particular, weighted loss methods may fail to identify update directions that simultaneously improve all objectives, and existing multi-objective approaches often rely on explicit reward models, introducing additional complexity and distorting user-specified preferences. The contributions of this paper are two-fold. First, we propose a Reward-free Alignment framework for Conflicted Objectives (RACO) that directly leverages pairwise preference data and resolves gradient conflicts via a novel clipped variant of conflict-averse gradient descent. We provide convergence guarantees to Pareto-critical points that respect user-specified objective weights, and further show that clipping can strictly improve convergence rate in the two-objective setting. Second, we improve our method using some heuristics and conduct experiments to demonstrate the compatibility of the proposed framework for LLM alignment. Both qualitative and quantitative evaluations on multi-objective summarization and safety alignment tasks across multiple LLM families (Qwen 3, Llama 3, Gemma 3) show that our method consistently achieves better Pareto trade-offs compared to existing multi-objective alignment baselines.
GenEnv: Difficulty-Aligned Co-Evolution Between LLM Agents and Environment Simulators
Dec 23, 2025Training capable Large Language Model (LLM) agents is critically bottlenecked by the high cost and static nature of real-world interaction data. We address this by introducing GenEnv, a framework that establishes a difficulty-aligned co-evolutionary game between an agent and a scalable, generative environment simulator. Unlike traditional methods that evolve models on static datasets, GenEnv instantiates a dataevolving: the simulator acts as a dynamic curriculum policy, continuously generating tasks specifically tailored to the agent's ``zone of proximal development''. This process is guided by a simple but effective $α$-Curriculum Reward, which aligns task difficulty with the agent's current capabilities. We evaluate GenEnv on five benchmarks, including API-Bank, ALFWorld, BFCL, Bamboogle, and TravelPlanner. Across these tasks, GenEnv improves agent performance by up to \textbf{+40.3\%} over 7B baselines and matches or exceeds the average performance of larger models. Compared to Gemini 2.5 Pro-based offline data augmentation, GenEnv achieves better performance while using 3.3$\times$ less data. By shifting from static supervision to adaptive simulation, GenEnv provides a data-efficient pathway for scaling agent capabilities.
Exploration vs Exploitation: Rethinking RLVR through Clipping, Entropy, and Spurious Reward
Dec 21, 2025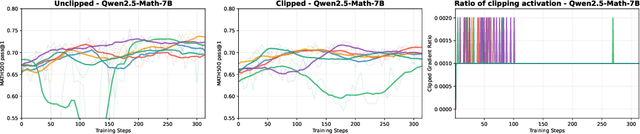
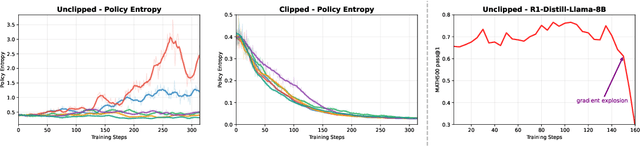

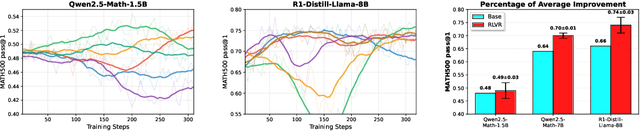
This paper examines the exploration-exploitation trade-off in reinforcement learning with verifiable rewards (RLVR), a framework for improving the reasoning of Large Language Models (LLMs). Recent studies suggest that RLVR can elicit strong mathematical reasoning in LLMs through two seemingly paradoxical mechanisms: spurious rewards, which suppress exploitation by rewarding outcomes unrelated to the ground truth, and entropy minimization, which suppresses exploration by pushing the model toward more confident and deterministic outputs, highlighting a puzzling dynamic: both discouraging exploitation and discouraging exploration improve reasoning performance, yet the underlying principles that reconcile these effects remain poorly understood. We focus on two fundamental questions: (i) how policy entropy relates to performance, and (ii) whether spurious rewards yield gains, potentially through the interplay of clipping bias and model contamination. Our results show that clipping bias under spurious rewards reduces policy entropy, leading to more confident and deterministic outputs, while entropy minimization alone is insufficient for improvement. We further propose a reward-misalignment model explaining why spurious rewards can enhance performance beyond contaminated settings. Our findings clarify the mechanisms behind spurious-reward benefits and provide principles for more effective RLVR training.
Spectral Policy Optimization: Coloring your Incorrect Reasoning in GRPO
May 16, 2025Reinforcement learning (RL) has demonstrated significant success in enhancing reasoning capabilities in large language models (LLMs). One of the most widely used RL methods is Group Relative Policy Optimization (GRPO)~\cite{Shao-2024-Deepseekmath}, known for its memory efficiency and success in training DeepSeek-R1~\cite{Guo-2025-Deepseek}. However, GRPO stalls when all sampled responses in a group are incorrect -- referred to as an \emph{all-negative-sample} group -- as it fails to update the policy, hindering learning progress. The contributions of this paper are two-fold. First, we propose a simple yet effective framework that introduces response diversity within all-negative-sample groups in GRPO using AI feedback. We also provide a theoretical analysis, via a stylized model, showing how this diversification improves learning dynamics. Second, we empirically validate our approach, showing the improved performance across various model sizes (7B, 14B, 32B) in both offline and online learning settings with 10 benchmarks, including base and distilled variants. Our findings highlight that learning from all-negative-sample groups is not only feasible but beneficial, advancing recent insights from \citet{Xiong-2025-Minimalist}.
ComPO: Preference Alignment via Comparison Oracles
May 08, 2025Direct alignment methods are increasingly used for aligning large language models (LLMs) with human preferences. However, these methods suffer from the issues of verbosity and likelihood displacement, which can be driven by the noisy preference pairs that induce similar likelihood for preferred and dispreferred responses. The contributions of this paper are two-fold. First, we propose a new preference alignment method based on comparison oracles and provide the convergence guarantee for its basic scheme. Second, we improve our method using some heuristics and conduct the experiments to demonstrate the flexibility and compatibility of practical scheme in improving the performance of LLMs using noisy preference pairs. Evaluations are conducted across multiple base and instruction-tuned models (Mistral-7B, Llama-3-8B and Gemma-2-9B) with benchmarks (AlpacaEval 2, MT-Bench and Arena-Hard). Experimental results show the effectiveness of our method as an alternative to addressing the limitations of existing direct alignment methods. A highlight of our work is that we evidence the importance of designing specialized methods for preference pairs with distinct likelihood margin, which complements the recent findings in \citet{Razin-2025-Unintentional}.
BIG-Bench Extra Hard
Feb 26, 2025Large language models (LLMs) are increasingly deployed in everyday applications, demanding robust general reasoning capabilities and diverse reasoning skillset. However, current LLM reasoning benchmarks predominantly focus on mathematical and coding abilities, leaving a gap in evaluating broader reasoning proficiencies. One particular exception is the BIG-Bench dataset, which has served as a crucial benchmark for evaluating the general reasoning capabilities of LLMs, thanks to its diverse set of challenging tasks that allowed for a comprehensive assessment of general reasoning across various skills within a unified framework. However, recent advances in LLMs have led to saturation on BIG-Bench, and its harder version BIG-Bench Hard (BBH). State-of-the-art models achieve near-perfect scores on many tasks in BBH, thus diminishing its utility. To address this limitation, we introduce BIG-Bench Extra Hard (BBEH), a new benchmark designed to push the boundaries of LLM reasoning evaluation. BBEH replaces each task in BBH with a novel task that probes a similar reasoning capability but exhibits significantly increased difficulty. We evaluate various models on BBEH and observe a (harmonic) average accuracy of 9.8\% for the best general-purpose model and 44.8\% for the best reasoning-specialized model, indicating substantial room for improvement and highlighting the ongoing challenge of achieving robust general reasoning in LLMs. We release BBEH publicly at: https://github.com/google-deepmind/bbeh.
Displacement-Sparse Neural Optimal Transport
Feb 03, 2025Optimal Transport (OT) theory seeks to determine the map $T:X \to Y$ that transports a source measure $P$ to a target measure $Q$, minimizing the cost $c(\mathbf{x}, T(\mathbf{x}))$ between $\mathbf{x}$ and its image $T(\mathbf{x})$. Building upon the Input Convex Neural Network OT solver and incorporating the concept of displacement-sparse maps, we introduce a sparsity penalty into the minimax Wasserstein formulation, promote sparsity in displacement vectors $\Delta(\mathbf{x}) := T(\mathbf{x}) - \mathbf{x}$, and enhance the interpretability of the resulting map. However, increasing sparsity often reduces feasibility, causing $T_{\#}(P)$ to deviate more significantly from the target measure. In low-dimensional settings, we propose a heuristic framework to balance the trade-off between sparsity and feasibility by dynamically adjusting the sparsity intensity parameter during training. For high-dimensional settings, we directly constrain the dimensionality of displacement vectors by enforcing $\dim(\Delta(\mathbf{x})) \leq l$, where $l < d$ for $X \subseteq \mathbb{R}^d$. Among maps satisfying this constraint, we aim to identify the most feasible one. This goal can be effectively achieved by adapting our low-dimensional heuristic framework without resorting to dimensionality reduction. We validate our method on both synthesized sc-RNA and real 4i cell perturbation datasets, demonstrating improvements over existing methods.
Geometric Framework for 3D Cell Segmentation Correction
Feb 03, 2025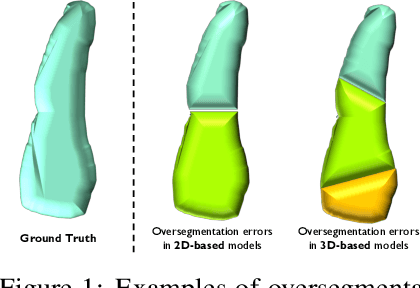
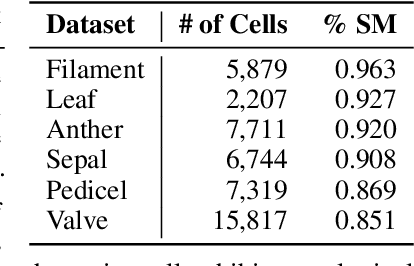
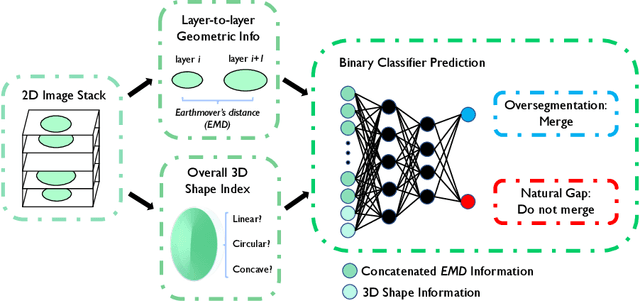
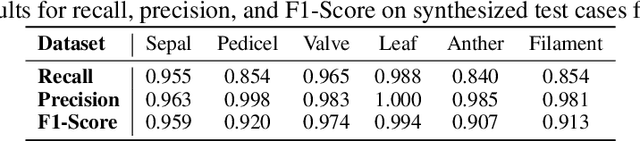
3D cellular image segmentation methods are commonly divided into non-2D-based and 2D-based approaches, the latter reconstructing 3D shapes from the segmentation results of 2D layers. However, errors in 2D results often propagate, leading to oversegmentations in the final 3D results. To tackle this issue, we introduce an interpretable geometric framework that addresses the oversegmentations by correcting the 2D segmentation results based on geometric information from adjacent layers. Leveraging both geometric (layer-to-layer, 2D) and topological (3D shape) features, we use binary classification to determine whether neighboring cells should be stitched. We develop a pre-trained classifier on public plant cell datasets and validate its performance on animal cell datasets, confirming its effectiveness in correcting oversegmentations under the transfer learning setting. Furthermore, we demonstrate that our framework can be extended to correcting oversegmentation on non-2D-based methods. A clear pipeline is provided for end-users to build the pre-trained model to any labeled dataset.
Zipper: A Multi-Tower Decoder Architecture for Fusing Modalities
May 29, 2024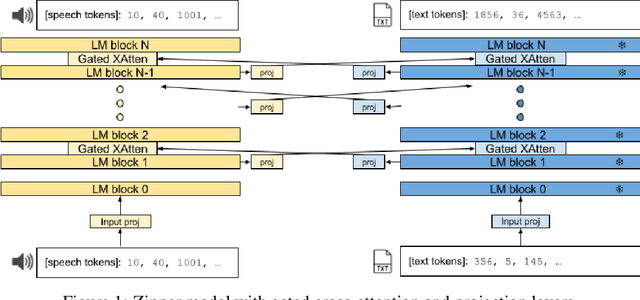


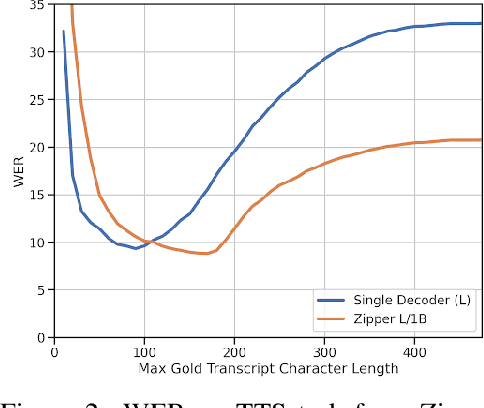
Integrating multiple generative foundation models, especially those trained on different modalities, into something greater than the sum of its parts poses significant challenges. Two key hurdles are the availability of aligned data (concepts that contain similar meaning but is expressed differently in different modalities), and effectively leveraging unimodal representations in cross-domain generative tasks, without compromising their original unimodal capabilities. We propose Zipper, a multi-tower decoder architecture that addresses these concerns by using cross-attention to flexibly compose multimodal generative models from independently pre-trained unimodal decoders. In our experiments fusing speech and text modalities, we show the proposed architecture performs very competitively in scenarios with limited aligned text-speech data. We also showcase the flexibility of our model to selectively maintain unimodal (e.g., text-to-text generation) generation performance by freezing the corresponding modal tower (e.g. text). In cross-modal tasks such as automatic speech recognition (ASR) where the output modality is text, we show that freezing the text backbone results in negligible performance degradation. In cross-modal tasks such as text-to-speech generation (TTS) where the output modality is speech, we show that using a pre-trained speech backbone results in superior performance to the baseline.
LLMs cannot find reasoning errors, but can correct them!
Nov 14, 2023



While self-correction has shown promise in improving LLM outputs in terms of style and quality (e.g. Chen et al., 2023; Madaan et al., 2023), recent attempts to self-correct logical or reasoning errors often cause correct answers to become incorrect, resulting in worse performances overall (Huang et al., 2023). In this paper, we break down the self-correction process into two core components: mistake finding and output correction. For mistake finding, we release BIG-Bench Mistake, a dataset of logical mistakes in Chain-of-Thought reasoning traces. We provide benchmark numbers for several state-of-the-art LLMs, and demonstrate that LLMs generally struggle with finding logical mistakes. For output correction, we propose a backtracking method which provides large improvements when given information on mistake location. We construe backtracking as a lightweight alternative to reinforcement learning methods, and show that it remains effective with a reward model at 60-70% accuracy.