 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs get help from other LLMs without revealing private information?
Apr 02, 2024
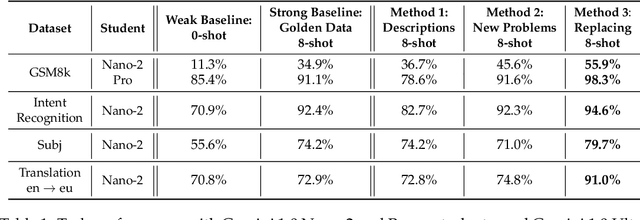


Cascades are a common type of machine learning systems in which a large, remote model can be queried if a local model is not able to accurately label a user's data by itself. Serving stacks for large language models (LLMs) increasingly use cascades due to their ability to preserve task performance while dramatically reducing inference costs. However, applying cascade systems in situations where the local model has access to sensitive data constitutes a significant privacy risk for users since such data could be forwarded to the remote model. In this work, we show the feasibility of applying cascade systems in such setups by equipping the local model with privacy-preserving techniques that reduce the risk of leaking private information when querying the remote model. To quantify information leakage in such setups, we introduce two privacy measures. We then propose a system that leverages the recently introduced social learning paradigm in which LLMs collaboratively learn from each other by exchanging natural language. Using this paradigm, we demonstrate on several datasets that our methods minimize the privacy loss while at the same time improving task performance compared to a non-cascade baseline.
ScreenAI: A Vision-Language Model for UI and Infographics Understanding
Feb 19, 2024



Screen user interfaces (UIs) and infographics, sharing similar visual language and design principles, play important roles in human communication and human-machine interaction. We introduce ScreenAI, a vision-language model that specializes in UI and infographics understanding. Our model improves upon the PaLI architecture with the flexible patching strategy of pix2struct and is trained on a unique mixture of datasets. At the heart of this mixture is a novel screen annotation task in which the model has to identify the type and location of UI elements. We use these text annotations to describe screens to Large Language Models and automatically generate question-answering (QA), UI navigation, and summarization training datasets at scale. We run ablation studies to demonstrate the impact of these design choices. At only 5B parameters, ScreenAI achieves new state-of-the-artresults on UI- and infographics-based tasks (Multi-page DocVQA, WebSRC, MoTIF and Widget Captioning), and new best-in-class performance on others (Chart QA, DocVQA, and InfographicVQA) compared to models of similar size. Finally, we release three new datasets: one focused on the screen annotation task and two others focused on question answering.
LLMs cannot find reasoning errors, but can correct them!
Nov 14, 2023



While self-correction has shown promise in improving LLM outputs in terms of style and quality (e.g. Chen et al., 2023; Madaan et al., 2023), recent attempts to self-correct logical or reasoning errors often cause correct answers to become incorrect, resulting in worse performances overall (Huang et al., 2023). In this paper, we break down the self-correction process into two core components: mistake finding and output correction. For mistake finding, we release BIG-Bench Mistake, a dataset of logical mistakes in Chain-of-Thought reasoning traces. We provide benchmark numbers for several state-of-the-art LLMs, and demonstrate that LLMs generally struggle with finding logical mistakes. For output correction, we propose a backtracking method which provides large improvements when given information on mistake location. We construe backtracking as a lightweight alternative to reinforcement learning methods, and show that it remains effective with a reward model at 60-70% accuracy.
Replacing Human Audio with Synthetic Audio for On-device Unspoken Punctuation Prediction
Oct 20, 2020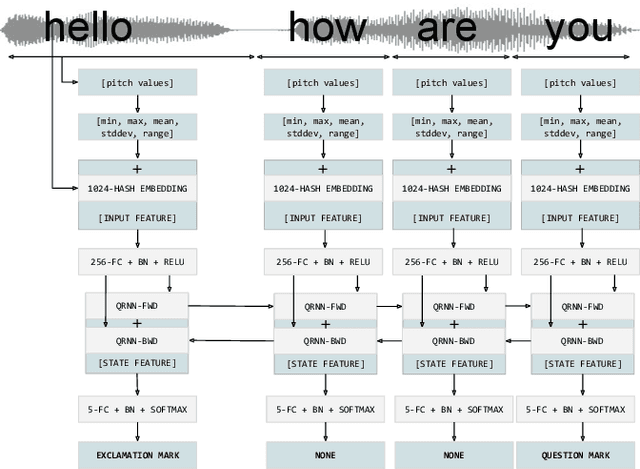

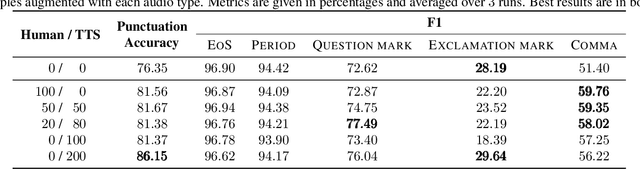

We present a novel multi-modal unspoken punctuation prediction system for the English language which combines acoustic and text features. We demonstrate for the first time, that by relying exclusively on synthetic data generated using a prosody-aware text-to-speech system, we can outperform a model trained with expensive human audio recordings on the unspoken punctuation prediction problem. Our model architecture is well suited for on-device use. This is achieved by leveraging hash-based embeddings of automatic speech recognition text output in conjunction with acoustic features as input to a quasi-recurrent neural network, keeping the model size small and latency low.