 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplacing Human Audio with Synthetic Audio for On-device Unspoken Punctuation Prediction
Oct 20, 2020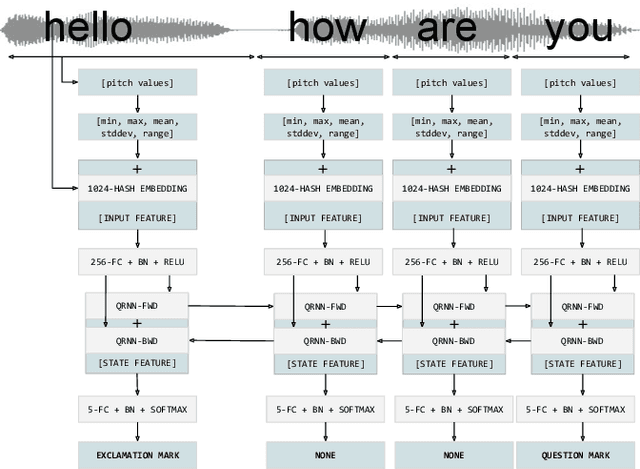

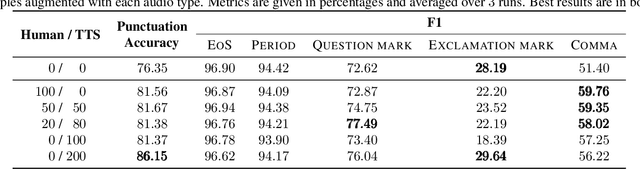

We present a novel multi-modal unspoken punctuation prediction system for the English language which combines acoustic and text features. We demonstrate for the first time, that by relying exclusively on synthetic data generated using a prosody-aware text-to-speech system, we can outperform a model trained with expensive human audio recordings on the unspoken punctuation prediction problem. Our model architecture is well suited for on-device use. This is achieved by leveraging hash-based embeddings of automatic speech recognition text output in conjunction with acoustic features as input to a quasi-recurrent neural network, keeping the model size small and latency low.
Insertion-Deletion Transformer
Jan 15, 2020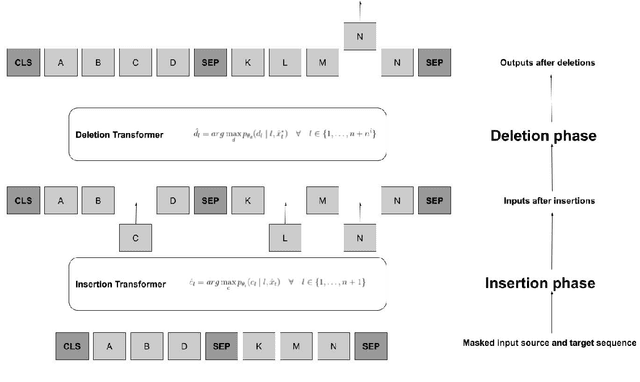



We propose the Insertion-Deletion Transformer, a novel transformer-based neural architecture and training method for sequence generation. The model consists of two phases that are executed iteratively, 1) an insertion phase and 2) a deletion phase. The insertion phase parameterizes a distribution of insertions on the current output hypothesis, while the deletion phase parameterizes a distribution of deletions over the current output hypothesis. The training method is a principled and simple algorithm, where the deletion model obtains its signal directly on-policy from the insertion model output. We demonstrate the effectiveness of our Insertion-Deletion Transformer on synthetic translation tasks, obtaining significant BLEU score improvement over an insertion-only model.