 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligner-Encoders: Self-Attention Transformers Can Be Self-Transducers
Feb 06, 2025



Modern systems for automatic speech recognition, including the RNN-Transducer and Attention-based Encoder-Decoder (AED), are designed so that the encoder is not required to alter the time-position of information from the audio sequence into the embedding; alignment to the final text output is processed during decoding. We discover that the transformer-based encoder adopted in recent years is actually capable of performing the alignment internally during the forward pass, prior to decoding. This new phenomenon enables a simpler and more efficient model, the "Aligner-Encoder". To train it, we discard the dynamic programming of RNN-T in favor of the frame-wise cross-entropy loss of AED, while the decoder employs the lighter text-only recurrence of RNN-T without learned cross-attention -- it simply scans embedding frames in order from the beginning, producing one token each until predicting the end-of-message. We conduct experiments demonstrating performance remarkably close to the state of the art, including a special inference configuration enabling long-form recognition. In a representative comparison, we measure the total inference time for our model to be 2x faster than RNN-T and 16x faster than AED. Lastly, we find that the audio-text alignment is clearly visible in the self-attention weights of a certain layer, which could be said to perform "self-transduction".
Text Injection for Neural Contextual Biasing
Jun 05, 2024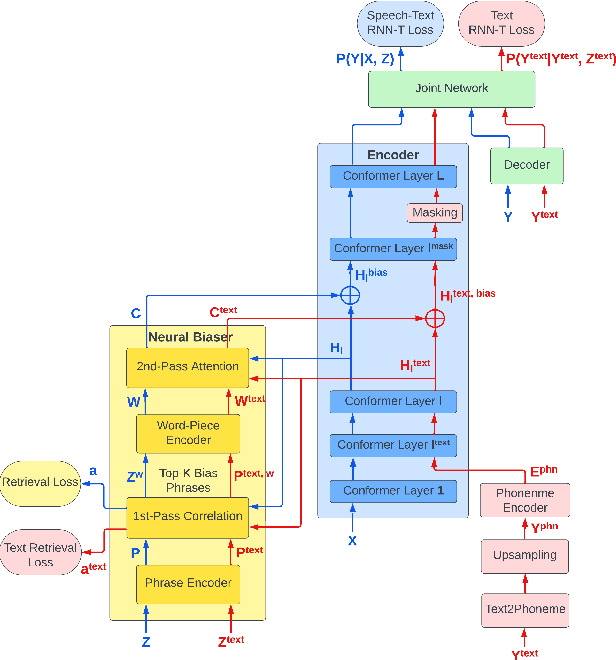
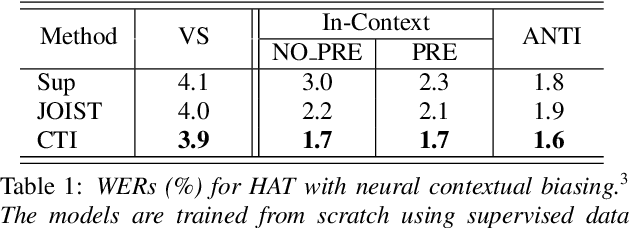
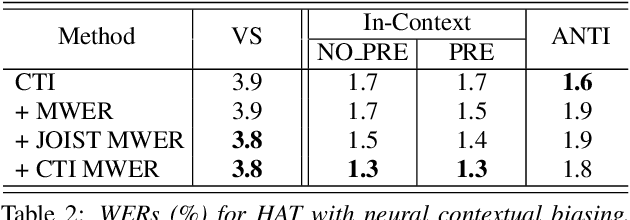
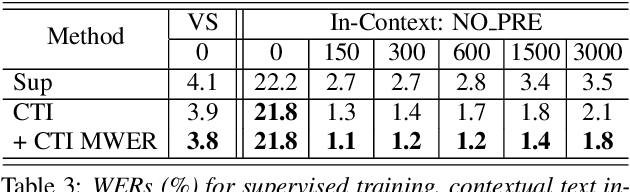
Neural contextual biasing effectively improves automatic speech recognition (ASR) for crucial phrases within a speaker's context, particularly those that are infrequent in the training data. This work proposes contextual text injection (CTI) to enhance contextual ASR. CTI leverages not only the paired speech-text data, but also a much larger corpus of unpaired text to optimize the ASR model and its biasing component. Unpaired text is converted into speech-like representations and used to guide the model's attention towards relevant bias phrases. Moreover, we introduce a contextual text-injected (CTI) minimum word error rate (MWER) training, which minimizes the expected WER caused by contextual biasing when unpaired text is injected into the model. Experiments show that CTI with 100 billion text sentences can achieve up to 43.3% relative WER reduction from a strong neural biasing model. CTI-MWER provides a further relative improvement of 23.5%.
* 5 pages, 1 figure
Efficiently Train ASR Models that Memorize Less and Perform Better with Per-core Clipping
Jun 04, 2024Gradient clipping plays a vital role in training large-scale automatic speech recognition (ASR) models. It is typically applied to minibatch gradients to prevent gradient explosion, and to the individual sample gradients to mitigate unintended memorization. This work systematically investigates the impact of a specific granularity of gradient clipping, namely per-core clip-ping (PCC), across training a wide range of ASR models. We empirically demonstrate that PCC can effectively mitigate unintended memorization in ASR models. Surprisingly, we find that PCC positively influences ASR performance metrics, leading to improved convergence rates and reduced word error rates. To avoid tuning the additional hyperparameter introduced by PCC, we further propose a novel variant, adaptive per-core clipping (APCC), for streamlined optimization. Our findings highlight the multifaceted benefits of PCC as a strategy for robust, privacy-forward ASR model training.
Deferred NAM: Low-latency Top-K Context Injection via DeferredContext Encoding for Non-Streaming ASR
Apr 15, 2024



Contextual biasing enables speech recognizers to transcribe important phrases in the speaker's context, such as contact names, even if they are rare in, or absent from, the training data. Attention-based biasing is a leading approach which allows for full end-to-end cotraining of the recognizer and biasing system and requires no separate inference-time components. Such biasers typically consist of a context encoder; followed by a context filter which narrows down the context to apply, improving per-step inference time; and, finally, context application via cross attention. Though much work has gone into optimizing per-frame performance, the context encoder is at least as important: recognition cannot begin before context encoding ends. Here, we show the lightweight phrase selection pass can be moved before context encoding, resulting in a speedup of up to 16.1 times and enabling biasing to scale to 20K phrases with a maximum pre-decoding delay under 33ms. With the addition of phrase- and wordpiece-level cross-entropy losses, our technique also achieves up to a 37.5% relative WER reduction over the baseline without the losses and lightweight phrase selection pass.
* 9 pages, 3 figures, accepted by NAACL 2024 - Industry Track
Extreme Encoder Output Frame Rate Reduction: Improving Computational Latencies of Large End-to-End Models
Feb 27, 2024The accuracy of end-to-end (E2E) automatic speech recognition (ASR) models continues to improve as they are scaled to larger sizes, with some now reaching billions of parameters. Widespread deployment and adoption of these models, however, requires computationally efficient strategies for decoding. In the present work, we study one such strategy: applying multiple frame reduction layers in the encoder to compress encoder outputs into a small number of output frames. While similar techniques have been investigated in previous work, we achieve dramatically more reduction than has previously been demonstrated through the use of multiple funnel reduction layers. Through ablations, we study the impact of various architectural choices in the encoder to identify the most effective strategies. We demonstrate that we can generate one encoder output frame for every 2.56 sec of input speech, without significantly affecting word error rate on a large-scale voice search task, while improving encoder and decoder latencies by 48% and 92% respectively, relative to a strong but computationally expensive baseline.
USM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Jan 03, 2024End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
Improved Long-Form Speech Recognition by Jointly Modeling the Primary and Non-primary Speakers
Dec 18, 2023ASR models often suffer from a long-form deletion problem where the model predicts sequential blanks instead of words when transcribing a lengthy audio (in the order of minutes or hours). From the perspective of a user or downstream system consuming the ASR results, this behavior can be perceived as the model "being stuck", and potentially make the product hard to use. One of the culprits for long-form deletion is training-test data mismatch, which can happen even when the model is trained on diverse and large-scale data collected from multiple application domains. In this work, we introduce a novel technique to simultaneously model different groups of speakers in the audio along with the standard transcript tokens. Speakers are grouped as primary and non-primary, which connects the application domains and significantly alleviates the long-form deletion problem. This improved model neither needs any additional training data nor incurs additional training or inference cost.
Contextual Biasing with the Knuth-Morris-Pratt Matching Algorithm
Sep 29, 2023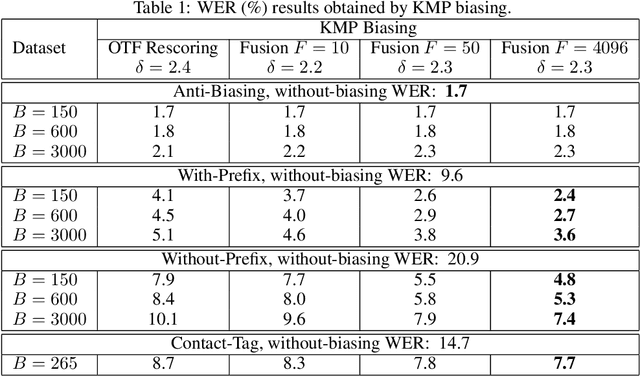
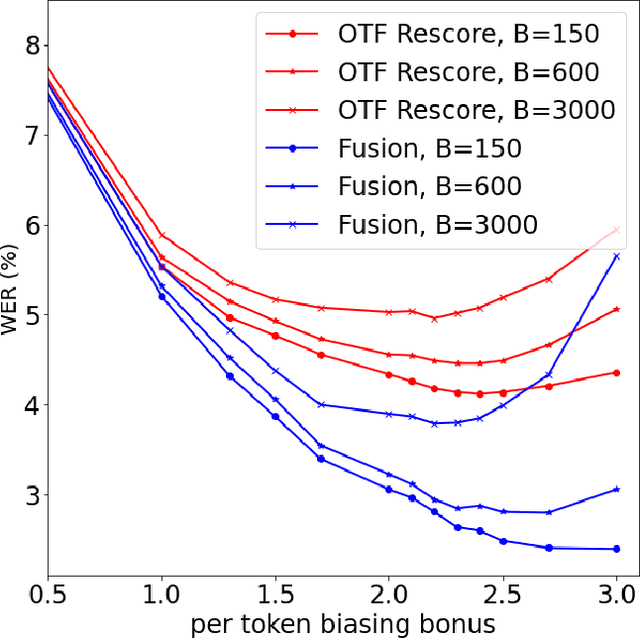
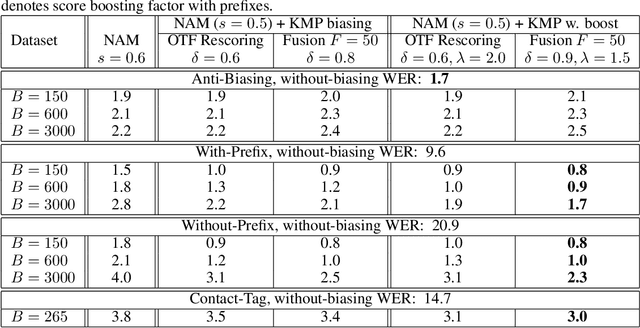
Contextual biasing refers to the problem of biasing the automatic speech recognition (ASR) systems towards rare entities that are relevant to the specific user or application scenarios. We propose algorithms for contextual biasing based on the Knuth-Morris-Pratt algorithm for pattern matching. During beam search, we boost the score of a token extension if it extends matching into a set of biasing phrases. Our method simulates the classical approaches often implemented in the weighted finite state transducer (WFST) framework, but avoids the FST language altogether, with careful considerations on memory footprint and efficiency on tensor processing units (TPUs) by vectorization. Without introducing additional model parameters, our method achieves significant word error rate (WER) reductions on biasing test sets by itself, and yields further performance gain when combined with a model-based biasing method.
The Gift of Feedback: Improving ASR Model Quality by Learning from User Corrections through Federated Learning
Sep 29, 2023Automatic speech recognition (ASR) models are typically trained on large datasets of transcribed speech. As language evolves and new terms come into use, these models can become outdated and stale. In the context of models trained on the server but deployed on edge devices, errors may result from the mismatch between server training data and actual on-device usage. In this work, we seek to continually learn from on-device user corrections through Federated Learning (FL) to address this issue. We explore techniques to target fresh terms that the model has not previously encountered, learn long-tail words, and mitigate catastrophic forgetting. In experimental evaluations, we find that the proposed techniques improve model recognition of fresh terms, while preserving quality on the overall language distribution.
Massive End-to-end Models for Short Search Queries
Sep 22, 2023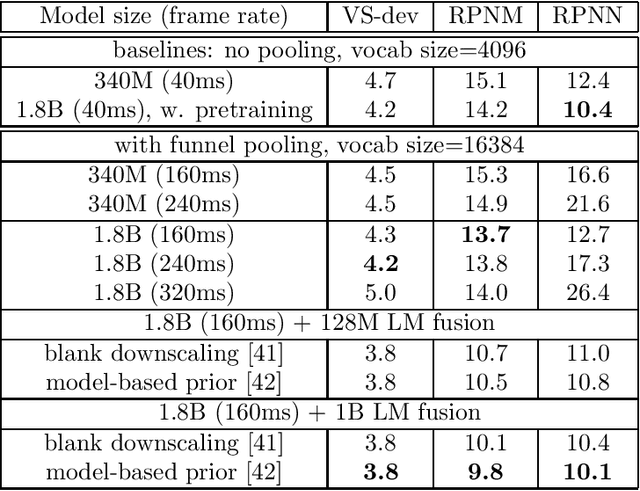
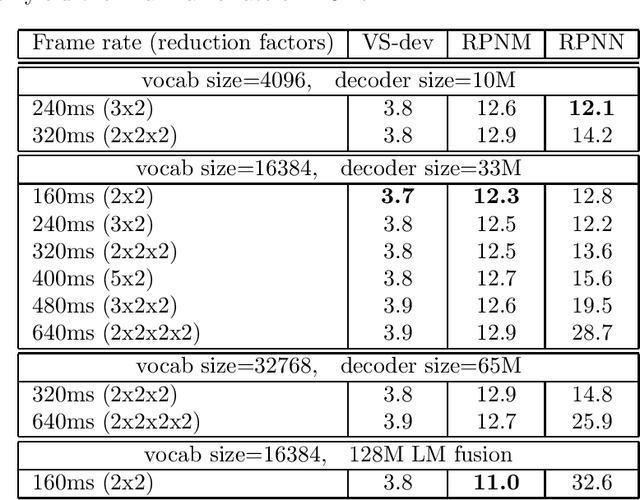
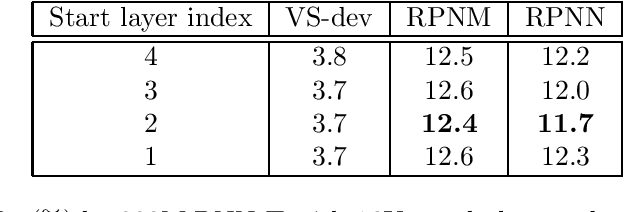
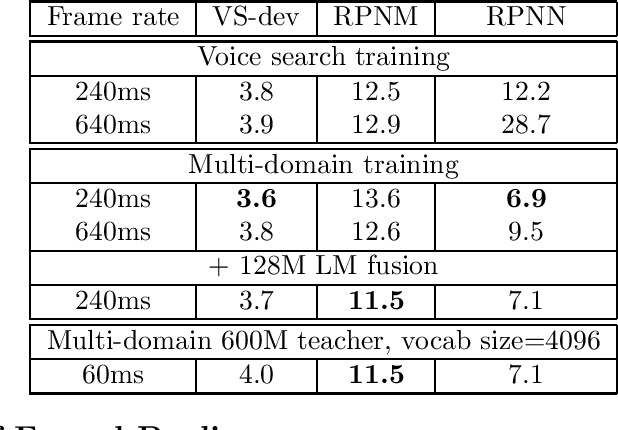
In this work, we investigate two popular end-to-end automatic speech recognition (ASR) models, namely Connectionist Temporal Classification (CTC) and RNN-Transducer (RNN-T), for offline recognition of voice search queries, with up to 2B model parameters. The encoders of our models use the neural architecture of Google's universal speech model (USM), with additional funnel pooling layers to significantly reduce the frame rate and speed up training and inference. We perform extensive studies on vocabulary size, time reduction strategy, and its generalization performance on long-form test sets. Despite the speculation that, as the model size increases, CTC can be as good as RNN-T which builds label dependency into the prediction, we observe that a 900M RNN-T clearly outperforms a 1.8B CTC and is more tolerant to severe time reduction, although the WER gap can be largely removed by LM shallow fusion.