 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning of Large ASR Models in the Real World
Aug 19, 2024Federated learning (FL) has shown promising results on training machine learning models with privacy preservation. However, for large models with over 100 million parameters, the training resource requirement becomes an obstacle for FL because common devices do not have enough memory and computation power to finish the FL tasks. Although efficient training methods have been proposed, it is still a challenge to train the large models like Conformer based ASR. This paper presents a systematic solution to train the full-size ASR models of 130M parameters with FL. To our knowledge, this is the first real-world FL application of the Conformer model, which is also the largest model ever trained with FL so far. And this is the first paper showing FL can improve the ASR model quality with a set of proposed methods to refine the quality of data and labels of clients. We demonstrate both the training efficiency and the model quality improvement in real-world experiments.
A Multimodal In-Context Tuning Approach for E-Commerce Product Description Generation
Feb 21, 2024In this paper, we propose a new setting for generating product descriptions from images, augmented by marketing keywords. It leverages the combined power of visual and textual information to create descriptions that are more tailored to the unique features of products. For this setting, previous methods utilize visual and textual encoders to encode the image and keywords and employ a language model-based decoder to generate the product description. However, the generated description is often inaccurate and generic since same-category products have similar copy-writings, and optimizing the overall framework on large-scale samples makes models concentrate on common words yet ignore the product features. To alleviate the issue, we present a simple and effective Multimodal In-Context Tuning approach, named ModICT, which introduces a similar product sample as the reference and utilizes the in-context learning capability of language models to produce the description. During training, we keep the visual encoder and language model frozen, focusing on optimizing the modules responsible for creating multimodal in-context references and dynamic prompts. This approach preserves the language generation prowess of large language models (LLMs), facilitating a substantial increase in description diversity. To assess the effectiveness of ModICT across various language model scales and types, we collect data from three distinct product categories within the E-commerce domain. Extensive experiments demonstrate that ModICT significantly improves the accuracy (by up to 3.3% on Rouge-L) and diversity (by up to 9.4% on D-5) of generated results compared to conventional methods. Our findings underscore the potential of ModICT as a valuable tool for enhancing automatic generation of product descriptions in a wide range of applications.
The Gift of Feedback: Improving ASR Model Quality by Learning from User Corrections through Federated Learning
Sep 29, 2023Automatic speech recognition (ASR) models are typically trained on large datasets of transcribed speech. As language evolves and new terms come into use, these models can become outdated and stale. In the context of models trained on the server but deployed on edge devices, errors may result from the mismatch between server training data and actual on-device usage. In this work, we seek to continually learn from on-device user corrections through Federated Learning (FL) to address this issue. We explore techniques to target fresh terms that the model has not previously encountered, learn long-tail words, and mitigate catastrophic forgetting. In experimental evaluations, we find that the proposed techniques improve model recognition of fresh terms, while preserving quality on the overall language distribution.
A Multi-Modal Context Reasoning Approach for Conditional Inference on Joint Textual and Visual Clues
May 08, 2023Conditional inference on joint textual and visual clues is a multi-modal reasoning task that textual clues provide prior permutation or external knowledge, which are complementary with visual content and pivotal to deducing the correct option. Previous methods utilizing pretrained vision-language models (VLMs) have achieved impressive performances, yet they show a lack of multimodal context reasoning capability, especially for text-modal information. To address this issue, we propose a Multi-modal Context Reasoning approach, named ModCR. Compared to VLMs performing reasoning via cross modal semantic alignment, it regards the given textual abstract semantic and objective image information as the pre-context information and embeds them into the language model to perform context reasoning. Different from recent vision-aided language models used in natural language processing, ModCR incorporates the multi-view semantic alignment information between language and vision by introducing the learnable alignment prefix between image and text in the pretrained language model. This makes the language model well-suitable for such multi-modal reasoning scenario on joint textual and visual clues. We conduct extensive experiments on two corresponding data sets and experimental results show significantly improved performance (exact gain by 4.8% on PMR test set) compared to previous strong baselines. Code Link: \url{https://github.com/YunxinLi/Multimodal-Context-Reasoning}.
A Neural Divide-and-Conquer Reasoning Framework for Image Retrieval from Linguistically Complex Text
May 05, 2023Pretrained Vision-Language Models (VLMs) have achieved remarkable performance in image retrieval from text. However, their performance drops drastically when confronted with linguistically complex texts that they struggle to comprehend. Inspired by the Divide-and-Conquer algorithm and dual-process theory, in this paper, we regard linguistically complex texts as compound proposition texts composed of multiple simple proposition sentences and propose an end-to-end Neural Divide-and-Conquer Reasoning framework, dubbed NDCR. It contains three main components: 1) Divide: a proposition generator divides the compound proposition text into simple proposition sentences and produces their corresponding representations, 2) Conquer: a pretrained VLMs-based visual-linguistic interactor achieves the interaction between decomposed proposition sentences and images, 3) Combine: a neural-symbolic reasoner combines the above reasoning states to obtain the final solution via a neural logic reasoning approach. According to the dual-process theory, the visual-linguistic interactor and neural-symbolic reasoner could be regarded as analogical reasoning System 1 and logical reasoning System 2. We conduct extensive experiments on a challenging image retrieval from contextual descriptions data set. Experimental results and analyses indicate NDCR significantly improves performance in the complex image-text reasoning problem. Code link: https://github.com/YunxinLi/NDCR.
Medical Dialogue Response Generation with Pivotal Information Recalling
Jun 17, 2022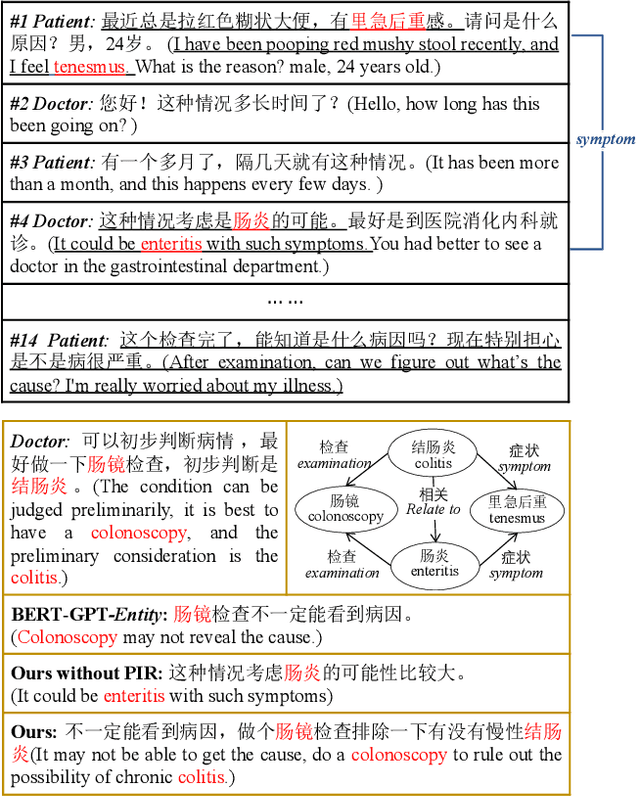
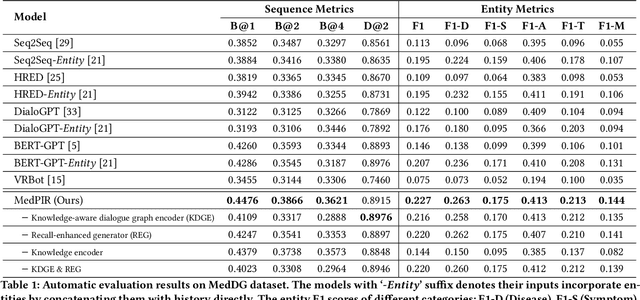

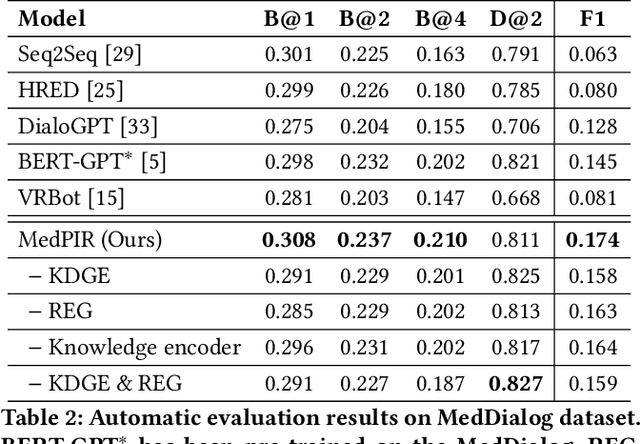
Medical dialogue generation is an important yet challenging task. Most previous works rely on the attention mechanism and large-scale pretrained language models. However, these methods often fail to acquire pivotal information from the long dialogue history to yield an accurate and informative response, due to the fact that the medical entities usually scatters throughout multiple utterances along with the complex relationships between them. To mitigate this problem, we propose a medical response generation model with Pivotal Information Recalling (MedPIR), which is built on two components, i.e., knowledge-aware dialogue graph encoder and recall-enhanced generator. The knowledge-aware dialogue graph encoder constructs a dialogue graph by exploiting the knowledge relationships between entities in the utterances, and encodes it with a graph attention network. Then, the recall-enhanced generator strengthens the usage of these pivotal information by generating a summary of the dialogue before producing the actual response. Experimental results on two large-scale medical dialogue datasets show that MedPIR outperforms the strong baselines in BLEU scores and medical entities F1 measure.
GlyphCRM: Bidirectional Encoder Representation for Chinese Character with its Glyph
Jul 01, 2021
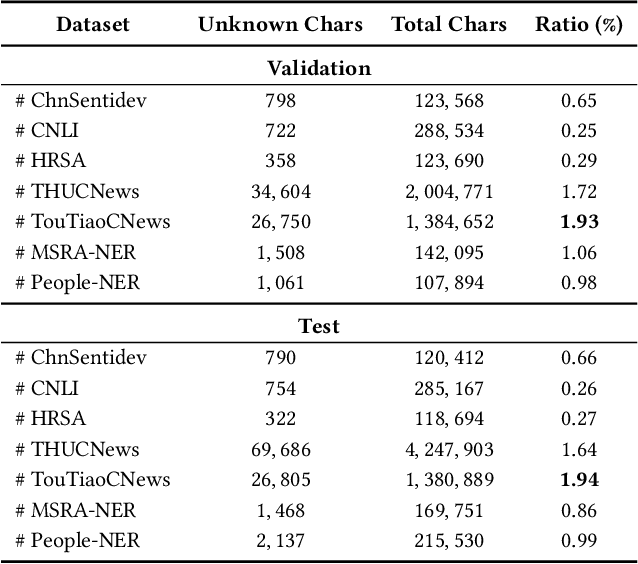
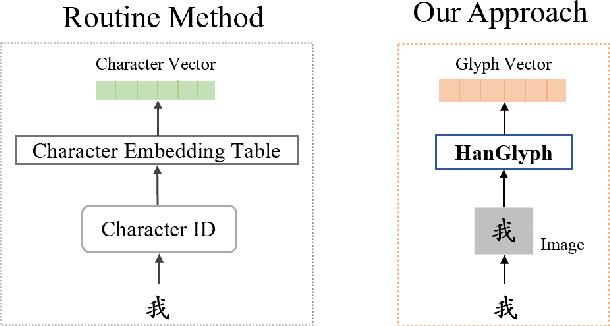
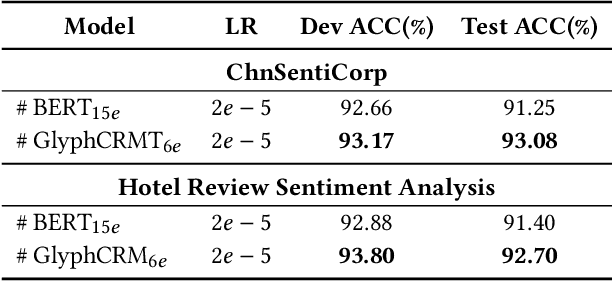
Previous works indicate that the glyph of Chinese characters contains rich semantic information and has the potential to enhance the representation of Chinese characters. The typical method to utilize the glyph features is by incorporating them into the character embedding space. Inspired by previous methods, we innovatively propose a Chinese pre-trained representation model named as GlyphCRM, which abandons the ID-based character embedding method yet solely based on sequential character images. We render each character into a binary grayscale image and design two-channel position feature maps for it. Formally, we first design a two-layer residual convolutional neural network, namely HanGlyph to generate the initial glyph representation of Chinese characters, and subsequently adopt multiple bidirectional encoder Transformer blocks as the superstructure to capture the context-sensitive information. Meanwhile, we feed the glyph features extracted from each layer of the HanGlyph module into the underlying Transformer blocks by skip-connection method to fully exploit the glyph features of Chinese characters. As the HanGlyph module can obtain a sufficient glyph representation of any Chinese character, the long-standing out-of-vocabulary problem could be effectively solved. Extensive experimental results indicate that GlyphCRM substantially outperforms the previous BERT-based state-of-the-art model on 9 fine-tuning tasks, and it has strong transferability and generalization on specialized fields and low-resource tasks. We hope this work could spark further research beyond the realms of well-established representation of Chinese texts.