 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIDE: AI-Driven Exploration in the Space of Code
Feb 18, 2025Machine learning, the foundation of modern artificial intelligence, has driven innovations that have fundamentally transformed the world. Yet, behind advancements lies a complex and often tedious process requiring labor and compute intensive iteration and experimentation. Engineers and scientists developing machine learning models spend much of their time on trial-and-error tasks instead of conceptualizing innovative solutions or research hypotheses. To address this challenge, we introduce AI-Driven Exploration (AIDE), a machine learning engineering agent powered by large language models (LLMs). AIDE frames machine learning engineering as a code optimization problem, and formulates trial-and-error as a tree search in the space of potential solutions. By strategically reusing and refining promising solutions, AIDE effectively trades computational resources for enhanced performance, achieving state-of-the-art results on multiple machine learning engineering benchmarks, including our Kaggle evaluations, OpenAI MLE-Bench and METRs RE-Bench.
Analysing The Impact of Sequence Composition on Language Model Pre-Training
Feb 21, 2024



Most language model pre-training frameworks concatenate multiple documents into fixed-length sequences and use causal masking to compute the likelihood of each token given its context; this strategy is widely adopted due to its simplicity and efficiency. However, to this day, the influence of the pre-training sequence composition strategy on the generalisation properties of the model remains under-explored. In this work, we find that applying causal masking can lead to the inclusion of distracting information from previous documents during pre-training, which negatively impacts the performance of the models on language modelling and downstream tasks. In intra-document causal masking, the likelihood of each token is only conditioned on the previous tokens in the same document, eliminating potential distracting information from previous documents and significantly improving performance. Furthermore, we find that concatenating related documents can reduce some potential distractions during pre-training, and our proposed efficient retrieval-based sequence construction method, BM25Chunk, can improve in-context learning (+11.6\%), knowledge memorisation (+9.8\%), and context utilisation (+7.2\%) abilities of language models without sacrificing efficiency.
Towards Reasoning in Large Language Models via Multi-Agent Peer Review Collaboration
Nov 14, 2023



Large Language Models (LLMs) have shown remarkable capabilities in general natural language processing tasks but often fall short in complex reasoning tasks. Recent studies have explored human-like problem-solving strategies, such as self-correct, to push further the boundary of single-model reasoning ability. In this work, we let a single model "step outside the box" by engaging multiple models to correct each other. We introduce a multi-agent collaboration strategy that emulates the academic peer review process. Each agent independently constructs its own solution, provides reviews on the solutions of others, and assigns confidence levels to its reviews. Upon receiving peer reviews, agents revise their initial solutions. Extensive experiments on three different types of reasoning tasks show that our collaboration approach delivers superior accuracy across all ten datasets compared to existing methods. Further study demonstrates the effectiveness of integrating confidence in the reviews for math reasoning, and suggests a promising direction for human-mimicking multi-agent collaboration process.
Using Natural Language Explanations to Improve Robustness of In-context Learning for Natural Language Inference
Nov 13, 2023



Recent studies have demonstrated that large language models (LLMs) excel in diverse tasks through in-context learning (ICL) facilitated by task-specific prompts and examples. However, the existing literature shows that ICL encounters performance deterioration when exposed to adversarial inputs. Enhanced performance has been observed when ICL is augmented with natural language explanations (NLEs) (we refer to it as X-ICL). Thus, this work investigates whether X-ICL can improve the robustness of LLMs on a suite of seven adversarial and challenging natural language inference datasets. Moreover, we introduce a new approach to X-ICL by prompting an LLM (ChatGPT in our case) with few human-generated NLEs to produce further NLEs (we call it ChatGPT few-shot), which we show superior to both ChatGPT zero-shot and human-generated NLEs alone. We evaluate five popular LLMs (GPT3.5-turbo, LLaMa2, Vicuna, Zephyr, Mistral) and show that X-ICL with ChatGPT few-shot yields over 6% improvement over ICL. Furthermore, while prompt selection strategies were previously shown to significantly improve ICL on in-distribution test sets, we show that these strategies do not match the efficacy of the X-ICL paradigm in robustness-oriented evaluations.
Semantic Parsing by Large Language Models for Intricate Updating Strategies of Zero-Shot Dialogue State Tracking
Oct 18, 2023Zero-shot Dialogue State Tracking (DST) addresses the challenge of acquiring and annotating task-oriented dialogues, which can be time consuming and costly. However, DST extends beyond simple slot-filling and requires effective updating strategies for tracking dialogue state as conversations progress. In this paper, we propose ParsingDST, a new In-Context Learning (ICL) method, to introduce additional intricate updating strategies in zero-shot DST. Our approach reformulates the DST task by leveraging powerful Large Language Models (LLMs) and translating the original dialogue text to JSON through semantic parsing as an intermediate state. We also design a novel framework that includes more modules to ensure the effectiveness of updating strategies in the text-to-JSON process. Experimental results demonstrate that our approach outperforms existing zero-shot DST methods on MultiWOZ, exhibiting significant improvements in Joint Goal Accuracy (JGA) and slot accuracy compared to existing ICL methods.
G3Detector: General GPT-Generated Text Detector
May 22, 2023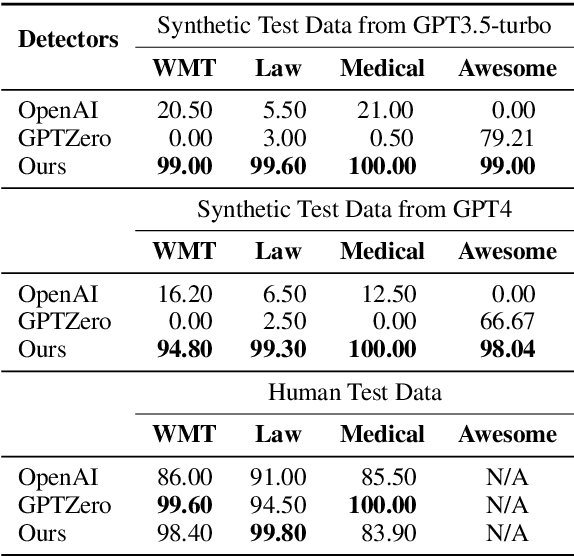
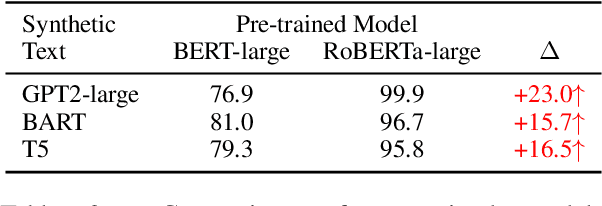
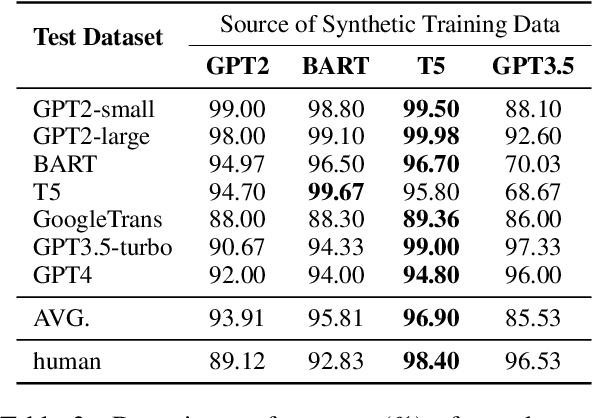
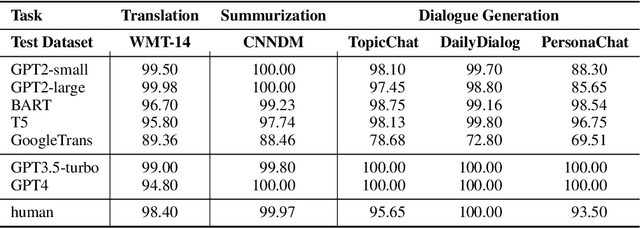
The burgeoning progress in the field of Large Language Models (LLMs) heralds significant benefits due to their unparalleled capacities. However, it is critical to acknowledge the potential misuse of these models, which could give rise to a spectrum of social and ethical dilemmas. Despite numerous preceding efforts centered around distinguishing synthetic text, most existing detection systems fail to identify data synthesized by the latest LLMs, such as ChatGPT and GPT-4. In response to this challenge, we introduce an unpretentious yet potent detection approach proficient in identifying synthetic text across a wide array of fields. Moreover, our detector demonstrates outstanding performance uniformly across various model architectures and decoding strategies. It also possesses the capability to identify text generated utilizing a potent detection-evasion technique. Our comprehensive research underlines our commitment to boosting the robustness and efficiency of machine-generated text detection mechanisms, particularly in the context of swiftly progressing and increasingly adaptive AI technologies.
Revisit Out-Of-Vocabulary Problem for Slot Filling: A Unified Contrastive Frameword with Multi-level Data Augmentations
Feb 27, 2023In real dialogue scenarios, the existing slot filling model, which tends to memorize entity patterns, has a significantly reduced generalization facing Out-of-Vocabulary (OOV) problems. To address this issue, we propose an OOV robust slot filling model based on multi-level data augmentations to solve the OOV problem from both word and slot perspectives. We present a unified contrastive learning framework, which pull representations of the origin sample and augmentation samples together, to make the model resistant to OOV problems. We evaluate the performance of the model from some specific slots and carefully design test data with OOV word perturbation to further demonstrate the effectiveness of OOV words. Experiments on two datasets show that our approach outperforms the previous sota methods in terms of both OOV slots and words.
A Prototypical Semantic Decoupling Method via Joint Contrastive Learning for Few-Shot Name Entity Recognition
Feb 27, 2023



Few-shot named entity recognition (NER) aims at identifying named entities based on only few labeled instances. Most existing prototype-based sequence labeling models tend to memorize entity mentions which would be easily confused by close prototypes. In this paper, we proposed a Prototypical Semantic Decoupling method via joint Contrastive learning (PSDC) for few-shot NER. Specifically, we decouple class-specific prototypes and contextual semantic prototypes by two masking strategies to lead the model to focus on two different semantic information for inference. Besides, we further introduce joint contrastive learning objectives to better integrate two kinds of decoupling information and prevent semantic collapse. Experimental results on two few-shot NER benchmarks demonstrate that PSDC consistently outperforms the previous SOTA methods in terms of overall performance. Extensive analysis further validates the effectiveness and generalization of PSDC.
An Efficient Memory-Augmented Transformer for Knowledge-Intensive NLP Tasks
Oct 30, 2022



Access to external knowledge is essential for many natural language processing tasks, such as question answering and dialogue. Existing methods often rely on a parametric model that stores knowledge in its parameters, or use a retrieval-augmented model that has access to an external knowledge source. Parametric and retrieval-augmented models have complementary strengths in terms of computational efficiency and predictive accuracy. To combine the strength of both approaches, we propose the Efficient Memory-Augmented Transformer (EMAT) -- it encodes external knowledge into a key-value memory and exploits the fast maximum inner product search for memory querying. We also introduce pre-training tasks that allow EMAT to encode informative key-value representations, and to learn an implicit strategy to integrate multiple memory slots into the transformer. Experiments on various knowledge-intensive tasks such as question answering and dialogue datasets show that, simply augmenting parametric models (T5-base) using our method produces more accurate results (e.g., 25.8 -> 44.3 EM on NQ) while retaining a high throughput (e.g., 1000 queries/s on NQ). Compared to retrieval-augmented models, EMAT runs substantially faster across the board and produces more accurate results on WoW and ELI5. Our code and datasets are available at https://github. com/uclnlp/EMAT.
Medical Dialogue Response Generation with Pivotal Information Recalling
Jun 17, 2022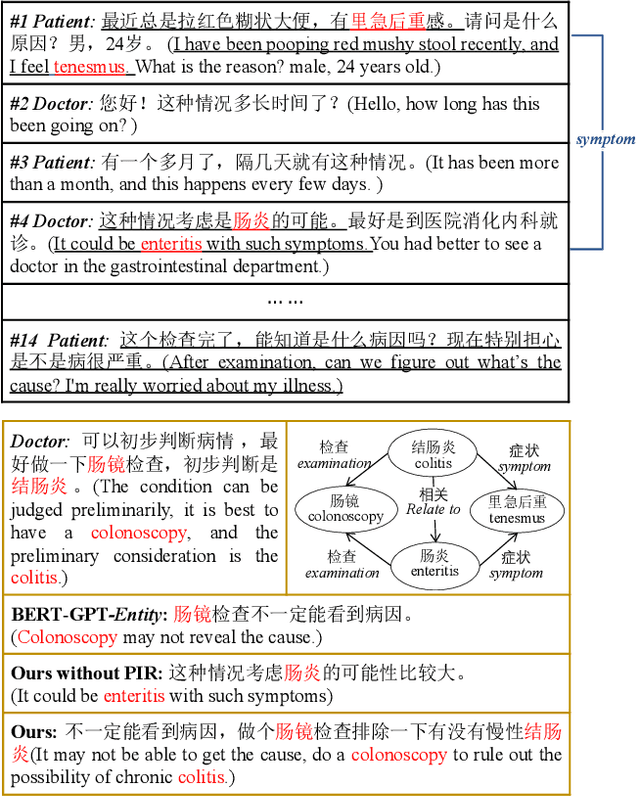
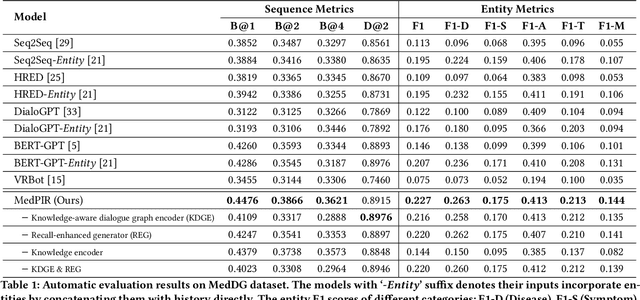

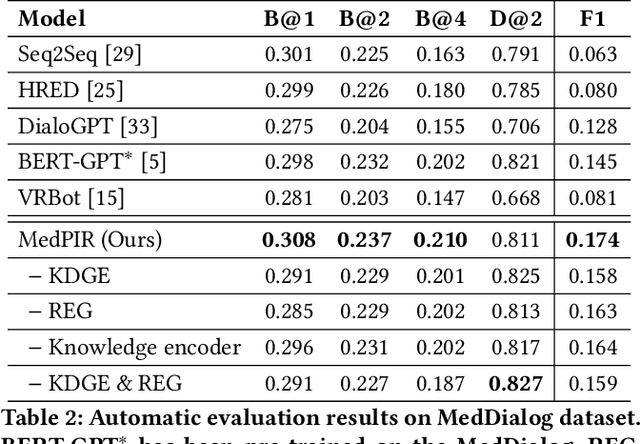
Medical dialogue generation is an important yet challenging task. Most previous works rely on the attention mechanism and large-scale pretrained language models. However, these methods often fail to acquire pivotal information from the long dialogue history to yield an accurate and informative response, due to the fact that the medical entities usually scatters throughout multiple utterances along with the complex relationships between them. To mitigate this problem, we propose a medical response generation model with Pivotal Information Recalling (MedPIR), which is built on two components, i.e., knowledge-aware dialogue graph encoder and recall-enhanced generator. The knowledge-aware dialogue graph encoder constructs a dialogue graph by exploiting the knowledge relationships between entities in the utterances, and encodes it with a graph attention network. Then, the recall-enhanced generator strengthens the usage of these pivotal information by generating a summary of the dialogue before producing the actual response. Experimental results on two large-scale medical dialogue datasets show that MedPIR outperforms the strong baselines in BLEU scores and medical entities F1 measure.