 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing The Impact of Sequence Composition on Language Model Pre-Training
Feb 21, 2024



Most language model pre-training frameworks concatenate multiple documents into fixed-length sequences and use causal masking to compute the likelihood of each token given its context; this strategy is widely adopted due to its simplicity and efficiency. However, to this day, the influence of the pre-training sequence composition strategy on the generalisation properties of the model remains under-explored. In this work, we find that applying causal masking can lead to the inclusion of distracting information from previous documents during pre-training, which negatively impacts the performance of the models on language modelling and downstream tasks. In intra-document causal masking, the likelihood of each token is only conditioned on the previous tokens in the same document, eliminating potential distracting information from previous documents and significantly improving performance. Furthermore, we find that concatenating related documents can reduce some potential distractions during pre-training, and our proposed efficient retrieval-based sequence construction method, BM25Chunk, can improve in-context learning (+11.6\%), knowledge memorisation (+9.8\%), and context utilisation (+7.2\%) abilities of language models without sacrificing efficiency.
Structured Packing in LLM Training Improves Long Context Utilization
Jan 02, 2024Recent advances in long-context Large Language Models (LCLMs) have generated significant interest, especially in applications such as querying scientific research papers. However, their potential is often limited by inadequate context utilization. We identify the absence of long-range semantic dependencies in typical training data as a primary hindrance. To address this, we delve into the benefits of frequently incorporating related documents into training inputs. Using the inherent directory structure of code data as a source of training examples, we demonstrate improvements in perplexity, even for tasks unrelated to coding. Building on these findings, but with a broader focus, we introduce Structured Packing for Long Context (SPLiCe). SPLiCe is an innovative method for creating training examples by using a retrieval method to collate the most mutually relevant documents into a single training context. Our results indicate that \method{} enhances model performance and can be used to train large models to utilize long contexts better. We validate our results by training a large $3$B model, showing both perplexity improvements and better long-context performance on downstream tasks.
Explaining Competitive-Level Programming Solutions using LLMs
Jul 11, 2023



In this paper, we approach competitive-level programming problem-solving as a composite task of reasoning and code generation. We propose a novel method to automatically annotate natural language explanations to \textit{<problem, solution>} pairs. We show that despite poor performance in solving competitive-level programming problems, state-of-the-art LLMs exhibit a strong capacity in describing and explaining solutions. Our explanation generation methodology can generate a structured solution explanation for the problem containing descriptions and analysis. To evaluate the quality of the annotated explanations, we examine their effectiveness in two aspects: 1) satisfying the human programming expert who authored the oracle solution, and 2) aiding LLMs in solving problems more effectively. The experimental results on the CodeContests dataset demonstrate that while LLM GPT3.5's and GPT-4's abilities in describing the solution are comparable, GPT-4 shows a better understanding of the key idea behind the solution.
Focused Transformer: Contrastive Training for Context Scaling
Jul 06, 2023Large language models have an exceptional capability to incorporate new information in a contextual manner. However, the full potential of such an approach is often restrained due to a limitation in the effective context length. One solution to this issue is to endow an attention layer with access to an external memory, which comprises of (key, value) pairs. Yet, as the number of documents increases, the proportion of relevant keys to irrelevant ones decreases, leading the model to focus more on the irrelevant keys. We identify a significant challenge, dubbed the distraction issue, where keys linked to different semantic values might overlap, making them hard to distinguish. To tackle this problem, we introduce the Focused Transformer (FoT), a technique that employs a training process inspired by contrastive learning. This novel approach enhances the structure of the (key, value) space, enabling an extension of the context length. Our method allows for fine-tuning pre-existing, large-scale models to lengthen their effective context. This is demonstrated by our fine-tuning of $3B$ and $7B$ OpenLLaMA checkpoints. The resulting models, which we name LongLLaMA, exhibit advancements in tasks requiring a long context. We further illustrate that our LongLLaMA models adeptly manage a $256 k$ context length for passkey retrieval.
Magnushammer: A Transformer-based Approach to Premise Selection
Mar 08, 2023Premise selection is a fundamental problem of automated theorem proving. Previous works often use intricate symbolic methods, rely on domain knowledge, and require significant engineering effort to solve this task. In this work, we show that Magnushammer, a neural transformer-based approach, can outperform traditional symbolic systems by a large margin. Tested on the PISA benchmark, Magnushammer achieves $59.5\%$ proof rate compared to a $38.3\%$ proof rate of Sledgehammer, the most mature and popular symbolic-based solver. Furthermore, by combining Magnushammer with a neural formal prover based on a language model, we significantly improve the previous state-of-the-art proof rate from $57.0\%$ to $71.0\%$.
Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers
May 22, 2022

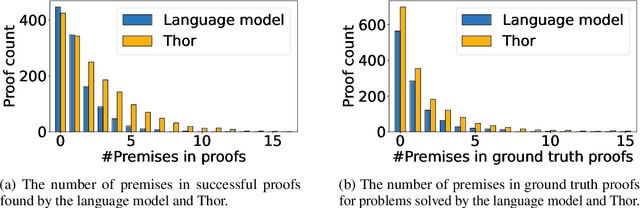

In theorem proving, the task of selecting useful premises from a large library to unlock the proof of a given conjecture is crucially important. This presents a challenge for all theorem provers, especially the ones based on language models, due to their relative inability to reason over huge volumes of premises in text form. This paper introduces Thor, a framework integrating language models and automated theorem provers to overcome this difficulty. In Thor, a class of methods called hammers that leverage the power of automated theorem provers are used for premise selection, while all other tasks are designated to language models. Thor increases a language model's success rate on the PISA dataset from $39\%$ to $57\%$, while solving $8.2\%$ of problems neither language models nor automated theorem provers are able to solve on their own. Furthermore, with a significantly smaller computational budget, Thor can achieve a success rate on the MiniF2F dataset that is on par with the best existing methods. Thor can be instantiated for the majority of popular interactive theorem provers via a straightforward protocol we provide.
Hierarchical Transformers Are More Efficient Language Models
Oct 26, 2021

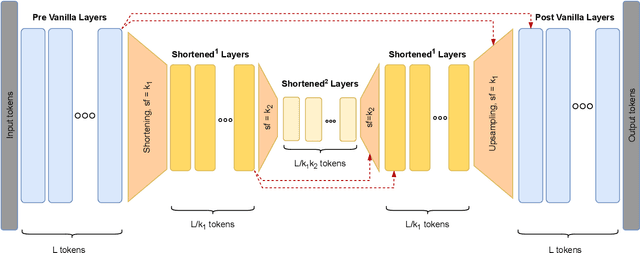

Transformer models yield impressive results on many NLP and sequence modeling tasks. Remarkably, Transformers can handle long sequences which allows them to produce long coherent outputs: full paragraphs produced by GPT-3 or well-structured images produced by DALL-E. These large language models are impressive but also very inefficient and costly, which limits their applications and accessibility. We postulate that having an explicit hierarchical architecture is the key to Transformers that efficiently handle long sequences. To verify this claim, we first study different ways to downsample and upsample activations in Transformers so as to make them hierarchical. We use the best performing upsampling and downsampling layers to create Hourglass - a hierarchical Transformer language model. Hourglass improves upon the Transformer baseline given the same amount of computation and can yield the same results as Transformers more efficiently. In particular, Hourglass sets new state-of-the-art for Transformer models on the ImageNet32 generation task and improves language modeling efficiency on the widely studied enwik8 benchmark.