 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Precise: Adjusting Planning Horizon with Adaptive Subgoal Search
Jun 01, 2022
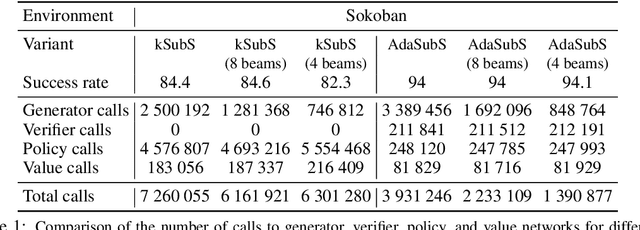
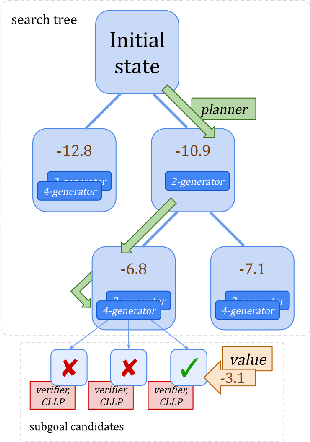
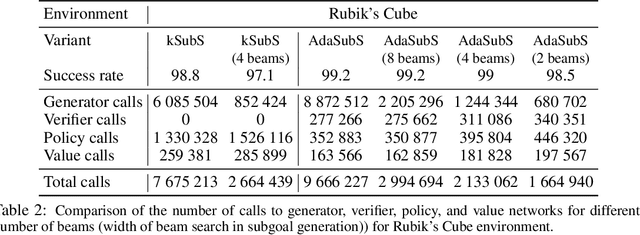
Complex reasoning problems contain states that vary in the computational cost required to determine a good action plan. Taking advantage of this property, we propose Adaptive Subgoal Search (AdaSubS), a search method that adaptively adjusts the planning horizon. To this end, AdaSubS generates diverse sets of subgoals at different distances. A verification mechanism is employed to filter out unreachable subgoals swiftly and thus allowing to focus on feasible further subgoals. In this way, AdaSubS benefits from the efficiency of planning with longer subgoals and the fine control with the shorter ones. We show that AdaSubS significantly surpasses hierarchical planning algorithms on three complex reasoning tasks: Sokoban, the Rubik's Cube, and inequality proving benchmark INT, setting new state-of-the-art on INT.
Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers
May 22, 2022

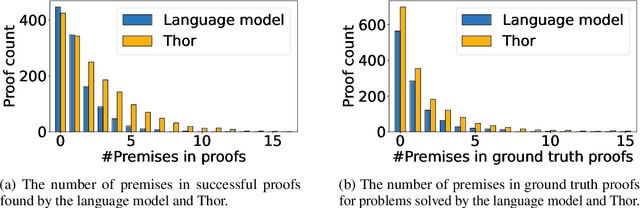

In theorem proving, the task of selecting useful premises from a large library to unlock the proof of a given conjecture is crucially important. This presents a challenge for all theorem provers, especially the ones based on language models, due to their relative inability to reason over huge volumes of premises in text form. This paper introduces Thor, a framework integrating language models and automated theorem provers to overcome this difficulty. In Thor, a class of methods called hammers that leverage the power of automated theorem provers are used for premise selection, while all other tasks are designated to language models. Thor increases a language model's success rate on the PISA dataset from $39\%$ to $57\%$, while solving $8.2\%$ of problems neither language models nor automated theorem provers are able to solve on their own. Furthermore, with a significantly smaller computational budget, Thor can achieve a success rate on the MiniF2F dataset that is on par with the best existing methods. Thor can be instantiated for the majority of popular interactive theorem provers via a straightforward protocol we provide.
Subgoal Search For Complex Reasoning Tasks
Aug 25, 2021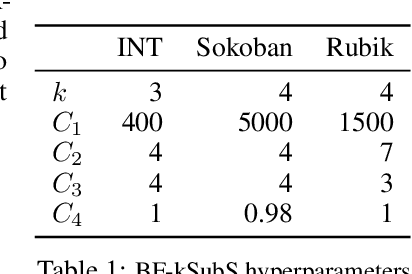
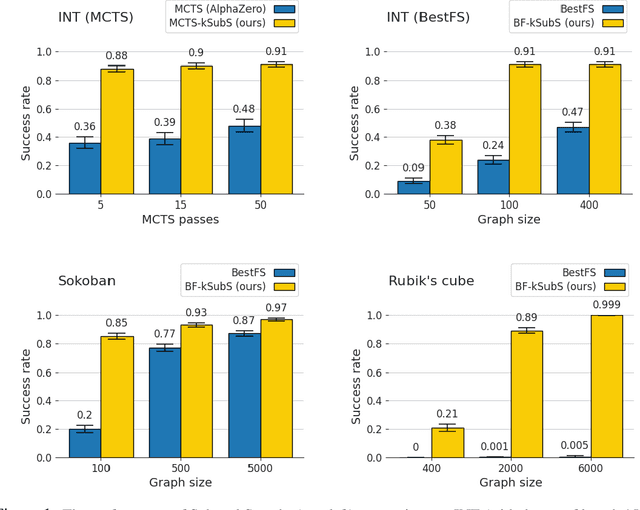
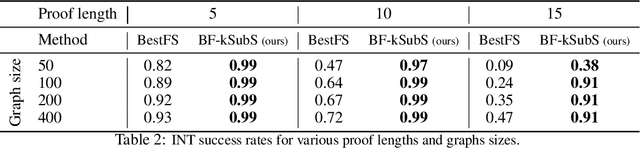
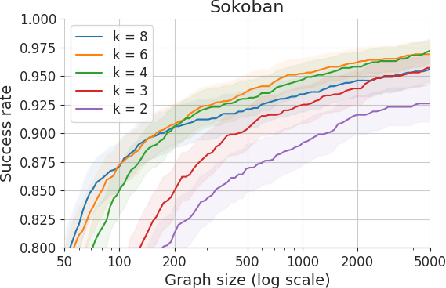
Humans excel in solving complex reasoning tasks through a mental process of moving from one idea to a related one. Inspired by this, we propose Subgoal Search (kSubS) method. Its key component is a learned subgoal generator that produces a diversity of subgoals that are both achievable and closer to the solution. Using subgoals reduces the search space and induces a high-level search graph suitable for efficient planning. In this paper, we implement kSubS using a transformer-based subgoal module coupled with the classical best-first search framework. We show that a simple approach of generating $k$-th step ahead subgoals is surprisingly efficient on three challenging domains: two popular puzzle games, Sokoban and the Rubik's Cube, and an inequality proving benchmark INT. kSubS achieves strong results including state-of-the-art on INT within a modest computational budget.
Uncertainty-sensitive Learning and Planning with Ensembles
Jan 01, 2020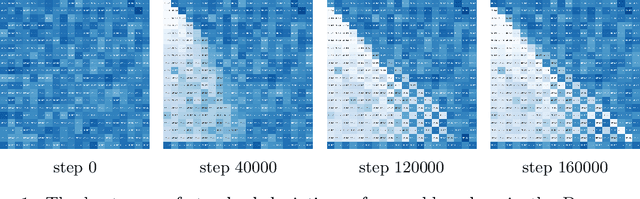

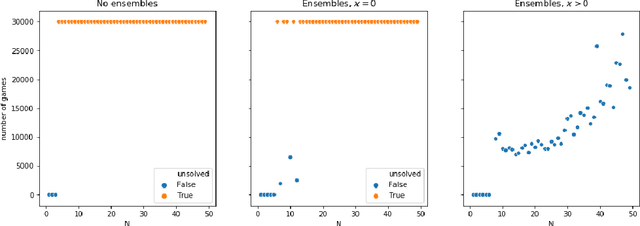

We propose a reinforcement learning framework for discrete environments in which an agent makes both strategic and tactical decisions. The former manifests itself through the use of value function, while the latter is powered by a tree search planner. These tools complement each other. The planning module performs a local \textit{what-if} analysis, which allows to avoid tactical pitfalls and boost backups of the value function. The value function, being global in nature, compensates for inherent locality of the planner. In order to further solidify this synergy, we introduce an exploration mechanism with two distinctive components: uncertainty modelling and risk measurement. To model the uncertainty we use value function ensembles, and to reflect risk we use propose several functionals that summarize the implied by the ensemble. We show that our method performs well on hard exploration environments: Deep-sea, toy Montezuma's Revenge, and Sokoban. In all the cases, we obtain speed-up in learning and boost in performance.
Model-Based Reinforcement Learning for Atari
Mar 05, 2019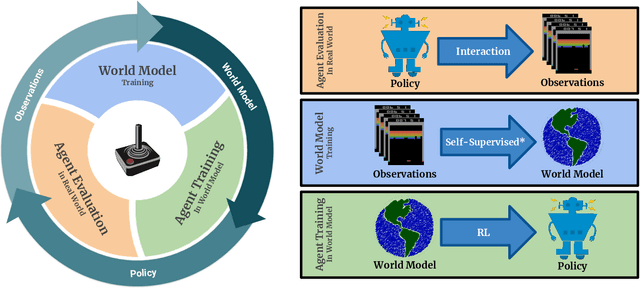
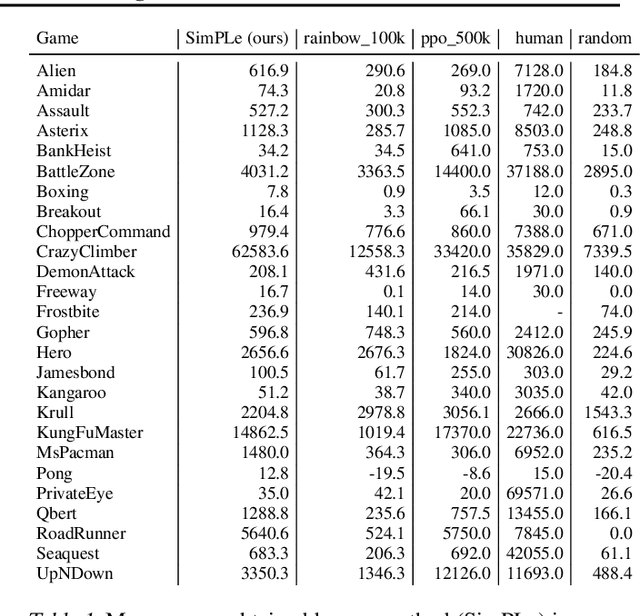
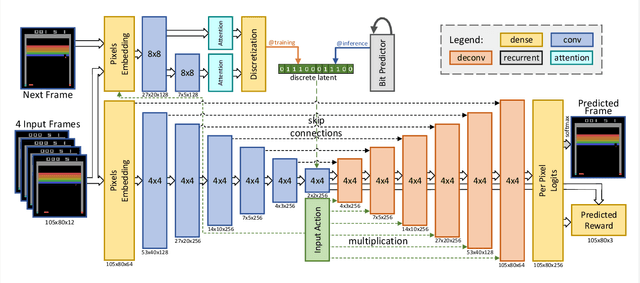
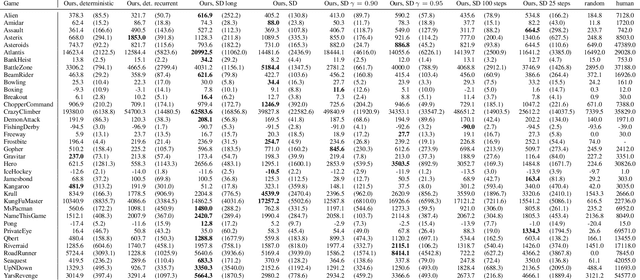
Model-free reinforcement learning (RL) can be used to learn effective policies for complex tasks, such as Atari games, even from image observations. However, this typically requires very large amounts of interaction -- substantially more, in fact, than a human would need to learn the same games. How can people learn so quickly? Part of the answer may be that people can learn how the game works and predict which actions will lead to desirable outcomes. In this paper, we explore how video prediction models can similarly enable agents to solve Atari games with orders of magnitude fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting. Our experiments evaluate SimPLe on a range of Atari games and achieve competitive results with only 100K interactions between the agent and the environment (400K frames), which corresponds to about two hours of real-time play.