 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgetsGT: Stochastic Time Series Modeling With Transformer
Mar 15, 2024Time series methods are of fundamental importance in virtually any field of science that deals with temporally structured data. Recently, there has been a surge of deterministic transformer models with time series-specific architectural biases. In this paper, we go in a different direction by introducing tsGT, a stochastic time series model built on a general-purpose transformer architecture. We focus on using a well-known and theoretically justified rolling window backtesting and evaluation protocol. We show that tsGT outperforms the state-of-the-art models on MAD and RMSE, and surpasses its stochastic peers on QL and CRPS, on four commonly used datasets. We complement these results with a detailed analysis of tsGT's ability to model the data distribution and predict marginal quantile values.
Molecule-Edit Templates for Efficient and Accurate Retrosynthesis Prediction
Oct 11, 2023
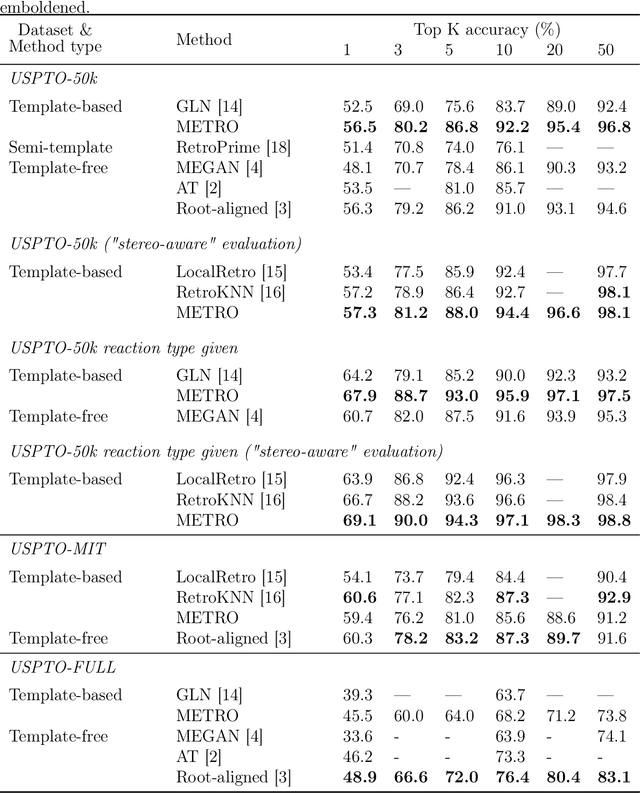
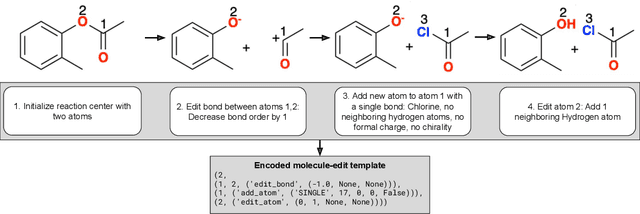

Retrosynthesis involves determining a sequence of reactions to synthesize complex molecules from simpler precursors. As this poses a challenge in organic chemistry, machine learning has offered solutions, particularly for predicting possible reaction substrates for a given target molecule. These solutions mainly fall into template-based and template-free categories. The former is efficient but relies on a vast set of predefined reaction patterns, while the latter, though more flexible, can be computationally intensive and less interpretable. To address these issues, we introduce METRO (Molecule-Edit Templates for RetrOsynthesis), a machine-learning model that predicts reactions using minimal templates - simplified reaction patterns capturing only essential molecular changes - reducing computational overhead and achieving state-of-the-art results on standard benchmarks.
Robust and Efficient Planning using Adaptive Entropy Tree Search
Feb 12, 2021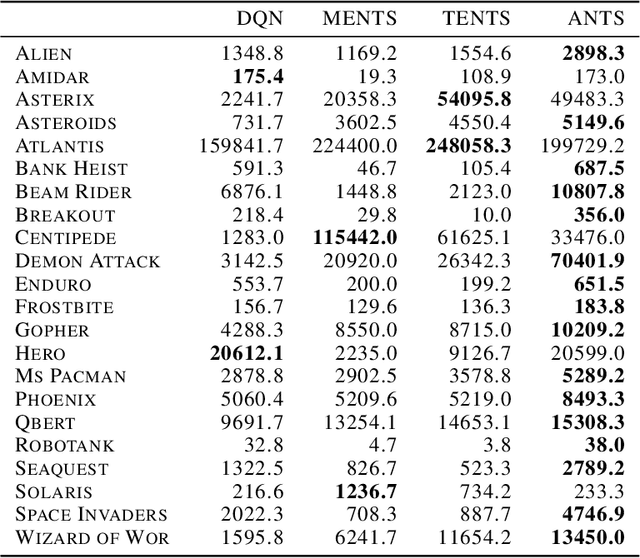
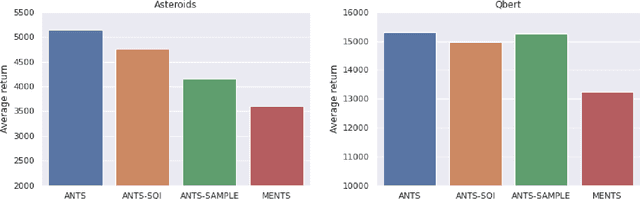
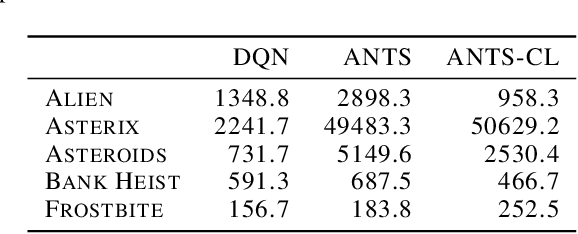
In this paper, we present the Adaptive EntropyTree Search (ANTS) algorithm. ANTS builds on recent successes of maximum entropy planning while mitigating its arguably major drawback - sensitivity to the temperature setting. We endow ANTS with a mechanism, which adapts the temperature to match a given range of action selection entropy in the nodes of the planning tree. With this mechanism, the ANTS planner enjoys remarkable hyper-parameter robustness, achieves high scores on the Atari benchmark, and is a capable component of a planning-learning loop akin to AlphaZero. We believe that all these features make ANTS a compelling choice for a general planner for complex tasks.
Q-Value Weighted Regression: Reinforcement Learning with Limited Data
Feb 12, 2021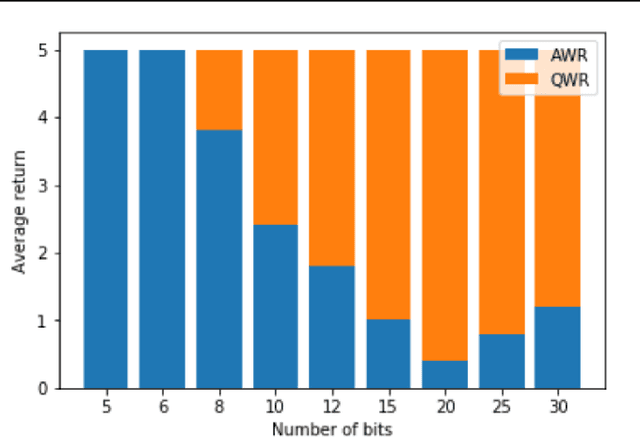
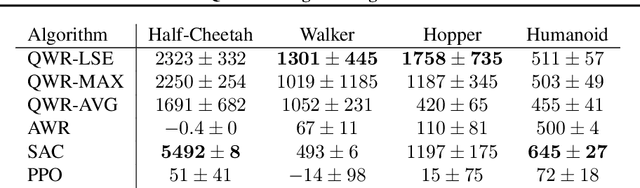
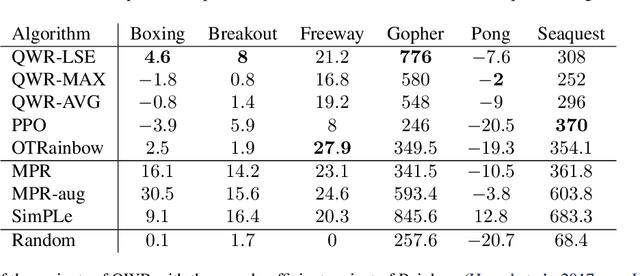
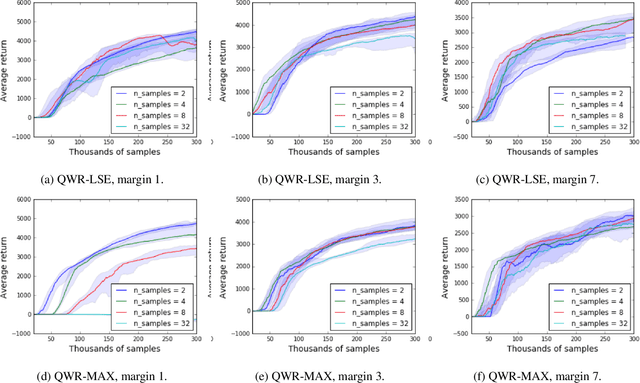
Sample efficiency and performance in the offline setting have emerged as significant challenges of deep reinforcement learning. We introduce Q-Value Weighted Regression (QWR), a simple RL algorithm that excels in these aspects. QWR is an extension of Advantage Weighted Regression (AWR), an off-policy actor-critic algorithm that performs very well on continuous control tasks, also in the offline setting, but has low sample efficiency and struggles with high-dimensional observation spaces. We perform an analysis of AWR that explains its shortcomings and use these insights to motivate QWR. We show experimentally that QWR matches the state-of-the-art algorithms both on tasks with continuous and discrete actions. In particular, QWR yields results on par with SAC on the MuJoCo suite and - with the same set of hyperparameters - yields results on par with a highly tuned Rainbow implementation on a set of Atari games. We also verify that QWR performs well in the offline RL setting.
Uncertainty-sensitive Learning and Planning with Ensembles
Jan 01, 2020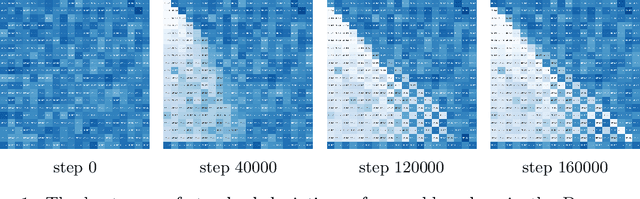

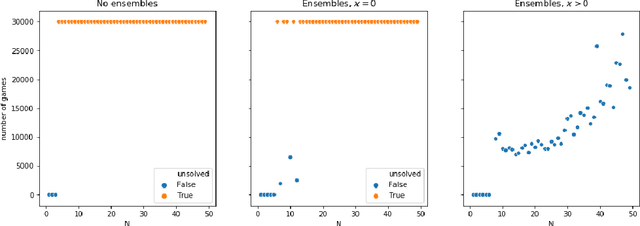

We propose a reinforcement learning framework for discrete environments in which an agent makes both strategic and tactical decisions. The former manifests itself through the use of value function, while the latter is powered by a tree search planner. These tools complement each other. The planning module performs a local \textit{what-if} analysis, which allows to avoid tactical pitfalls and boost backups of the value function. The value function, being global in nature, compensates for inherent locality of the planner. In order to further solidify this synergy, we introduce an exploration mechanism with two distinctive components: uncertainty modelling and risk measurement. To model the uncertainty we use value function ensembles, and to reflect risk we use propose several functionals that summarize the implied by the ensemble. We show that our method performs well on hard exploration environments: Deep-sea, toy Montezuma's Revenge, and Sokoban. In all the cases, we obtain speed-up in learning and boost in performance.
Model-Based Reinforcement Learning for Atari
Mar 05, 2019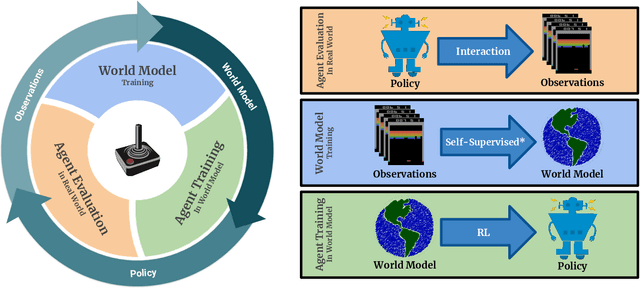
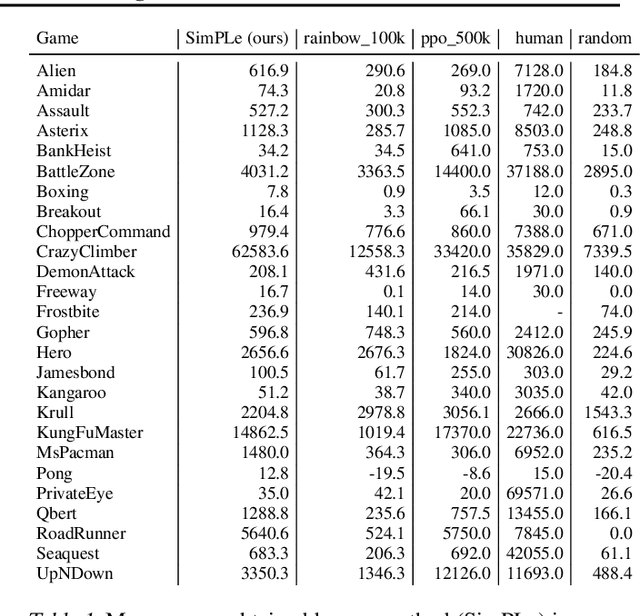
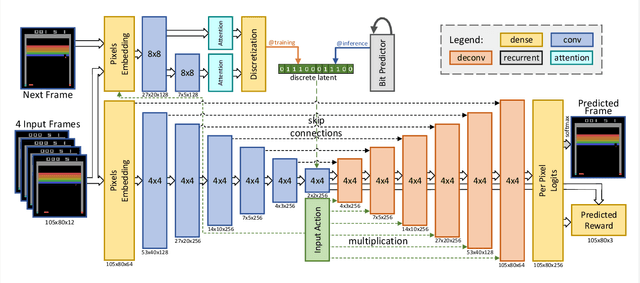
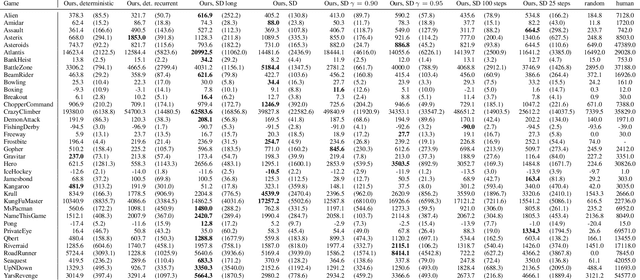
Model-free reinforcement learning (RL) can be used to learn effective policies for complex tasks, such as Atari games, even from image observations. However, this typically requires very large amounts of interaction -- substantially more, in fact, than a human would need to learn the same games. How can people learn so quickly? Part of the answer may be that people can learn how the game works and predict which actions will lead to desirable outcomes. In this paper, we explore how video prediction models can similarly enable agents to solve Atari games with orders of magnitude fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting. Our experiments evaluate SimPLe on a range of Atari games and achieve competitive results with only 100K interactions between the agent and the environment (400K frames), which corresponds to about two hours of real-time play.