 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBALROG: Benchmarking Agentic LLM and VLM Reasoning On Games
Nov 20, 2024



Large Language Models (LLMs) and Vision Language Models (VLMs) possess extensive knowledge and exhibit promising reasoning abilities; however, they still struggle to perform well in complex, dynamic environments. Real-world tasks require handling intricate interactions, advanced spatial reasoning, long-term planning, and continuous exploration of new strategies-areas in which we lack effective methodologies for comprehensively evaluating these capabilities. To address this gap, we introduce BALROG, a novel benchmark designed to assess the agentic capabilities of LLMs and VLMs through a diverse set of challenging games. Our benchmark incorporates a range of existing reinforcement learning environments with varying levels of difficulty, including tasks that are solvable by non-expert humans in seconds to extremely challenging ones that may take years to master (e.g., the NetHack Learning Environment). We devise fine-grained metrics to measure performance and conduct an extensive evaluation of several popular open-source and closed-source LLMs and VLMs. Our findings indicate that while current models achieve partial success in the easier games, they struggle significantly with more challenging tasks. Notably, we observe severe deficiencies in vision-based decision-making, as models perform worse when visual representations of the environments are provided. We release BALROG as an open and user-friendly benchmark to facilitate future research and development in the agentic community.
There and Back Again: On the relation between noises, images, and their inversions in diffusion models
Oct 31, 2024Denoising Diffusion Probabilistic Models (DDPMs) achieve state-of-the-art performance in synthesizing new images from random noise, but they lack meaningful latent space that encodes data into features. Recent DDPM-based editing techniques try to mitigate this issue by inverting images back to their approximated staring noise. In this work, we study the relation between the initial Gaussian noise, the samples generated from it, and their corresponding latent encodings obtained through the inversion procedure. First, we interpret their spatial distance relations to show the inaccuracy of the DDIM inversion technique by localizing latent representations manifold between the initial noise and generated samples. Then, we demonstrate the peculiar relation between initial Gaussian noise and its corresponding generations during diffusion training, showing that the high-level features of generated images stabilize rapidly, keeping the spatial distance relationship between noises and generations consistent throughout the training.
Accelerating Goal-Conditioned RL Algorithms and Research
Aug 20, 2024Self-supervision has the potential to transform reinforcement learning (RL), paralleling the breakthroughs it has enabled in other areas of machine learning. While self-supervised learning in other domains aims to find patterns in a fixed dataset, self-supervised goal-conditioned reinforcement learning (GCRL) agents discover new behaviors by learning from the goals achieved during unstructured interaction with the environment. However, these methods have failed to see similar success, both due to a lack of data from slow environments as well as a lack of stable algorithms. We take a step toward addressing both of these issues by releasing a high-performance codebase and benchmark JaxGCRL for self-supervised GCRL, enabling researchers to train agents for millions of environment steps in minutes on a single GPU. The key to this performance is a combination of GPU-accelerated environments and a stable, batched version of the contrastive reinforcement learning algorithm, based on an infoNCE objective, that effectively makes use of this increased data throughput. With this approach, we provide a foundation for future research in self-supervised GCRL, enabling researchers to quickly iterate on new ideas and evaluate them in a diverse set of challenging environments. Website + Code: https://github.com/MichalBortkiewicz/JaxGCRL
RoboMorph: Evolving Robot Morphology using Large Language Models
Jul 11, 2024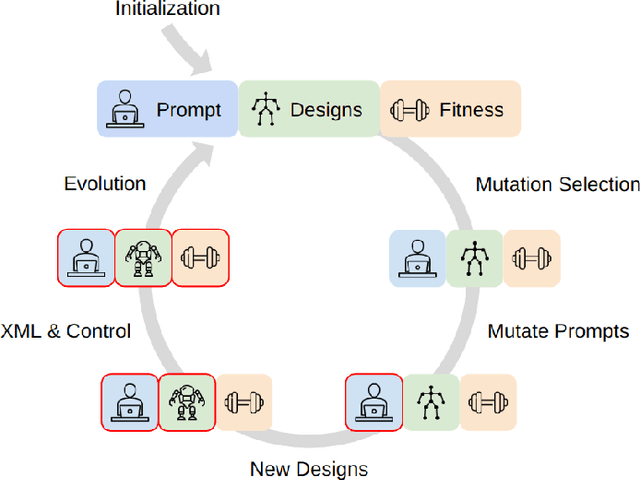
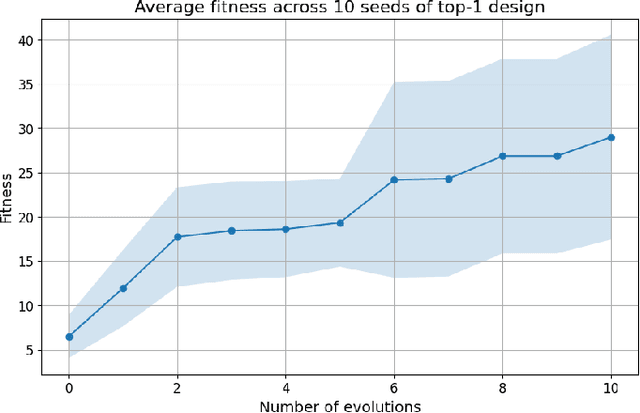
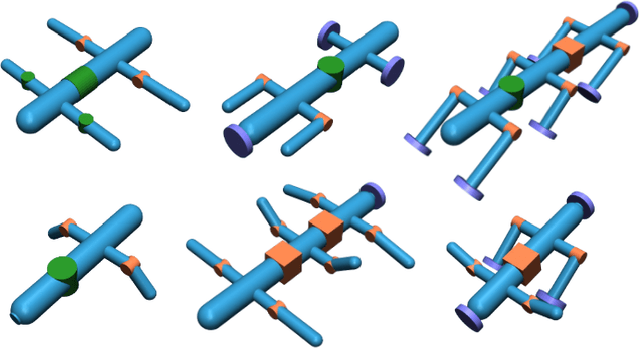
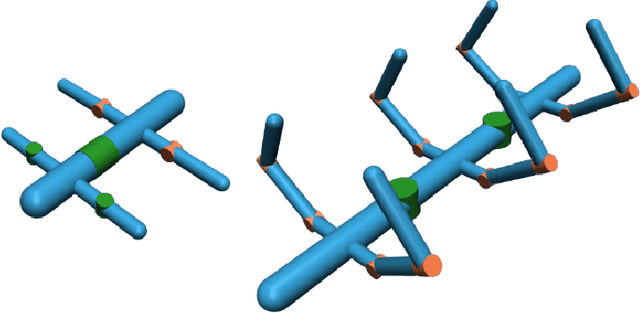
We introduce RoboMorph, an automated approach for generating and optimizing modular robot designs using large language models (LLMs) and evolutionary algorithms. In this framework, we represent each robot design as a grammar and leverage the capabilities of LLMs to navigate the extensive robot design space, which is traditionally time-consuming and computationally demanding. By integrating automatic prompt design and a reinforcement learning based control algorithm, RoboMorph iteratively improves robot designs through feedback loops. Our experimental results demonstrate that RoboMorph can successfully generate nontrivial robots that are optimized for a single terrain while showcasing improvements in morphology over successive evolutions. Our approach demonstrates the potential of using LLMs for data-driven and modular robot design, providing a promising methodology that can be extended to other domains with similar design frameworks.
What Matters in Hierarchical Search for Combinatorial Reasoning Problems?
Jun 05, 2024Efficiently tackling combinatorial reasoning problems, particularly the notorious NP-hard tasks, remains a significant challenge for AI research. Recent efforts have sought to enhance planning by incorporating hierarchical high-level search strategies, known as subgoal methods. While promising, their performance against traditional low-level planners is inconsistent, raising questions about their application contexts. In this study, we conduct an in-depth exploration of subgoal-planning methods for combinatorial reasoning. We identify the attributes pivotal for leveraging the advantages of high-level search: hard-to-learn value functions, complex action spaces, presence of dead ends in the environment, or using data collected from diverse experts. We propose a consistent evaluation methodology to achieve meaningful comparisons between methods and reevaluate the state-of-the-art algorithms.
tsGT: Stochastic Time Series Modeling With Transformer
Mar 15, 2024Time series methods are of fundamental importance in virtually any field of science that deals with temporally structured data. Recently, there has been a surge of deterministic transformer models with time series-specific architectural biases. In this paper, we go in a different direction by introducing tsGT, a stochastic time series model built on a general-purpose transformer architecture. We focus on using a well-known and theoretically justified rolling window backtesting and evaluation protocol. We show that tsGT outperforms the state-of-the-art models on MAD and RMSE, and surpasses its stochastic peers on QL and CRPS, on four commonly used datasets. We complement these results with a detailed analysis of tsGT's ability to model the data distribution and predict marginal quantile values.
GUIDE: Guidance-based Incremental Learning with Diffusion Models
Mar 06, 2024We introduce GUIDE, a novel continual learning approach that directs diffusion models to rehearse samples at risk of being forgotten. Existing generative strategies combat catastrophic forgetting by randomly sampling rehearsal examples from a generative model. Such an approach contradicts buffer-based approaches where sampling strategy plays an important role. We propose to bridge this gap by integrating diffusion models with classifier guidance techniques to produce rehearsal examples specifically targeting information forgotten by a continuously trained model. This approach enables the generation of samples from preceding task distributions, which are more likely to be misclassified in the context of recently encountered classes. Our experimental results show that GUIDE significantly reduces catastrophic forgetting, outperforming conventional random sampling approaches and surpassing recent state-of-the-art methods in continual learning with generative replay.
Fine-tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem
Feb 05, 2024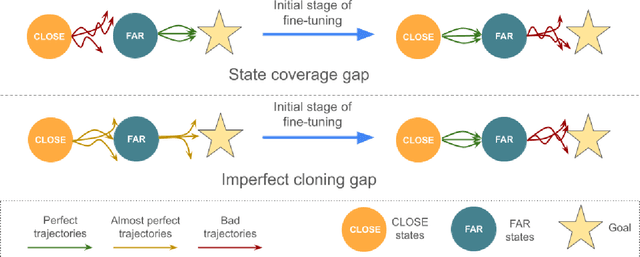
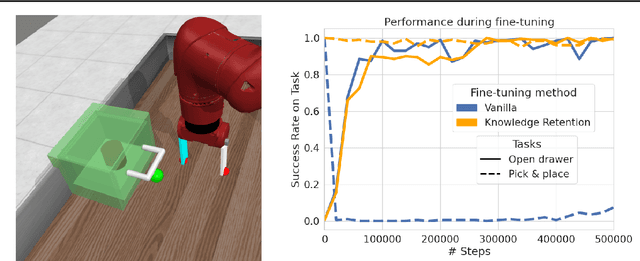
Fine-tuning is a widespread technique that allows practitioners to transfer pre-trained capabilities, as recently showcased by the successful applications of foundation models. However, fine-tuning reinforcement learning (RL) models remains a challenge. This work conceptualizes one specific cause of poor transfer, accentuated in the RL setting by the interplay between actions and observations: forgetting of pre-trained capabilities. Namely, a model deteriorates on the state subspace of the downstream task not visited in the initial phase of fine-tuning, on which the model behaved well due to pre-training. This way, we lose the anticipated transfer benefits. We identify conditions when this problem occurs, showing that it is common and, in many cases, catastrophic. Through a detailed empirical analysis of the challenging NetHack and Montezuma's Revenge environments, we show that standard knowledge retention techniques mitigate the problem and thus allow us to take full advantage of the pre-trained capabilities. In particular, in NetHack, we achieve a new state-of-the-art for neural models, improving the previous best score from $5$K to over $10$K points in the Human Monk scenario.
Structured Packing in LLM Training Improves Long Context Utilization
Jan 02, 2024Recent advances in long-context Large Language Models (LCLMs) have generated significant interest, especially in applications such as querying scientific research papers. However, their potential is often limited by inadequate context utilization. We identify the absence of long-range semantic dependencies in typical training data as a primary hindrance. To address this, we delve into the benefits of frequently incorporating related documents into training inputs. Using the inherent directory structure of code data as a source of training examples, we demonstrate improvements in perplexity, even for tasks unrelated to coding. Building on these findings, but with a broader focus, we introduce Structured Packing for Long Context (SPLiCe). SPLiCe is an innovative method for creating training examples by using a retrieval method to collate the most mutually relevant documents into a single training context. Our results indicate that \method{} enhances model performance and can be used to train large models to utilize long contexts better. We validate our results by training a large $3$B model, showing both perplexity improvements and better long-context performance on downstream tasks.
Magnushammer: A Transformer-based Approach to Premise Selection
Mar 08, 2023Premise selection is a fundamental problem of automated theorem proving. Previous works often use intricate symbolic methods, rely on domain knowledge, and require significant engineering effort to solve this task. In this work, we show that Magnushammer, a neural transformer-based approach, can outperform traditional symbolic systems by a large margin. Tested on the PISA benchmark, Magnushammer achieves $59.5\%$ proof rate compared to a $38.3\%$ proof rate of Sledgehammer, the most mature and popular symbolic-based solver. Furthermore, by combining Magnushammer with a neural formal prover based on a language model, we significantly improve the previous state-of-the-art proof rate from $57.0\%$ to $71.0\%$.