 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Hierarchical Search for Combinatorial Reasoning Problems?
Jun 05, 2024Efficiently tackling combinatorial reasoning problems, particularly the notorious NP-hard tasks, remains a significant challenge for AI research. Recent efforts have sought to enhance planning by incorporating hierarchical high-level search strategies, known as subgoal methods. While promising, their performance against traditional low-level planners is inconsistent, raising questions about their application contexts. In this study, we conduct an in-depth exploration of subgoal-planning methods for combinatorial reasoning. We identify the attributes pivotal for leveraging the advantages of high-level search: hard-to-learn value functions, complex action spaces, presence of dead ends in the environment, or using data collected from diverse experts. We propose a consistent evaluation methodology to achieve meaningful comparisons between methods and reevaluate the state-of-the-art algorithms.
Fast and Precise: Adjusting Planning Horizon with Adaptive Subgoal Search
Jun 01, 2022
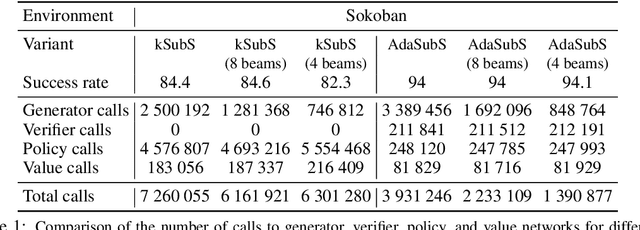
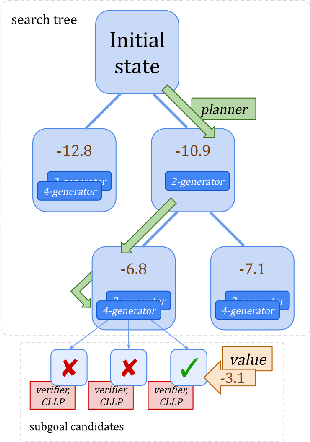
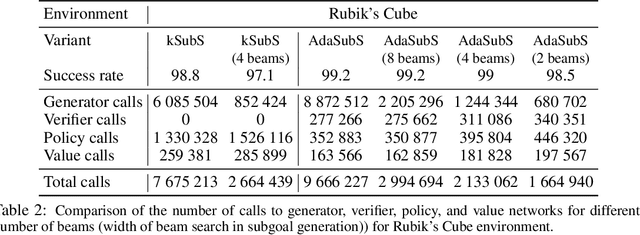
Complex reasoning problems contain states that vary in the computational cost required to determine a good action plan. Taking advantage of this property, we propose Adaptive Subgoal Search (AdaSubS), a search method that adaptively adjusts the planning horizon. To this end, AdaSubS generates diverse sets of subgoals at different distances. A verification mechanism is employed to filter out unreachable subgoals swiftly and thus allowing to focus on feasible further subgoals. In this way, AdaSubS benefits from the efficiency of planning with longer subgoals and the fine control with the shorter ones. We show that AdaSubS significantly surpasses hierarchical planning algorithms on three complex reasoning tasks: Sokoban, the Rubik's Cube, and inequality proving benchmark INT, setting new state-of-the-art on INT.
Hierarchical Transformers Are More Efficient Language Models
Oct 26, 2021

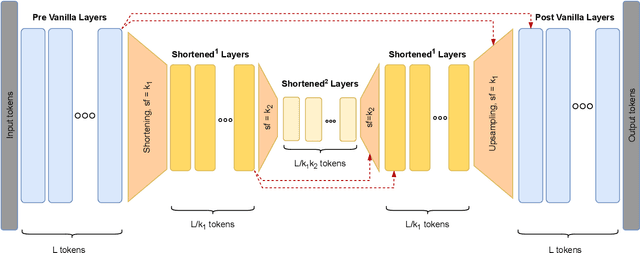

Transformer models yield impressive results on many NLP and sequence modeling tasks. Remarkably, Transformers can handle long sequences which allows them to produce long coherent outputs: full paragraphs produced by GPT-3 or well-structured images produced by DALL-E. These large language models are impressive but also very inefficient and costly, which limits their applications and accessibility. We postulate that having an explicit hierarchical architecture is the key to Transformers that efficiently handle long sequences. To verify this claim, we first study different ways to downsample and upsample activations in Transformers so as to make them hierarchical. We use the best performing upsampling and downsampling layers to create Hourglass - a hierarchical Transformer language model. Hourglass improves upon the Transformer baseline given the same amount of computation and can yield the same results as Transformers more efficiently. In particular, Hourglass sets new state-of-the-art for Transformer models on the ImageNet32 generation task and improves language modeling efficiency on the widely studied enwik8 benchmark.