 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehind Closed Words: Creating and Investigating the forePLay Annotated Dataset for Polish Erotic Discourse
Dec 23, 2024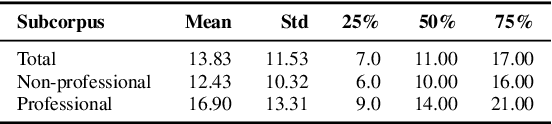
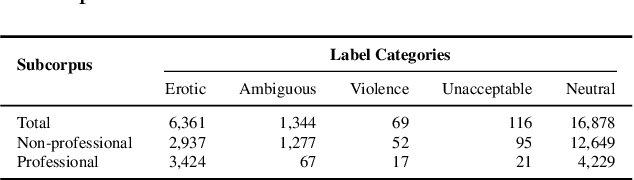

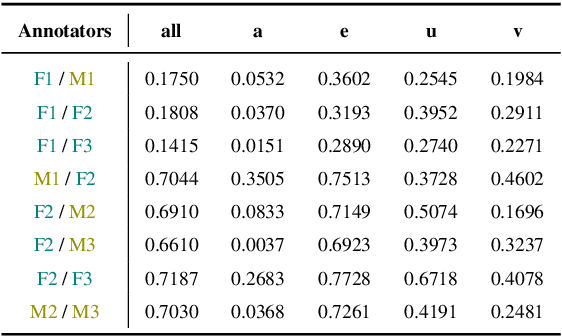
The surge in online content has created an urgent demand for robust detection systems, especially in non-English contexts where current tools demonstrate significant limitations. We present forePLay, a novel Polish language dataset for erotic content detection, featuring over 24k annotated sentences with a multidimensional taxonomy encompassing ambiguity, violence, and social unacceptability dimensions. Our comprehensive evaluation demonstrates that specialized Polish language models achieve superior performance compared to multilingual alternatives, with transformer-based architectures showing particular strength in handling imbalanced categories. The dataset and accompanying analysis establish essential frameworks for developing linguistically-aware content moderation systems, while highlighting critical considerations for extending such capabilities to morphologically complex languages.
When All Options Are Wrong: Evaluating Large Language Model Robustness with Incorrect Multiple-Choice Options
Aug 27, 2024



This paper examines the zero-shot ability of Large Language Models (LLMs) to detect multiple-choice questions with no correct answer, a crucial aspect of educational assessment quality. We explore this ability not only as a measure of subject matter knowledge but also as an indicator of critical thinking within LLMs. Our experiments, utilizing a range of LLMs on diverse questions, highlight the significant performance gap between questions with a single correct answer and those without. Llama-3.1-405B stands out by successfully identifying the lack of a valid answer in many instances. These findings suggest that LLMs should prioritize critical thinking over blind instruction following and caution against their use in educational settings where questions with incorrect answers might lead to inaccurate evaluations. This research sets a benchmark for assessing critical thinking in LLMs and emphasizes the need for ongoing model alignment to ensure genuine user comprehension and assistance.
What Matters in Hierarchical Search for Combinatorial Reasoning Problems?
Jun 05, 2024Efficiently tackling combinatorial reasoning problems, particularly the notorious NP-hard tasks, remains a significant challenge for AI research. Recent efforts have sought to enhance planning by incorporating hierarchical high-level search strategies, known as subgoal methods. While promising, their performance against traditional low-level planners is inconsistent, raising questions about their application contexts. In this study, we conduct an in-depth exploration of subgoal-planning methods for combinatorial reasoning. We identify the attributes pivotal for leveraging the advantages of high-level search: hard-to-learn value functions, complex action spaces, presence of dead ends in the environment, or using data collected from diverse experts. We propose a consistent evaluation methodology to achieve meaningful comparisons between methods and reevaluate the state-of-the-art algorithms.
Big Tech influence over AI research revisited: memetic analysis of attribution of ideas to affiliation
Dec 20, 2023



There exists a growing discourse around the domination of Big Tech on the landscape of artificial intelligence (AI) research, yet our comprehension of this phenomenon remains cursory. This paper aims to broaden and deepen our understanding of Big Tech's reach and power within AI research. It highlights the dominance not merely in terms of sheer publication volume but rather in the propagation of new ideas or \textit{memes}. Current studies often oversimplify the concept of influence to the share of affiliations in academic papers, typically sourced from limited databases such as arXiv or specific academic conferences. The main goal of this paper is to unravel the specific nuances of such influence, determining which AI ideas are predominantly driven by Big Tech entities. By employing network and memetic analysis on AI-oriented paper abstracts and their citation network, we are able to grasp a deeper insight into this phenomenon. By utilizing two databases: OpenAlex and S2ORC, we are able to perform such analysis on a much bigger scale than previous attempts. Our findings suggest, that while Big Tech-affiliated papers are disproportionately more cited in some areas, the most cited papers are those affiliated with both Big Tech and Academia. Focusing on the most contagious memes, their attribution to specific affiliation groups (Big Tech, Academia, mixed affiliation) seems to be equally distributed between those three groups. This suggests that the notion of Big Tech domination over AI research is oversimplified in the discourse. Ultimately, this more nuanced understanding of Big Tech's and Academia's influence could inform a more symbiotic alliance between these stakeholders which would better serve the dual goals of societal welfare and the scientific integrity of AI research.
Towards Harmful Erotic Content Detection through Coreference-Driven Contextual Analysis
Oct 22, 2023


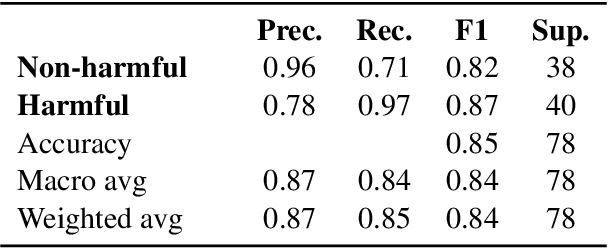
Adult content detection still poses a great challenge for automation. Existing classifiers primarily focus on distinguishing between erotic and non-erotic texts. However, they often need more nuance in assessing the potential harm. Unfortunately, the content of this nature falls beyond the reach of generative models due to its potentially harmful nature. Ethical restrictions prohibit large language models (LLMs) from analyzing and classifying harmful erotics, let alone generating them to create synthetic datasets for other neural models. In such instances where data is scarce and challenging, a thorough analysis of the structure of such texts rather than a large model may offer a viable solution. Especially given that harmful erotic narratives, despite appearing similar to harmless ones, usually reveal their harmful nature first through contextual information hidden in the non-sexual parts of the narrative. This paper introduces a hybrid neural and rule-based context-aware system that leverages coreference resolution to identify harmful contextual cues in erotic content. Collaborating with professional moderators, we compiled a dataset and developed a classifier capable of distinguishing harmful from non-harmful erotic content. Our hybrid model, tested on Polish text, demonstrates a promising accuracy of 84% and a recall of 80%. Models based on RoBERTa and Longformer without explicit usage of coreference chains achieved significantly weaker results, underscoring the importance of coreference resolution in detecting such nuanced content as harmful erotics. This approach also offers the potential for enhanced visual explainability, supporting moderators in evaluating predictions and taking necessary actions to address harmful content.
BAN-PL: a Novel Polish Dataset of Banned Harmful and Offensive Content from Wykop.pl web service
Aug 23, 2023
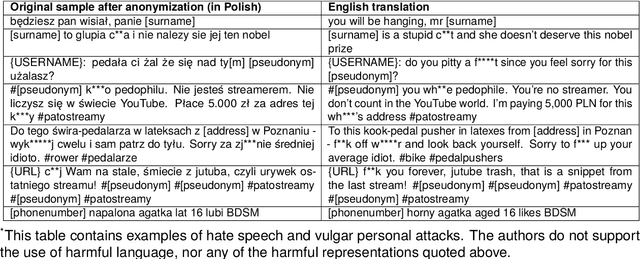


Advances in automated detection of offensive language online, including hate speech and cyberbullying, require improved access to publicly available datasets comprising social media content. In this paper, we introduce BAN-PL, the first open dataset in the Polish language that encompasses texts flagged as harmful and subsequently removed by professional moderators. The dataset encompasses a total of 691,662 pieces of content from a popular social networking service, Wykop, often referred to as the "Polish Reddit", including both posts and comments, and is evenly distributed into two distinct classes: "harmful" and "neutral". We provide a comprehensive description of the data collection and preprocessing procedures, as well as highlight the linguistic specificity of the data. The BAN-PL dataset, along with advanced preprocessing scripts for, i.a., unmasking profanities, will be publicly available.
Deep Dive into the Language of International Relations: NLP-based Analysis of UNESCO's Summary Records
Aug 01, 2023



Cultural heritage is an arena of international relations that interests all states worldwide. The inscription process on the UNESCO World Heritage List and the UNESCO Representative List of the Intangible Cultural Heritage of Humanity often leads to tensions and conflicts among states. This research addresses these challenges by developing automatic tools that provide valuable insights into the decision-making processes regarding inscriptions to the two lists mentioned above. We propose innovative topic modelling and tension detection methods based on UNESCO's summary records. Our analysis achieved a commendable accuracy rate of 72% in identifying tensions. Furthermore, we have developed an application tailored for diplomats, lawyers, political scientists, and international relations researchers that facilitates the efficient search of paragraphs from selected documents and statements from specific speakers about chosen topics. This application is a valuable resource for enhancing the understanding of complex decision-making dynamics within international heritage inscription procedures.
HADES: Homologous Automated Document Exploration and Summarization
Feb 25, 2023



This paper introduces HADES, a novel tool for automatic comparative documents with similar structures. HADES is designed to streamline the work of professionals dealing with large volumes of documents, such as policy documents, legal acts, and scientific papers. The tool employs a multi-step pipeline that begins with processing PDF documents using topic modeling, summarization, and analysis of the most important words for each topic. The process concludes with an interactive web app with visualizations that facilitate the comparison of the documents. HADES has the potential to significantly improve the productivity of professionals dealing with high volumes of documents, reducing the time and effort required to complete tasks related to comparative document analysis. Our package is publically available on GitHub.
Climate Policy Tracker: Pipeline for automated analysis of public climate policies
Nov 10, 2022



The number of standardized policy documents regarding climate policy and their publication frequency is significantly increasing. The documents are long and tedious for manual analysis, especially for policy experts, lawmakers, and citizens who lack access or domain expertise to utilize data analytics tools. Potential consequences of such a situation include reduced citizen governance and involvement in climate policies and an overall surge in analytics costs, rendering less accessibility for the public. In this work, we use a Latent Dirichlet Allocation-based pipeline for the automatic summarization and analysis of 10-years of national energy and climate plans (NECPs) for the period from 2021 to 2030, established by 27 Member States of the European Union. We focus on analyzing policy framing, the language used to describe specific issues, to detect essential nuances in the way governments frame their climate policies and achieve climate goals. The methods leverage topic modeling and clustering for the comparative analysis of policy documents across different countries. It allows for easier integration in potential user-friendly applications for the development of theories and processes of climate policy. This would further lead to better citizen governance and engagement over climate policies and public policy research.